
Data loss prevention is essential to every company's effort to ensure business continuity. While disaster recovery plans protect valuable information, they are most effective when combined with proactive data protection measures like RAID, data replication, and data mirroring.
This article introduces data redundancy, a concept behind the popular data loss prevention techniques.

What Is Data Redundancy?
Data redundancy sustains availability and improves data resiliency by storing identical information in multiple locations. For organizations utilizing colocation facilities, this often means replicating data across geographically diverse data centers to ensure continuous operation.
Data management systems use redundancy to back up databases or data storage. All backups involve redundancy, but the term is often applied specifically to techniques that prioritize immediate accessibility.
While it can occur by design, redundancy can happen accidentally due to errors or poor database design. Therefore, accidental redundancy can lead to data inconsistency, with different copies of the same data having conflicting values. As a consequence, organizations can face increased storage requirements and associated costs.
Note: A common type of redundancy in colocation facilities and enterprise IT environments is N+1 redundancy. Read N+1 Redundancy Explained to learn why it is a widely used standard.
The following sections explain and differentiate key data redundancy concepts.
File-Based Data Redundancy vs. Database
File-based redundancy involves the creation of exact copies of a file stored on different drives or servers. Examples include:
- Copying files to external drives.
- Using RAID systems to mirror or stripe data across disks.
- Creating file system backups.
While relatively simple, this method can produce significant storage overhead and offer less granular control over data consistency.
Database redundancy replicates data within a database management system (DBMS). Examples include:
- Database replication (master-slave, master-master).
- Database mirroring.
- Clustering.
Database replication is more complex but provides granular control over data replication. It is often used for mission-critical applications that require continuous data access.
Intentional vs. Unintentional Data Redundancy
Intentional redundancy refers to data replication purposefully conducted for backup purposes. For example, a bank may replicate customer transaction data across multiple data centers to ensure uninterrupted service.
Unintentional redundancy is created whenever inadequate data management practices result in accidental data duplication. It not only wastes storage space but also introduces data inconsistency. For example, when multiple departments independently maintain customer lists, the company-wide customer list may contain duplicate entries with potentially conflicting information.
Data Redundancy vs. Disaster Recovery
Data redundancy concentrates on immediate availability, operational continuity, and fault tolerance. Should a server fail, redundant data copies ensure that operations can proceed seamlessly.
In contrast, disaster recovery addresses broader scenarios when it is necessary to restore data from backups (potentially at a remote location) and rebuild the infrastructure. This process often involves downtime.
How Does Data Redundancy Work?
Data redundancy is generated by creating and maintaining multiple copies of data. The copies are made using techniques like RAID, which employs multiple physical drives to create a single logical drive, where data is mirrored or striped across drives.
This system ensures that critical data is:
- Distributed. Individual servers are prevented from becoming overloaded.
- Redundant. The data is protected against hardware failure.
- Consistent. All copies of the data are up-to-date.
Database replication involves continuously copying data from a primary database to one or more secondary databases. These techniques ensure that if one data copy becomes unavailable, others remain accessible.
Here's a breakdown of the key concepts:
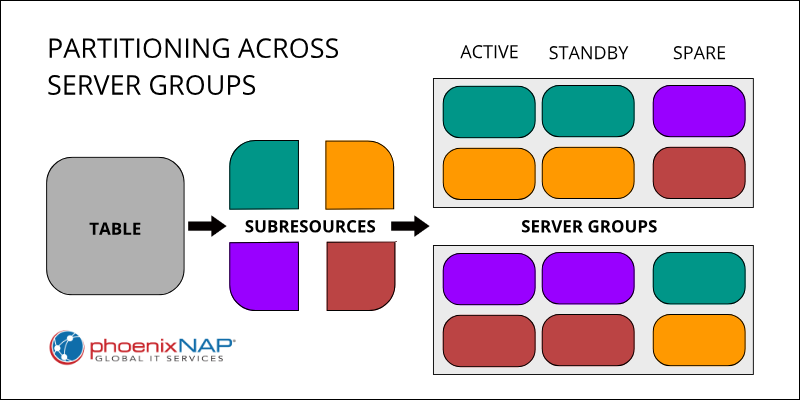
- Partitioned Databases. The session and policy binding databases consist of sections (partitions). Each server group within the system hosts a specific portion of this data, distributing the data load across multiple servers.
- Server Group Redundancy. Each server group has a redundant design using Active/Standby, Active/Spare, or Active/Standby/Spare server configurations. Within each group, multiple servers hold identical copies of the data for that partition.
- Data Replication and Synchronization. The Active, Standby, and Spare servers within a server group maintain exact replicas of their assigned data partition. A process called replication keeps these replicas synchronized. The Standby and Spare servers are continually audited and updated to match the master copy on the Active server, ensuring data consistency.
The diagram below demonstrates partitioning a table into four subresources and distributing them across two server groups. Redundancy is achieved by each group holding Active/Standby pairs of two subresources and spare copies of the remaining two.
Data Redundancy Use Cases
Data redundancy is crucial in numerous applications. The following are some typical use cases:
- High-availability systems, such as those used in online banking or e-commerce, rely on redundancy to ensure continuous operation.
- Distributed databases, utilized by global corporations, use redundancy to provide geographically dispersed users with fast access to data. For example, a company might use a colocation data center to host a replicated database, enabling faster access to data for users in that region.
- Content delivery networks (CDNs) employ redundancy to store cached content on multiple servers, reducing user latency.
- Fault-tolerant storage systems, like those in data centers, use redundancy to protect against hardware failures.
- Data warehousing and analytics use redundant data copies for efficient data processing and analysis.
Data Redundancy Benefits and Challenges
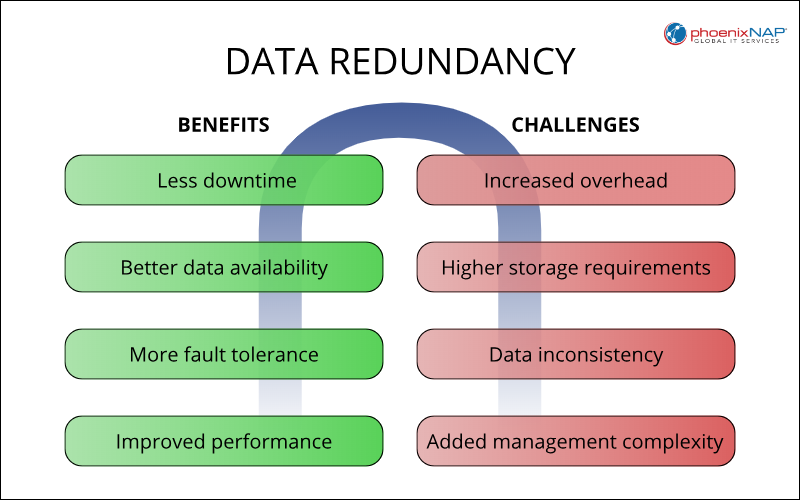
Data redundancy provides significant advantages in terms of data availability and fault tolerance. However, it also increases storage requirements, data inconsistency risks, management complexity, and maintenance overhead.
The diagram below gives an overview of redundancy benefits and challenges.
Benefits
The most obvious benefits of data redundancy are:
- Reduced downtime. Redundancy minimizes the impact of failures, reducing downtime.
- Increased data availability. Redundant copies ensure data remains accessible even if one copy is unavailable.
- Improved fault tolerance. Systems can continue operating despite hardware or software failures.
- Enhanced performance (read operations). Distributing data across multiple servers can improve read performance.
Challenges
The following are the main challenges associated with data redundancy:
- Increased maintenance overhead. Regularly updating and maintaining redundant data adds to the workload.
- Increased storage requirements. Storing multiple copies of data consumes more storage space.
- Data inconsistency risks. Maintaining consistency across multiple copies can be complex.
- Complexity in data management. Managing redundant data requires a comprehensive strategy.
Data Redundancy Tools and Techniques
Various technologies and techniques facilitate data redundancy implementation. For example:
- Cloud storage replication services. Cloud providers offer built-in redundancy options to automatically replicate data across multiple regions to provide minimal downtime.
- Redundant Array of Independent Disks (RAID). The technology for combining multiple physical drives into a single logical unit.
- Database replication (master-slave, multi-master). Copying data between databases to ensure consistency.
- Data mirroring. Creating an exact copy of data on a separate storage device.
- Distributed file systems. Data can be distributed across multiple servers for redundancy and performance.
Note: Check out our Free RAID Calculator to determine which RAID level is best for redundancy in your use case.
Data Redundancy Best Practices
Effective implementation of data redundancy requires precise planning and execution. The following are best practices for implementing data redundancy:
- Create cost-effective redundancy. Building and maintaining redundant infrastructure in-house can be expensive. Colocation allows businesses to access enterprise-grade redundancy without capital expenditure. Colocation centers share the cost of redundant infrastructure, which can be far more affordable than building a fully redundant, private data center.
- Implement data validation and consistency checks. Regularly verify data integrity across redundant copies.
- Automate redundancy processes. Automate data replication and failover mechanisms.
- Regularly test redundancy mechanisms. Conduct periodic tests to ensure failover procedures work as expected.
- Monitor storage utilization and performance. Identify issues by tracking storage capacity and performance metrics.
- Document redundancy configurations. Maintain documentation of redundancy settings and procedures.
Data Redundancy Alternatives
The following sections present some frequently used alternatives to data redundancy as a business continuity measure.
Backups
Backups are point-in-time copies of data for recovering information in cases of data loss. As copies, backups introduce redundancy but do not offer immediate availability.
Backups protect against a broader range of threats than some other redundancy methods, including:
- Hardware failures.
- Software errors.
- Accidental deletion.
- Cyberattacks (like ransomware).
- Natural disasters.
Note: Read about different backup types in Full vs. Incremental vs. Differential Backup: A Detailed Comparison.
CDP
Continuous Data Protection (CDP) provides near-real-time data replication, capturing every change made to the data. CDP works in three stages:
- Change tracking. CDP systems continuously monitor and capture every write operation or change made to data. Tracking is often done at the block level (the most granular storage level).
- Journaling/versioning. The system stores captured changes in a journal or log. The detailed history of changes allows restoration to any point in time.
- Replication. The system replicates the changes to a secondary storage location (local or remote). Since this process occurs continuously, the secondary copy is nearly identical to the primary copy.
Snapshots
Snapshots create read-only copies of data at a specific time. During a snapshot creation, the system does not copy the entire dataset. Instead, it only copies the changes made since the last snapshot.
Key advantages of snapshots include rapid data recovery to a previous state, a minimal impact on system performance, and space efficiency.
Image-based Backups
Image-based backups capture the entire system state, including the operating system, applications, and data, for complete recovery. Unlike file-level backups, which focus on individual files and folders, image-based backups create a bit-by-bit copy of the entire disk or partition (including the operating system, applications, configuration settings, and all data files).
The system creates images at the block level, copying the raw data blocks on the storage device. The single image file can reside on various media, such as external hard drives, network storage, or cloud storage.
Images help recover from system crashes, hardware failures, or ransomware attacks. Compared to file-level backups, image backups reduce recovery time, as the user does not need to reinstall the operating system and applications.
Conclusion
This article introduced you to the concept of data redundancy. It explained the mechanisms and types of redundancy, highlighted its benefits and challenges, and presented best implementation practices.
Next, learn about high availability, an essential concept for setting up mission-critical IT environments.

