
A high level of redundancy is one of the defining features of modern data centers. Redundancy ensures critical systems remain operational in case of hardware failures, power-related issues, and data breach attempts. As demand for uninterrupted digital services grows, understanding the inner workings of data center redundancy has never been more critical.
This article is an in-depth guide to data center redundancy that explains how facility owners design fault-tolerant infrastructure. Read on to learn what types of redundancy you can implement within data centers and see why redundant components are vital to avoiding unplanned downtime.

Check out our article on data center power outages and see why 52% of all major outages in the last three years resulted from power-related incidents.
What Is Data Center Redundancy?
Data center redundancy is the practice of duplicating critical components and systems within a facility to ensure continuous operation in the event of failure. The goal of redundancy is to eliminate single points of failure (SPOF) and maintain high availability even when individual pieces of hardware or software malfunction.
Facility owners can implement redundancy across multiple layers of infrastructure, including:
- Power systems (dual utility feeds, backup generators, uninterruptible power supplies (UPS), etc.).
- Cooling systems (duplicate HVAC units, backup chillers, redundant coolant pumps, etc.).
- Networking equipment (redundant routers, switches, firewalls, ISP links, etc.).
- Compute and storage components (mirrored servers, replicated storage arrays, standby nodes, etc.).
By incorporating redundancy into each layer, data centers become better equipped to minimize service disruptions caused by hardware failures, utility outages, natural disasters, or cyber attacks. Thorough redundancy also helps localize faults and prevent cascading failures that impact multiple systems.
Modern data centers rely heavily on automation and real-time monitoring to support redundant systems. Most facilities use automated tools to detect anomalies, trigger failovers, and ensure backup systems engage precisely when needed without manual intervention.
Facility owners don't have to duplicate every component in the data center to guard against downtime. Instead, redundancy should focus on systems that are critical to operations or most vulnerable to failure.
For example, replicating core networking equipment or power systems is vital, but duplicating non-critical auxiliary systems is often not worth it from a cost-benefit standpoint.
Redundancy doesn't stop at hardware or software. Your data also benefits from duplication, so check out our article on data redundancy to see how companies ensure they never permanently lose access to important files.
Why Is Data Center Redundancy Important?
Data center redundancy is not about avoiding failures but about expecting issues and designing systems that continue to operate in the face of disruptions. Proactively preparing for incidents yields the following benefits:
- Better availability. Redundancy minimizes the risk of downtime by ensuring that backup systems are ready to take over if a primary component fails. This capability is essential for meeting high availability targets.
- Disruption-free maintenance. Redundancy enables teams to perform routine maintenance and hardware upgrades without taking systems offline. Whenever technicians work on a piece of equipment, they can reroute operations to the backup system to avoid downtime.
- Fault tolerance. With multiple redundant systems in place, a data center can prevent minor issues from causing cascading failures and escalating into full-blown service outages.
- Reduced incident response stress. In highly redundant environments, in-house teams can respond calmly to failures, as operations continue running without disruption. There's less pressure on the team, so that they can handle issues methodically and with less urgency.
- Compliance and SLA fulfillment. High redundancy helps data centers comply with regulatory frameworks and meet the terms of service level agreements (SLAs) with clients.
- Downtime-free scaling. Redundant systems often make it easier to scale operations because technicians can add new capacity to equipment (so-called vertical scaling) without causing service disruptions.
- Improved customer trust. Consistent uptime and reliable service foster customer confidence. As an extra benefit, guaranteeing higher uptime than competitors is a strong selling point for customer acquisition and retention.
- Faster RTOs and RPOs. Redundancy reduces recovery times by enabling systems to switch over quickly to backup infrastructure. Shorter recovery time objectives (RTOs) and recovery point objectives (RPOs) ensure facilities can promptly restore data and services in case of unforeseen incidents.
Types of Data Center Redundancy
The following few sections present the different types of data center redundancy that boost the facility's resilience to unexpected incidents and avoid unplanned downtime.
Power Redundancy
Power redundancy involves implementing backup systems to ensure a continuous electricity supply to critical components in case the primary power source fails. Here are the most common strategies data center owners rely on to ensure power redundancy:
- Dual utility feeds. Many data centers receive electricity from two separate utility substations, which reduces reliance on a single grid path.
- Backup generators. Top-tier data centers have fuel-powered generators that provide long-term backup power during extended outages.
- Dual power distribution units (PDUs). PDUs distribute electricity from a UPS or generator to server racks. Redundant PDUs are a standard precaution for ensuring power continues to flow even if one path fails.
- Uninterruptible power supply. A UPS provides short-term power via batteries or flywheels to bridge the gap between a power outage and the backup generator startup. In addition to preventing downtime, UPSes shield equipment from voltage spikes and sags.
- A/B power feeds. In this redundancy strategy, each critical server or device connects to two separate power circuits to ensure a continuous power supply. In high-end setups, these feeds are powered by separate UPSes and generator chains.
Even with all these precautions, power systems require rigorous maintenance and real-time monitoring to remain reliable. Regular generator testing, battery health checks, and power usage effectiveness (PUE) tracking are non-optional.
Check out our article on data center power monitoring to learn about the ins and outs of tracking power consumption at data centers.
Cooling Redundancy
Data centers generate immense heat due to the high density of hardware. Without adequate cooling, components can overheat, degrade, or even fail.
Cooling redundancy ensures the facility maintains safe operating temperatures even if a cooling component fails or undergoes maintenance.
Here are the most common strategies for ensuring cooling redundancy:
- Dual HVAC (heating, ventilation, air conditioning) systems. Data centers often deploy multiple HVAC units that operate in tandem or in A/B failover modes. If one system goes down, a redundant unit can maintain optimal environmental conditions.
- Backup CRAC and AHU. Many facilities rely on redundant or concurrently operating computer room air conditioning and air handling units to regulate temperature and humidity in tightly packed server rooms.
- Extra chillers and cooling towers. Many large data centers deploy backup chillers and pumps, separate cooling loops, and cooling towers to ensure the continuity of water-based cooling.
Effective airflow management through hot and cold aisle containment plays a critical supporting role in most cooling redundancy strategies. Proper containment prevents the mixing of hot and cold air streams, which improves the efficiency of both primary and backup cooling systems.
Most facility owners set up sensors throughout the data center to continuously monitor temperature, humidity, and airflow. These systems trigger alerts when conditions breach predefined thresholds and automate failovers to secondary cooling systems.
Network Redundancy
Network redundancy is the practice of creating multiple independent paths for data traffic. If one path becomes unavailable due to failure, traffic congestion, or maintenance, another takes over automatically to preserve uptime and performance.
Below are the most popular strategies for ensuring sufficient network redundancy:
- Multiple internet service providers. Using two or more ISPs with diverse physical routes minimizes the risk of an external network outage affecting operations.
- Redundant switches and routers. Many data centers deploy dual switches, edge routers, and aggregation layers to prevent component failures from causing downtime.
- Dual network paths and cabling. Many facility owners set up servers and other critical systems with two or more physical Network Interface Cards (NICs), each connected to separate switches via individual cable routes. This precaution guards against both hardware failure and cable damage.
- Redundant network security appliances. High-availability setups often include dual firewalls and intrusion detection systems (IDS) in active-passive or active-active configurations to maintain security during equipment failure or maintenance.
- Redundant DNS. Some facilities implement redundant DNS systems to ensure continuous domain name resolution even if the primary DNS provider fails.
- Border Gateway Protocol (BGP) routing. Many data centers use BGP to route traffic dynamically between multiple ISPs based on availability and performance. If one ISP fails, BGP dynamically reroutes traffic through another provider.
Learn about BGP hijacking and see how hackers exploit this protocol to spy on traffic and steal data.
Compute and Storage Redundancy
A data center isn't fault-tolerant unless its compute and storage layers can withstand failure. Data center owners protect these layers with compute and storage redundancy measures.
Compute redundancy is the practice of distributing workloads across multiple servers. That way, a failure of any single machine does not interrupt service.
This type of redundancy can be achieved through techniques like:
- Running failover clusters that start running if the primary servers fail.
- Distributing workloads with load balancers to allow other compute nodes to absorb traffic if one goes down.
- Using virtualization and hypervisors to migrate virtual machines (VMs) between hosts or restart them on healthy nodes.
- Spreading deployments across multiple data center sites to maintain service in case one of the facilities suffers an outage.
- Replicating and checkpointing the critical state across nodes to enable fast recovery without major service disruption.
Storage redundancy is the practice of replicating data across multiple disks, volumes, or even facilities to ensure files remain intact and available in the face of disk failure, data corruption, or site-wide outages. Here are the most common techniques for ensuring sufficient storage redundancy:
- Implementing RAID configurations to mirror or distribute data across multiple disks.
- Deploying storage area networks (SANs) with redundant disk arrays accessible by several servers.
- Performing real-time replication to duplicate data across multiple storage systems (locally or remotely).
- Using network-attached storage (NAS) setups with failover clustering or dual controllers.
- Taking snapshots and backups to preserve point-in-time copies for recovery in case of data loss.
- Maintaining geo-redundant storage to replicate data across distant data centers.
Our in-depth guide to business data security takes you through everything you need to know about keeping valuable files safe from cyber and physical threats.
Data Center Redundancy Levels
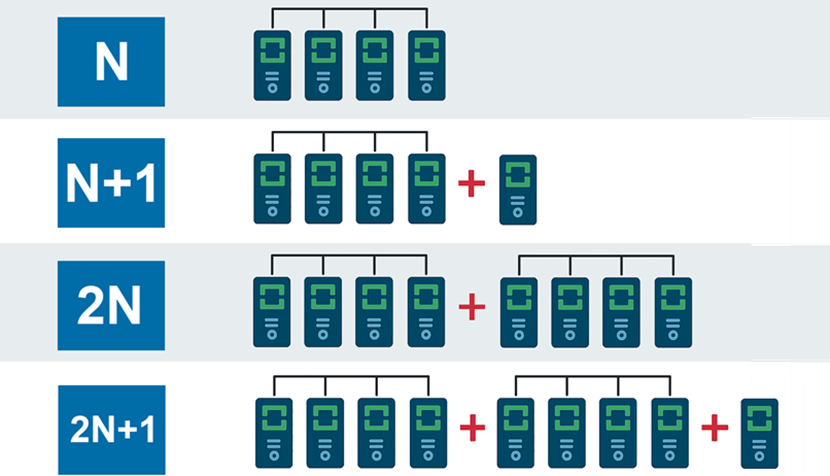
Data center redundancy levels are classifications that describe how resilient a data center is to failures. These levels revolve around the concept of N, which represents the baseline amount of capacity needed to support normal operations.
N is the minimum amount of infrastructure (power, cooling, compute, etc.) required to keep everything running under normal peak operating load. Think of N as the number of:
- Generators needed to power the entire data hall.
- Cooling units required to maintain safe operating temperatures throughout the facility.
- Network connections required to handle the maximum bandwidth demand.
- Servers needed to ensure optimal workload performance.
By definition, N does not include any redundancy and is thus susceptible to single points of failure. The lack of margin for failures means that any incident, whether a power supply tripping or a server crash, causes service degradation or downtime.
N systems are a fine choice for non-critical environments, but all vital systems in a data center require higher redundancy levels, such as N+1, 2N, or 2N+1.
N+1 (Basic Redundancy)
N+1 redundancy means that for every set of critical components needed to support normal operations (N), there is one independent backup ready to take over in case of failure.
For example, if a data center needs four cooling units to maintain temperature, an N+1 setup would require the deployment of five units. The extra unit acts as a spare if something goes wrong with one of the primary cooling systems.
The "+1" component doesn't run at full capacity unless a failure occurs. It sits idle or on standby, ready to start if one of the primary systems fails or needs maintenance. Some N+1 systems rotate usage to avoid wear on a single standby unit (a technique called rotational redundancy).
Unlike more advanced strategies, N+1 redundancy provides solid fault tolerance without requiring you to double the entire infrastructure. An N+1 setup is also easier to scale than more complex redundancy strategies and is ideal for moderately critical environments.
2N (Fully Redundant)
2N redundancy means duplicating every critical component in the target infrastructure. For each primary system (N), there's an entirely independent and identical backup (another N) running in parallel or on standby. If one system fails, the second one immediately takes over with no loss of functionality or downtime.
For example, if you need four UPS units to run your data center, a 2N setup would require eight units (four active ones and four backups). The two sets don't share components or dependencies and run on separate power paths and infrastructure.
2N redundancy eliminates single points of failure, even in auxiliary infrastructure (power feeds, cooling loops, network uplinks, etc.). One full system can fail with zero impact on operations, so there are no service interruptions during maintenance or in case of component failure.
On the negative side, 2N redundancy is expensive to implement. The strategy requires complete duplication of critical systems and doubles the amount of required physical space. Energy usage increases, especially if both systems run in active-active mode. 2N systems are also complex to manage since monitoring, testing, and syncing duplicate environments can be difficult.
2N+1 (Extra Resilient)
2N+1 redundancy is a wholly duplicated 2N infrastructure equipped with an extra backup component for added protection. If your system needs four components to operate (N=4), a 2N+1 setup includes four active components, four fully independent backups, and one additional spare unit.
An extra component beyond the full dual systems ensures that even if a failure occurs during maintenance or there's an unexpected fault in both main systems, there's still an additional standby unit in reserve. Like with 2N redundancy, most 2N+1 systems rely on active-passive setups with automatic failover.
2N+1 redundancy provides resilience against simultaneous failure and maintenance overlap, which is a key gap not covered by 2N strategies. As a result, systems enjoy maximum fault tolerance as they can withstand multiple simultaneous failures without causing downtime.
On the negative side, 2N+1 is even more expensive to implement than 2N systems, both from a CapEx and OpEx standpoint. This setup also requires greater physical space and more complex orchestration tools to manage, plus it can lead to underutilized hardware if the data center rarely uses the additional "+1" component.
Our CapEx vs. OpEx article explains the difference between these two cost models and shows how switching from CapEx to OpEx makes companies more financially flexible.
Data Center Tiers and Redundancy
The Uptime Institute's Tier Standard is the most widely recognized system for classifying data centers based on infrastructure resilience and redundancy. The Tier Standard has four levels that indicate the facility's ability to continue operating through faults and maintain uptime during incidents.
The higher the tier, the more redundancy is built into the facility.
Here's an overview of what to expect from each data center tier in terms of redundancy:
- Tier I facilities. Tier I data centers operate on an N configuration with a single, non-redundant path for power and cooling. These facilities do not include backup components, so any failure results in downtime. On average, tier I data centers can expect up to 28.8 hours of downtime annually.
- Tier II facilities. Tier II data centers follow an N+1 redundancy model, which adds backup components like an extra UPS or generator to provide solid fault protection. However, tier II facilities rely on a single power and cooling distribution path. These centers typically experience up to 22 hours of downtime annually.
- Tier III facilities. Tier III data centers have N+1 redundancy and dual power/cooling distribution paths. With an expected downtime of just 1.6 hours per year, tier III facilities are ideal for services that require high availability but may not need absolute fault tolerance.
- Tier IV facilities. Tier IV data centers offer the highest level of redundancy with a 2N or 2N+1 configuration for all critical systems. These facilities also have two completely independent power and cooling distribution paths. As a result, tier IV facilities experience only 26.3 minutes of downtime per year.
Our article on data center types offers an in-depth look at what each type of facility offers to clients.
Build Data Centers with Failure in Mind
If your data center cannot work through hardware failures, power outages, or cyber attacks, even a single unforeseen incident can result in prolonged and costly downtime. Use what you learned in this article to take stock of your data center architecture, identify problematic single points of failure, and ensure your operations have sufficient resilience to potential interruptions.



