
A server cluster is a group of servers that work together to provide a unified system. Clusters distribute tasks across multiple servers, improving performance and minimizing downtime.
This article will explain what a server cluster is, how it works, the different types of clustering, and the key benefits and challenges of using server clusters.
What Is Server Cluster?
A server cluster is a collection of independent servers that operate as a single system. Each server, called a node, is connected through a network and managed by specialized clustering software. The purpose of clustering is to improve availability, performance, and reliability by pooling resources and distributing workloads.
Clusters are commonly used in environments where uninterrupted access to data and applications is critical. If one node fails, the cluster automatically redirects tasks to other active nodes, reducing the risk of downtime. This redundancy makes clusters a core component of high availability and disaster recovery strategies.
Note: Learn more about redundancy levels in data centers.
How Does Server Cluster Work?
A server cluster operates by connecting multiple servers, or nodes, through a high-speed network and coordinating their activities using clustering software. Each node provides computing power, memory, and storage, which creates a pool of resources that the cluster manages as a single system.
Clustering software monitors the health and status of each node. When a node fails or becomes unresponsive, the software automatically redistributes the workload to the remaining active nodes. This process, known as failover, ensures the continuous availability of applications and services.
Clusters can be configured for specific purposes, such as high availability, load balancing, or a combination of both, depending on the organization's needs.
Note: Learn about the differences between failover and failback, two essential disaster recovery and business continuity mechanisms.
Server Clustering Use Cases
Server clusters are deployed in environments where system reliability, scalability, and performance are critical. Common use cases include:
- Database hosting. Clusters support high transaction volumes and ensure continuous access to databases, thereby facilitating seamless operations. If one node fails, the others continue to maintain database operations without interruption.
- Web hosting. Websites and applications with high traffic rely on clusters to balance requests across multiple servers, which reduces latency and prevents downtime.
- Server virtualization and cloud infrastructure. Clusters pool computing and storage resources, which allows virtual machines and containers to move between nodes with minimal disruption.
- File and storage services. Clusters provide shared storage systems with redundancy to ensure files remain available even if part of the infrastructure fails.
- Enterprise applications. Business-critical tools, such as Enterprise Resource Planning (ERP) and Customer Relationship Management (CRM) systems, often run on clusters to ensure availability and maintain performance under heavy usage.
- Scientific computing and big data. High-performance clusters handle large-scale computations and data processing tasks that exceed the capacity of a single server.
Types of Server Clusters
Server clusters are designed with different configurations depending on workload requirements and fault-tolerance needs. The way nodes communicate and share data defines how the cluster operates and how it responds to failures.
The following sections explain the main types of server clusters.
Single-Quorum Cluster
A single-quorum cluster uses a shared storage device that all nodes can access. The quorum is the minimum number of votes or resources required for the cluster to operate safely. In a single-quorum cluster, the quorum resource, usually a disk, stores cluster configuration data and ensures consistency across nodes. Only one copy of this data exists, and the cluster depends on it to remain operational.
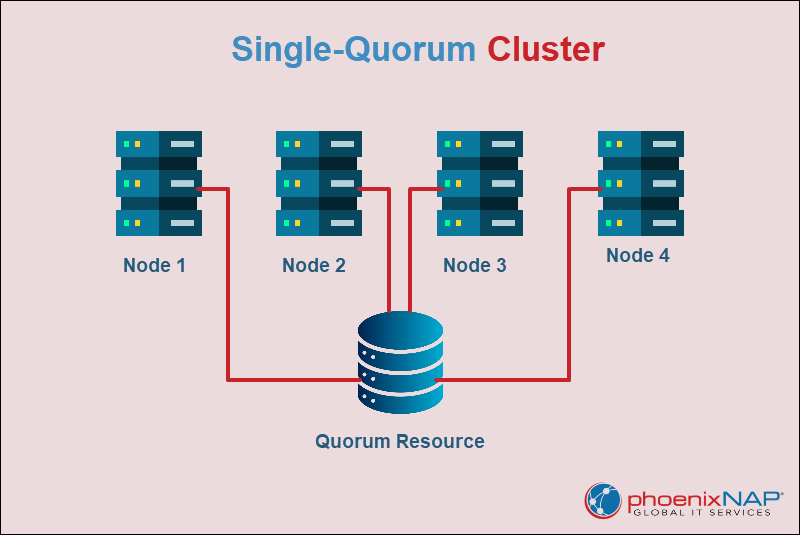
If the quorum disk fails, the entire cluster can go offline, even if the nodes themselves are still functional. For this reason, single-quorum clusters require highly reliable shared storage systems and are less common in modern deployments compared to more resilient clustering models.
Majority-Node Set Cluster
A majority-node set cluster does not rely on a single shared quorum disk. Instead, each node maintains its own local copy of the cluster configuration data. The cluster remains operational as long as more than half of the nodes are online and communicate with each other.
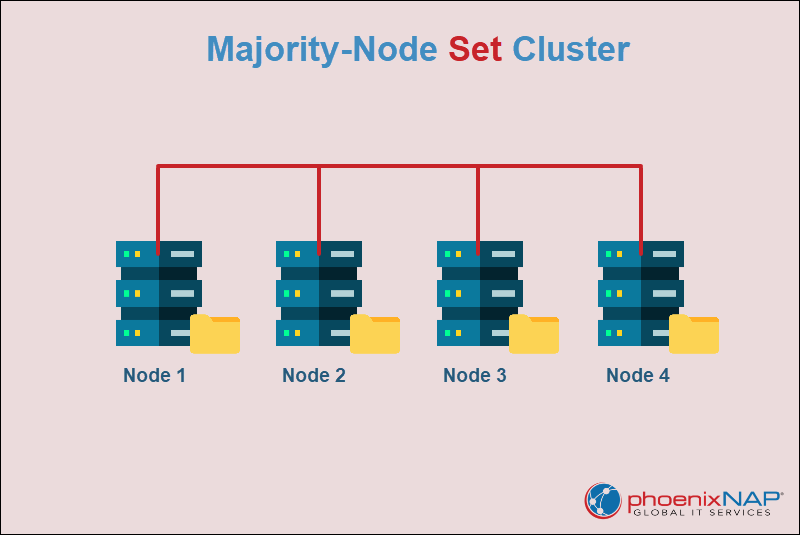
This design eliminates the single point of failure (SPOF) found in single-quorum clusters. The majority of node set clusters are more resilient and are used in modern environments, especially in geographically distributed systems where shared storage is impractical.
Single-Node Cluster
A single-node cluster consists of only one server running clustering software. Since there are no additional nodes, it cannot provide failover or load balancing. The primary purpose of this configuration is testing, development, or demonstration, where simulating a cluster environment is necessary but full redundancy is not required.
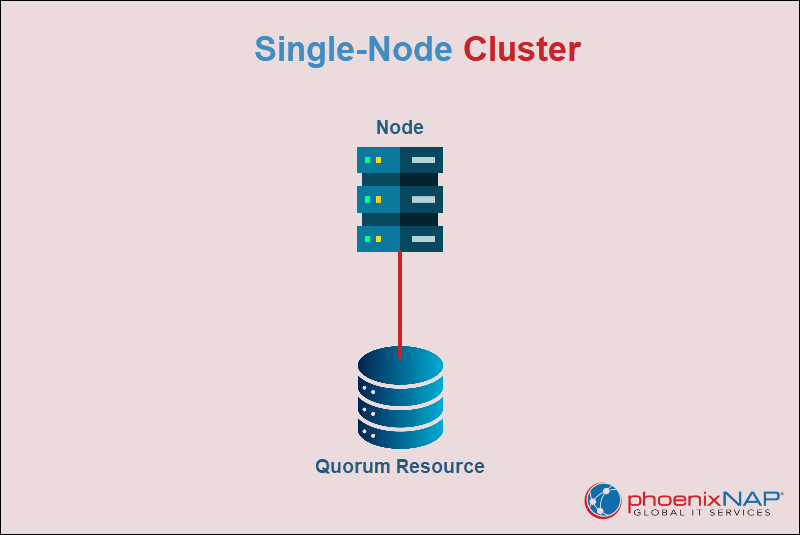
While not suitable for production use, single-node clusters are helpful in evaluating clustering technologies and validating application compatibility before deploying a multi-node setup.
Server Clustering Technologies
Server clusters rely on software and platforms that coordinate nodes, manage workloads, and maintain high availability. These technologies provide practical solutions for deploying clusters in production environments, ensuring applications remain operational and scalable under varying demands.
The following list presents the most common clustering technologies:
- Windows Server Failover Clustering (WSFC). Integrated into Windows Server, WSFC provides high availability for applications, services, and virtual machines. It supports automatic failover and load distribution across multiple nodes.
- Pacemaker with Corosync. An open-source clustering stack used on Linux systems. Pacemaker manages resources and orchestrates failover, while Corosync handles messaging and quorum management. Together, they offer robust high availability for various applications.
- VMware vSphere High Availability (HA). A virtualization-focused clustering technology that automatically restarts virtual machines on healthy hosts if a node fails.
- Oracle Real Application Clusters (RAC). A database clustering technology that allows multiple servers to run Oracle databases simultaneously. It ensures scalability and high availability.
- Kubernetes clustering. A container orchestration platform that distributes workloads across multiple nodes, supporting scalability, self-healing, and automated failover for containerized applications. This is not a traditional server clustering system. It is explicitly made for containerized workloads.
Note: Learn more about Linux clusters.
Server Clustering and High Availability
High availability (HA) is a core goal of server clustering. It ensures applications and services remain operational even when one or more servers fail. Clusters achieve HA by combining redundancy, automated failover, quorum management, and continuous resource monitoring. These mechanisms reduce downtime, maintain service continuity, and support business-critical workloads.
The following sections explain the key components that enable high availability in server clusters.
Active-Active and Active-Passive Configurations
High availability clusters are typically implemented in one of two configurations:
- Active-Active. All nodes are online and actively handle traffic simultaneously. Workloads are distributed across nodes to improve performance and fault tolerance. If one node fails, the remaining nodes continue serving requests without interruption.
- Active-Passive. One node is active and handles traffic, while passive nodes remain on standby. If the active node fails, a passive node takes over. This setup ensures continuity but may underutilize resources during normal operation.
Redundancy
Redundancy in server clusters involves maintaining multiple copies of critical resources, such as applications, data, and computing power, across different nodes. If one node fails, other nodes continue to handle workloads without interruption.
This duplication ensures services remain available and prevents a single point of failure from causing downtime.
Failover
Failover is an automatic transfer of workload from a failed node to healthy nodes within the cluster. Clustering software continuously monitors node health and triggers failover when a problem is detected.
This process minimizes service disruption and is essential for maintaining uninterrupted access to applications and data.
Quorum Management
A quorum is the minimum number of cluster elements that must be online and able to communicate for the cluster to continue operating. Quorum management ensures only one subset of nodes controls the cluster at any time. This prevents split-brain scenarios, where disconnected nodes operate independently and risk data corruption.
By requiring a quorum, the cluster makes consistent decisions about which nodes stay active during hardware failures or network outages.
Resource Monitoring
Cluster software continuously monitors the status of nodes, applications, and services. If performance degradation, failures, or connectivity issues occur, the software automatically redistributes workloads or triggers alerts for administrators.
Resource monitoring ensures proactive management and helps maintain high availability across the cluster.
Server Clustering and Load Balancing
Load balancing distributes workloads across multiple servers in a cluster to optimize resource utilization, improve performance, and prevent any single node from becoming a bottleneck. By evenly allocating tasks, clusters handle higher traffic, reduce response times, and scale efficiently as demand grows.
The following sections explain how server clusters implement load balancing and maintain system performance under varying workloads.
Task Distribution
Clusters distribute incoming requests or processing tasks across multiple nodes to prevent any single server from becoming overloaded. This distribution is based on factors such as current load, node capacity, or predefined rules.
Effective task distribution improves overall performance and response times.
Session Persistence
Some applications require that user sessions remain on the same node for the duration of their interaction. Load balancing mechanisms maintain session persistence, which directs repeated requests from the same client to the same node while still balancing other traffic across the cluster.
This approach ensures consistent application behavior and prevents issues like lost session data or interrupted transactions.
Dynamic Scaling
Clusters can scale horizontally by adding new nodes to handle increased workloads. Load balancing automatically integrates the new nodes into the distribution algorithm, allowing the system to expand capacity without downtime or manual intervention.
This process enables the cluster to adapt to changing traffic patterns and maintain performance during peak usage.
Health Monitoring
Load balancing relies on continuous monitoring of node health and performance. Nodes that are unresponsive or underperforming are temporarily removed from the pool until they recover.
This approach ensures workloads are only assigned to fully operational nodes, maintaining performance and reliability.
Server Clustering Benefits
Server clusters enable organizations to enhance the reliability, performance, and scalability of their critical applications. By coordinating multiple servers, clusters ensure workloads are efficiently distributed and services remain available even under high demand or hardware failures.
The following list highlights the main benefits of using server clusters:
- High availability. Clusters ensure applications and services remain operational even if one or more servers fail.
- Improved performance. Workloads are distributed across multiple nodes, thereby reducing bottlenecks and increasing response times.
- Scalability. Additional nodes can be added to the cluster to handle increased traffic or processing demands without downtime.
- Resource optimization. Clusters allow for better utilization of CPU, memory, and storage by pooling resources across multiple servers.
- Disaster recovery support. Clustering provides redundancy and failover capabilities that are critical for minimizing the impact of hardware or software failures.
- Flexibility for diverse workloads. Clusters can support databases, virtual machines, web applications, and containerized environments simultaneously.
Server Clustering Challenges
While server clusters provide significant benefits in terms of availability, performance, and scalability, they also introduce complexities that organizations must manage.
Implementing and maintaining a cluster requires careful planning, specialized knowledge, and ongoing monitoring to ensure optimal operation.
The following list highlights common challenges associated with server clustering:
- Complex configuration and management. Setting up a cluster requires careful planning and specialized knowledge to configure nodes, networking, and failover mechanisms correctly.
- Higher costs. Clusters often require additional hardware, licensing, and maintenance, which increases infrastructure and operational expenses.
- Uneven resource utilization. Improper load balancing or misconfigured nodes result in some servers being overworked while others remain underutilized, thereby reducing overall performance.
- Network dependency. Cluster operation relies on fast and reliable network communication. Network failures impact availability and cause split-brain scenarios.
- Software compatibility issues. Not all applications or services are cluster-compatible, which limits the ability to leverage clustering capabilities fully.
- Monitoring and maintenance overhead. Continuous monitoring, patching, and testing are required to ensure nodes and clustering software function correctly.
Conclusion
This tutorial explained what a server cluster is and how it works. It also elaborated on various server clustering technologies, use cases, and types of server clusters. We also outlined the most common benefits and challenges associated with server clustering.
Next, learn about high performance computing (HPC) and how HPC clusters work.



