
A power outage is among the most damaging incidents that can occur at a data center. Even a brief loss of power is often enough to cause equipment failure, data corruption, and considerable downtime.
Luckily, data center operators can largely mitigate outages with the correct set of precautions. If you've got the right mix of operational and technical safeguards, there's minimal chance a power outage will ever lead to prolonged downtime, hardware damage, data loss, or SLA breaches.
This article takes you through everything you must know about data center power outages. Jump in to learn about the most common causes of power failures and see what precautions companies take to lower the likelihood of costly outages at their data centers.

A big part of preventing outages is choosing a suitable location for your facility. Our article on data center site selection presents everything you must consider when deciding where to build a new facility.
What Is an Outage in a Data Center?
An outage in a data center refers to the loss of availability or functionality of the facility's systems, services, or infrastructure. This disruption can result from various causes (e.g., power failures, equipment malfunctions, network-related issues) and can be:
- Partial outage. Only some of the systems or services within the data center become non-operational.
- Total outage. Refers to a complete loss of functionality across the entire data center. All systems, services, and infrastructure cease to operate during a total outage.
The number of outages is at an all-time high, which is a misleading statistic. Recent reports from the Uptime Institute reveal that the total number of outages per facility has decreased compared to earlier years. So, while the absolute number of outages is higher than ever, that's because there are more data centers now than ever before.
Here are a few other interesting takeaways from the Uptime Institute's 2024 report:
- Around 55% of organizations reported at least one data center outage in the past three years.
- Just over 27% of organizations that experienced an outage describe the incident as significant, serious, or severe.
- Four in five respondents believe they could have prevented their most recent outage with better management.
- Failures of power and cooling systems are the cause of almost 71% of all data center outages.
- Almost 50% of significant outages in the last three years involved some form of human error. The staff's failure to follow procedures was the most common cause of issues.
- Cyber attacks were almost negligible as a direct cause of data center outages in the last three years. These incidents were the main cause of only 1% of all outages.
Preparing for potential outages is vital regardless of the data center's tier. Even the lowest tier has an expected uptime of 99.671% per year, which means an average Tier 1 facility can only afford about 28.8 hours of downtime per year.
Data Center Outage Causes
Understanding the root causes of outages is essential to preventing disruptions and ensuring continuous operation. Below is a close look at the most common causes of data center outages.
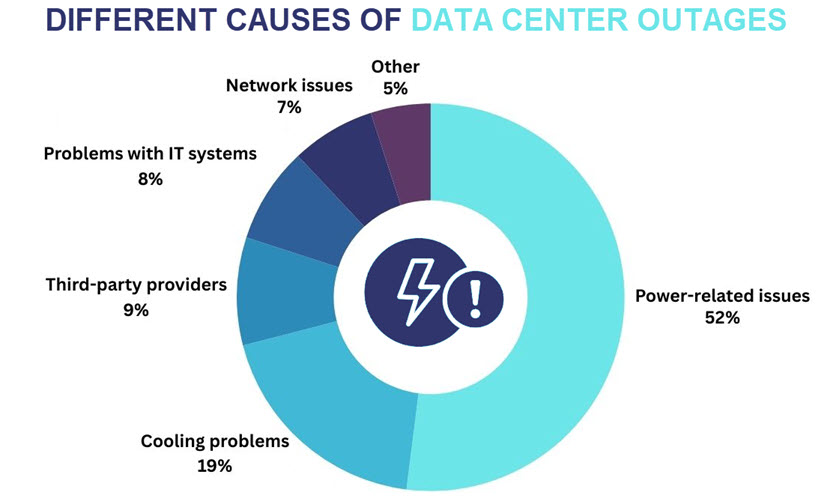
Power-Related Issues
Power issues are the most common cause of downtime, accounting for 52% of all data center outages in the last three years. These issues can originate from both external and internal sources.
Even a brief power disruption can have devastating consequences on data center operations. Here's an overview of the most common types of power-related problems that lead to outages:
- Local grid failures. Data centers rely on local utility providers for power supply. Grid instability, severe weather, or infrastructure issues can disrupt this supply, potentially causing an outage if the facility lacks backup generators.
- Generator failures. Local generators can fail for various reasons, including mechanical issues, lack of fuel, or improper maintenance.
- Uninterruptible power supply (UPS) failures. UPS systems ensure there is no interruption to the power supply between power loss and the activation of backup generators. UPS failures can cause immediate outages or destabilize equipment that depends on a constant power flow. UPS units often fail due to battery malfunctions, overloading, or inadequate capacity planning.
- Electrical system failures. Internal electrical infrastructure (e.g., power distribution units (PDUs), transformers, breakers) can fail due to electrical faults, overloading, or overheating. An electrical fault is among the most common causes of partial data center outages.
- Human error. Power-related outages often occur due to human error. Mistakes in managing electrical systems and maintaining equipment can trigger unexpected outages.
Power-related issues not only cause outages, but they also often result in hardware damage due to improper shutdowns or voltage spikes. Data losses and corruption are also common consequences if systems don't have proper data backups.
Cooling Failures
Data centers generate massive amounts of heat due to the high density of servers, networking devices, and other IT infrastructure. When cooling systems fail, the temperature inside the facility rises rapidly, which can lead to equipment overheating and shutting down. In the last three years, cooling-related issues were the direct cause of around 19% of all reported data center outages.
Here's a detailed look at how cooling failures lead to outages:
- HVAC system failures. Heating, ventilation, and air conditioning (HVAC) systems maintain optimal temperatures within a data center. Failures in these systems result in a rapid increase in temperature. Without proper cooling, servers and other hardware may shut down to prevent permanent damage.
- Chiller failures. Chillers cool liquid circulating through the data center to absorb heat from the equipment. A chiller failure disrupts the cooling process, leading to an overheating environment that can quickly result in equipment failures and shutdowns.
- Poor cooling system design. Inadequate design or improper configuration of cooling systems can result in hotspots or insufficient cooling. These issues cause localized overheating, which often takes down individual racks or even entire sections of the facility.
- Airflow obstructions. Blocked air vents restrict airflow, which also causes localized overheating. Without adequate airflow, equipment overheats and fails.
- Human error. Mismanagement of HVAC and cooling systems during routine maintenance or incorrect manual adjustments can compromise cooling efficiency. These mistakes often lead to overheating and outages.
In addition to causing outages, cooling failures often damage hardware due to prolonged exposure to high temperatures. This issue adds the expensive repairs or replacements of damaged equipment to the already high cost of downtime.
Third-Party Provider Issues
Problems related to third-party providers are the cause of around 9% of all data center outages. These issues occur when external service providers experience disruptions that impact crucial services within the data center. Here are the most common issues of this type:
- Telecommunications failures. Data centers rely on third-party providers for Internet and network connectivity. If these providers experience disruptions, the data center can lose external connectivity, which prevents users from accessing hosted services.
- Content delivery network (CDN) failures. Many data centers use third-party CDNs to distribute content quickly and efficiently to users. If a CDN provider experiences an outage or service degradation, local users may be unable to access content hosted within the data center.
- Utility provider failures. Data centers depend on utility providers for electricity supplies. A failure on the power provider's end can affect the data center's operations.
- Issues with managed service providers (MSPs). Many data center operators work with managed service providers for tasks like security, backups, and network management. If an MSP experiences issues, the services they manage within the data center can go offline, potentially causing an outage in some scenarios.
Learn more about how managed services work and see how you can distinguish responsible MSPs from vendors that cause more headaches than benefits in the long run.
IT System Failures
Issues with critical infrastructure's hardware and software are the cause of around 8% of all data center outages. Here's a breakdown of what failures most commonly cause an outage:
- Hardware failures. Critical hardware, such as servers and network switches, can fail due to age, poor maintenance, or manufacturing defects. These failures often lead to inaccessible data, disrupted connectivity, and complete system shutdowns.
- Software failures. Bugs, misconfigurations, or outdated software can result in system crashes or inefficient performance. If these issues affect a critical system, there is a chance that a failure will cause an outage.
- Virtualization problems. Many data centers rely on virtualization to maximize resource efficiency. Issues like hypervisor failures or resource contention between virtual machines can lead to significant disruptions. If virtualization platforms crash, they can take down multiple services or applications at once.
- Database failures. A failure in a database system can prevent users and systems from accessing the required data. The inability to access data can lead to downtime or degraded performance.
IT system failures are commonly caused by human error. Misconfigured systems, improper hardware installations, and incorrect software updates often inadvertently lead to outages. To make matters worse, even a single server failure might trigger a cascading effect if the data center does not have proper backups and redundancy precautions.
Network Problems
In the last three years, network problems were the direct cause of 7% of all data center outages. These issues prevent data centers from maintaining connectivity between servers and external users. Below are the most common network-related causes of outages:
- Router and switch failures. If routers or switches fail due to hardware malfunctions or configuration errors, network traffic can suffer bottlenecks or get completely cut off. A failure in a critical router or switch isolates affected network sections, which can cause an outage.
- Network congestion. Congestion occurs when the traffic volume exceeds the network's capacity to handle it efficiently. A congested network leads to slow response times, packet losses, and system crashes. Congestion often happens due to traffic spikes, inadequate load balancing, and poor scalability.
- Misconfigurations. Human error during network setup or maintenance is a leading cause of network problems. Misconfigured firewalls, routing tables, or load balancers can block traffic or route it incorrectly, leading to outages or degraded performance.
- Network interface card (NIC) failures. A failure in a NIC, whether due to a hardware fault, driver issue, or physical damage, can disconnect a server from the network. Multiple NIC failures in critical servers can lead to a cascading failure across the network and cause an outage.
- Fiber optic cable damage. Any physical damage to fiber optic cables can disrupt communication between the data center and external networks.
- Firmware bugs. Network devices such as routers, switches, and firewalls run on firmware that controls their operation. Firmware bugs lead to network instability, which often leads to dropped connections, routing loops, and network outages.
The five main causes discussed above were the reason behind 95% of data center outages in the last three years. The remaining 5% were caused by a mix of other factors, such as physical security breaches, cyber attacks, and unexpected environmental conditions like water leaks or earthquakes.
What Happens if a Data Center Loses Power?
If a data center experiences a power outage, its systems are instantly cut off from the electrical grid. Servers, storage devices, networking equipment, and cooling systems cease functioning. Most data centers are equipped with a UPS and backup generators in case of these events:
- The UPS provides temporary power to essential equipment until the staff gets the backup generator up and running. A typical UPS can power the infrastructure for only a few minutes.
- Backup generators supply power to keep critical systems running until the primary source of power kicks back in.
If the UPS and backup generators fail or are improperly maintained, the data center could experience a total outage.
Most data center operators shut down non-critical systems during an outage to conserve power and prioritize essential operations. Only vital systems, such as servers hosting critical applications, continue running on backup power.
Sudden loss of power often causes equipment to malfunction. Servers, routers, and other hardware may fail to shut down properly, leading to data corruption, hardware damage, or the loss of unsaved data. Electrical surges that occur when power is interrupted and then restored can further damage equipment.
Power outages also affect cooling systems. Without power, air conditioning and ventilation systems stop working, which causes a rapid temperature rise. Overheated servers suffer significant damage if the temperature exceeds safe operating levels, which leads to more downtime and costly repairs.
Once the facility restores power, the data center must carefully reboot systems to ensure everything comes back online smoothly. This process takes time as teams must:
- Check systems for errors.
- Validate data integrity.
- Test the equipment for damage.
A full restoration of services can take hours or even days if the outage results in significant hardware failures or data losses.
A data center's readiness for potential outages is one of the top factors you must consider during data center selection.
How to Prevent Data Center Outages?
Data center operators can prevent outages through proactive maintenance and investments in robust infrastructure. Below is a closer look at six tried-and-tested strategies for preventing data center outages.
Redundant Power Systems
Redundant power systems are one of the most critical measures for preventing data center outages and ensuring continuous operation during unexpected disruptions.
The primary goal of redundant power is to eliminate single points of failure in the power supply chain. Here are the most popular power redundancy precautions for data centers:
- UPS. A UPS provides immediate backup power to data center equipment that activates when the primary power source fails. Most data centers use battery-based UPSes, which use batteries to provide short-term power, or flywheel UPSes, which store rotational energy to provide backup power.
- Backup generators. Backup generators kick in when the facility loses utility power and provide long-term power until the grid is restored. Most data centers have diesel or natural gas-powered generators on standby.
- Dual power feeds. Many data centers have dual power feeds, which means two separate utility providers or substations are supplying the facility with power. This setup ensures that if one utility provider experiences a failure, the other can supply power to avoid an outage.
- Redundant PDUs. Power distribution units distribute electricity to individual racks and servers within the data center. Redundant PDUs ensure that power delivery continues uninterrupted if one unit fails.
Check out our article on data center power designs if you want an in-depth look at how experts ensure a facility never suffers a complete blackout.
Cooling System Redundancy
Redundant cooling systems ensure that if one cooling component or system fails, others can take over to keep the temperature stable.
N+1 is the most common cooling redundancy configuration in data centers. In this setup, for every "N" operational cooling unit required to keep the data center at optimal temperature, there is at least one additional unit ("+1") on standby. If one cooling unit fails or requires maintenance, the backup unit takes over without affecting the overall cooling capacity.
For the most critical components, data centers often turn to N+2 (two additional backups per cooling unit) or even 2N redundancy (an approach that duplicates the entire cooling infrastructure, meaning that the data center has two independent, completely functioning cooling systems).
Data centers often use multiple cooling technologies to achieve 2N redundancy. A common strategy is to combine air-cooled and liquid-cooled systems to provide extra protection. If one method fails, the other can maintain a stable environment.
Many data centers also invest in hot and cold aisle containment. Containments ensure efficient cooling distribution and reduce the workload on cooling systems. By separating hot and cold air, operators make cooling more efficient and reduce the chance of critical failures.
Preventative IT Maintenance
Preventive maintenance focuses on proactively identifying and addressing IT issues before they lead to failures. Regular maintenance keeps systems in optimal condition and reduces the risk of outages caused by equipment failures or software-related problems.
Here's an overview of what preventative IT maintenance usually entails:
- Regular hardware inspections. Frequent inspections of servers, storage devices, and other critical hardware help identify wear and tear, loose connections, and potential malfunctions. Early detection of issues like faulty hard drives, malfunctioning power supplies, or failing network cards allows operators to replace or repair hardware before it starts causing problems.
- Cooling maintenance. Regular cleaning and inspection of cooling systems ensures proper airflow and temperature regulation.
- Software updates and patches. Keeping IT systems up to date with the latest updates is crucial for preventing vulnerabilities that lead to system failures or security breaches. Outdated software often contains security flaws that, if exploited, could cause downtime or compromise system integrity.
- System performance monitoring. Continuous network and server monitoring help detect abnormal behavior, such as increasing CPU usage, memory leaks, or declining disk health. These early warning signs indicate potential problems that could lead to an outage if the team does not take corrective action.
- Configuration audits. Regular audits of system configurations help ensure that servers, networking equipment, and storage systems are correctly set up and optimized.
- Redundancy system testing. Regular redundant component testing ensures that components are functioning properly and ready to operate in case of a facility issue.
Preventive IT maintenance considerably minimizes the risk of unexpected failures and outages. Proactive maintenance also keeps systems running smoothly and ensures that both hardware and software are optimized for performance.
Proactive Disaster Recovery Planning
Disaster recovery (DR) planning is a critical measure for preventing long-term outages in data centers. DR ensures facilities maintain business continuity during and immediately after unforeseen incidents.
Disaster recovery planning requires data center operators to create a comprehensive step-by-step plan outlining the actions staff must take in case of outage-related incidents. A disaster recovery plan must include the following essential components:
- Risk assessments that identify potential incidents and evaluate their impact on operations and downtime.
- Steps for restoring critical IT systems and infrastructure, including servers, power systems, and cooling.
- Guidelines for retrieving data from backups.
- A strategy for contacting internal teams, stakeholders, and vendors.
- Clearly defined targets for system recovery time (RTO) and acceptable data loss (RPO).
- Procedures for migrating operations to a secondary data center during a major outage.
- Up-to-date documentation for audits and legal requirements.
Check out our Disaster-Recovery-as-a-Service (DRaaS) page if you prefer ready-made DR solutions over creating a custom DR plan from scratch.
Smart Third-Party Provider Management
Whenever a data center partners with a third-party provider, operators must ensure that the partner offers a strong service level agreement. SLAs guarantee high uptime, rapid response times, and clear accountability for service issues.
Continuous monitoring of third-party services is another critical measure. By tracking provider performance, data center operators can identify potential issues early, such as network latency or degraded hardware.
Additionally, having redundant providers or backup options is always a smart investment. For example, relying on multiple internet service providers (ISPs) ensures that a failure with one vendor does not disrupt operations to the point that you suffer a total outage.
Regular Staff Training
Staff training and human error reduction are essential for preventing data center outages. Here's an overview of everything you must implement in this regard:
- Comprehensive training programs. Train the staff in standard operating procedures (SOPs) for routine tasks like system monitoring, maintenance, and troubleshooting. Training must include detailed protocols for responding to emergencies like power failures, cooling system malfunctions, and security breaches.
- Third-party equipment usage. Ensure the staff know how to use any third-party equipment or software in the data center to prevent mishandling or misconfigurations.
- Regular simulations and drills. Conduct periodical simulations of various outage scenarios to prepare staff members for real-life situations. Drills ensure that staff can execute recovery plans when it really matters.
- Operational guidelines. Provide detailed manuals and checklists for routine procedures to guide staff members during daily tasks.
- Error logging and analysis. Maintain detailed logs of any operational errors or incidents to track recurring issues and identify their causes. Regularly analyze error logs to identify common mistakes and implement corrective actions to prevent recurrence.
- Feedback mechanisms. Establish feedback channels that enable staff members to report difficulties or suggest procedure improvements.
Check out our article on data center security to see everything companies must include in their staff training to ensure sufficient security levels.
Cost of Data Center Outages
The Uptime Institute reports that the majority of outages in the last three years (around 54%) cost operators more than $100,000. Almost 16% of these incidents resulted in damages that exceeded $1 million. The exact cost depends primarily on the following factors:
- Duration of the outage.
- Size and type of the data center.
- Number of users that rely on the data center.
- The industry in which the organization operates.
Here's a detailed look at why a data center power outage often ends up being so costly:
- Revenue losses. Outages result in an immediate and direct loss of revenue for businesses that rely on the data center to deliver services. Every minute a website or service is offline results in lost transactions, unfulfilled orders, and customer churn.
- SLA penalties. Many data centers operate under SLAs that guarantee a certain level of uptime. If an outage causes downtime that exceeds the terms of the SLA, the data center may be required to compensate clients through financial penalties or contract renegotiations.
- Operational costs. Outages often require immediate troubleshooting and recovery efforts, which are often costly. Operators must pay for emergency repair teams to address equipment failures, deploy additional resources to restore data, and replace damaged equipment.
- Data loss and recovery costs. Restoring data from backups and reconstructing corrupt databases are costly and time-consuming tasks.
- Reputational damage. Frequent or prolonged outages erode customer trust. Reputational damage often leads to customer attrition, negative press coverage, social media backlash, and difficulties attracting new clients.
- Legal and compliance penalties. A data center power outage can result in legal consequences if it causes a violation of regulatory obligations.
Prefer not to have to worry about redundant power, robust security, and guaranteed uptime? If yes, you're likely a good candidate for colocation services that enable you to offload outage-prevention responsibilities to a third-party provider.
Don't Let Outages Take You by Surprise
If operators are caught off guard, a data center power outage can severely impact both short-term and long-term bottom lines. Use what you learned in this article to better understand what you're up against and lower the likelihood of your data center suffering costly outages and prolonged downtime.



