
RAID is a data storage arrangement that combines multiple physical drives into one logical unit. The setup aims to improve storage performance, provide fault tolerance, or both.
RAID uses different techniques to distribute data across drives. Knowing the differences between RAID types and setups is essential when planning a reliable storage configuration.
In this article, learn about RAID levels and types, their pros and cons, and when to use them.

What Is RAID?
Redundant Array of Independent Disks (RAID) is a method of combining multiple disks for storage. The setup links together and distributes data across drives to prevent data loss and speed up performance.
Different RAID types provide a varying balance of speed, data protection, and storage efficiency. Each type provides some benefits and drawbacks, so there isn't a single solution for every setup.
RAID vs. JBOD
RAID and JBOD (Just a Bunch Of Disks) use multiple drives in their configuration, but with a different purpose. Compared to RAID, JBOD is a simpler approach for expanding storage without redundancy.
The table below compares RAID vs. JBOD:
| Feature | RAID | JBOD |
|---|---|---|
| Structure | Combines drives into a logical array using specific rules. | Treats each drive as a separate volume. |
| Redundancy | Some RAID levels have fault tolerance. | No redundancy by default. |
| Performance | Can improve read/write speeds. | Performance depends on individual drive. |
| Data Recovery | Some levels allow recovery after a drive failure. | Data loss in case of drive failure. |
| Use Case | Critical systems and performance-heavy workloads. | Non-critical systems and large capacity storage. |
How Does RAID Work?
RAID distributes data across disks using specific rules. The rules are predefined for each RAID level, and they process data according to specific patterns. The system can improve performance by working with data in parallel, duplicating data, or storing information to rebuild data in case of drive failure.
A RAID setup shows as a unified storage device for the operating system. The OS handles the underlying data storage mechanisms in the background without user intervention.
What Is RAID Controller?
The central component in a RAID setup is a RAID controller. It manages data movement and abstracts the RAID array to the operating system as a single logical unit. The controller handles data distribution, recovery, and redundancy depending on the rules defined at the RAID level.
There are two main types of RAID controllers:
- Hardware RAID Controllers. These are physical devices that connect to drives. They handle RAID operations apart from the system's CPU. Enterprise environments use hardware RAID controllers due to their performance and reliability.
- Software RAID Controllers. A software solution managed by the system's OS. The solution uses system resources to run RAID functions. Software RAID controllers are cost-effective for small setups and are slower than hardware-based RAID.
A RAID controller shows the storage array as a single logical drive to simplify storage management for the user.
RAID Storage Techniques
RAID uses three main storage techniques to manage data storage and protect data on multiple drives. These methods are used alone or in combination, depending on the RAID level.
The sections below describe the three main RAID storage techniques.
RAID Striping
Striping is a RAID technique that splits data into blocks and distributes the blocks between multiple disks. The system reads and writes data in parallel, resulting in improved performance.
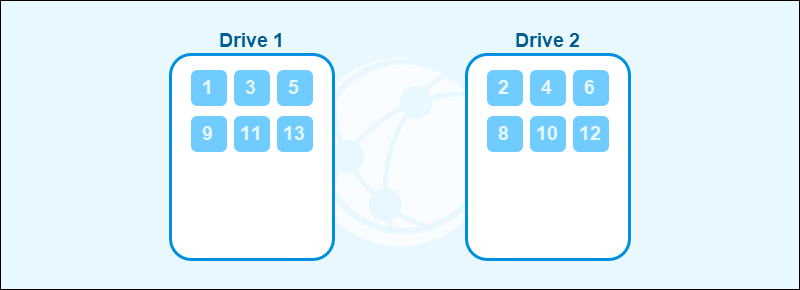
The striping mechanism improves read and write speeds, but provides no redundancy. If one drive fails, the entire array may be lost.
RAID Mirroring
Mirroring creates exact data copies on two or more disks. The technique provides fault tolerance since the system can continue operating if one drive fails.
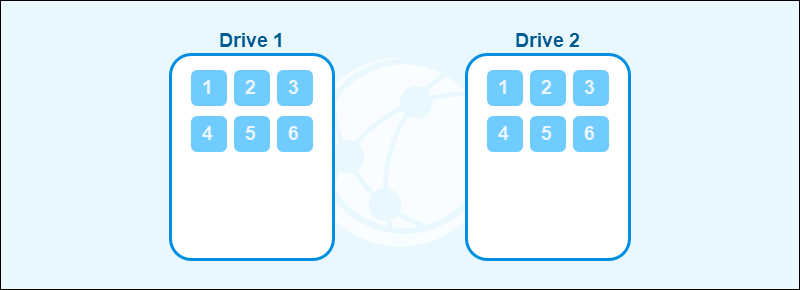
The main trade-off with mirroring is that the usable storage capacity is halved. Each additional copy increases storage costs without improving capacity.
RAID Parity
RAID parity creates redundancy by storing additional information that helps reconstruct data in case of drive failure. Parity provides less overhead than mirroring since it uses mathematical calculations to rebuild lost data and provide fault tolerance.
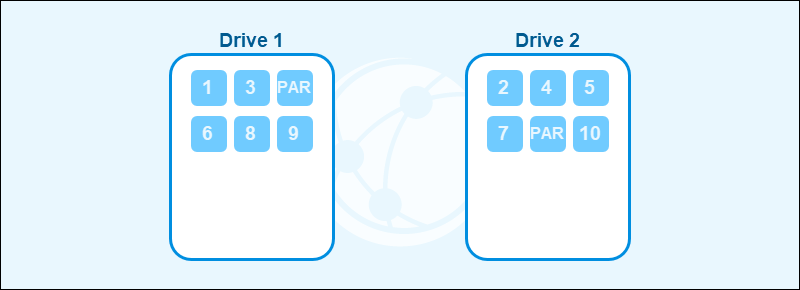
Parity balances between performance, capacity, and reliability in RAID levels.
RAID Implementation Types
There are several ways to implement RAID depending on where data processing occurs. Each method provides a different balance of cost, complexity, and performance.
The sections below describe three main implementation types.
Hardware-Based RAID
A hardware RAID setup includes a dedicated RAID controller that manages the storage array apart from the OS. The controller can be:
- Internal. A RAID controller card in a PCIe slot on the motherboard.
- External. A RAID enclosure that connects to the host.
Hardware controllers typically have a separate processor and memory to handle RAID operations efficiently without the host system's CPU. They support additional advanced features, such as battery-backed cache or hot-swapping support.
Hardware-based RAID has the best performance and reliability out of all implementations, but it's also the most expensive.
Note: If you are setting up hardware RAID, you should consider installing MegaCLI for managing and communicating with RAID controllers.
Software-Based RAID
A software-based RAID uses the host system's resources to manage the storage array. There is no dedicated controller, and the drives connect directly to the motherboard. RAID functionality is software-based (i.e., mdadm on Linux or Windows Disk Manager).
Software RAID has several advantages, including lower cost and higher configuration flexibility. It is simpler to manage for small setups. However, it also relies on the underlying system's CPU, which lowers performance under heavy load.
Firmware/Driver-Based RAID
Firmware-based RAID (often called "fake RAID") is a RAID system with a hybrid approach. They are built into the system's BIOS/UEFI and use vendor OS-level drivers. The motherboard's NVMe or SATA controller handles physical connections, while the CPU processes the RAID logic.
Consumer-grade motherboards use firmware-based RAID and require specific drivers to work correctly. They offer basic RAID levels, lack robustness, and may produce compatibility issues during OS reinstallation or migration.
RAID Levels
Apart from choosing implementation types, there are also different RAID levels. Each level applies specific storage techniques to achieve different results.
There are three RAID level categories:
- Standard RAID levels.
- Non-standard RAID levels.
- Nested/hybrid RAID levels.
The table below provides a brief overview of standard RAID levels:
| Level | Storage Technique | Fault Tolerance | Minimum Drives | Use Case |
|---|---|---|---|---|
| RAID 0 | Striping (no redundancy). | None. | 2 | High-speed data access with no redundancy (video editing). |
| RAID 1 | Mirroring | 1-drive failure. | 2 | Small critical systems (OS boot drives). |
| RAID 2 | Bit-level striping. | Multiple drive failures. | 3+ | Rarely used, historical interest. |
| RAID 3 | Byte-level striping with dedicated parity. | 1-drive failure. | 3 | Sequential data processing (old video production). |
| RAID 4 | Block-level striping with dedicated parity. | 1-drive failure. | 3 | Read-heavy applications with minimal writes (backups). |
| RAID 5 | Block-level striping with distributed parity. | 1-drive failure. | 3 | General-purpose storage (file servers). |
| RAID 6 | Block-level striping with double parity. | 2-drive failures. | 4 | High-capacity and fault-tolerant storage. |
| RAID 10 | Mirrored sets in striped array (1+0). | 1 per set. | 4 | Databases and high-performance storage. |
The following sections explain the standard RAID levels (0, 1, 2, 3, 4, 5, 6) and popular non-standard and hybrid options (RAID 10).
RAID 0 (Striping)
RAID 0, or striping, distributes data across two or more disks to form a logical volume. It improves read/write speeds by allowing operations on multiple disks simultaneously. It's ideal for performance-based tasks, like video editing, gaming, or file processing.
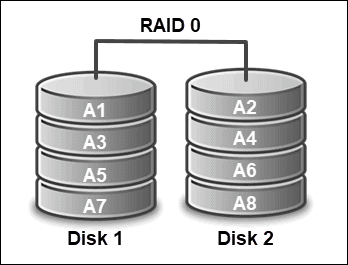
The smallest disk limits the array capacity. For example, if an array has a 320GB and a 120GB drive, the total usable space is 240GB (2x120GB). Some systems allow the use of leftover space for different purposes.
RAID 0 has no redundancy and is unsuitable for critical data storage. If one disk fails, all data is lost. Use only in cases where performance is more important than reliability.
Due to a high risk of data loss, its annual failure rate (AFR) increases with the number of drives. To calculate the AFR, use the following formula:
AFR_RAID_0 = 1 - (1 - AFR_single_disk)^n
For example, if each disk has a 3% AFR (AFR_single_disk = 0.03), the AFR for two disks (n = 2) is around 5.91%.
Note: The number reflects a probability, not a guaranteed failure rate.
Advantages
- Fastest level for read/write operations.
- No overhead (100% storage efficiency).
- Cost-effective and easy to set up.
Disadvantages
- No fault tolerance or redundancy.
- One disk failure destroys all data.
When to Use RAID 0
Temporary high-speed storage where data is backed up elsewhere or data loss is acceptable (i.e., cache storage or game installations).
RAID 1 (Mirroring)
RAID 1 duplicates data across two or more disks to create exact copies (mirrors). It prioritizes redundancy to ensure data is preserved if one drive fails. The system continues running from the mirrored copy without data loss.
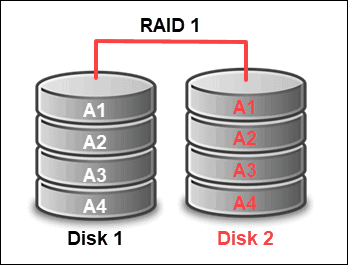
RAID 1 has excellent fault tolerance, and it's best suited for mission-critical data. The total capacity is limited to the smallest disk in the array. Write speeds are the same as using one drive, but read speeds can improve since the system can fetch data from either replica.
Since RAID 1 improves reliability, the system fails only if all drives fail. The AFR calculation changes to:
AFR_RAID_1 = AFR_single_disk^n
For example, if each disk has a 3% AFR (AFR_single_disk = 0.03), then the AFR for two disks (n = 2) is 0.09%. The setup is far more reliable than a single disk or RAID 0.
Advantages
- Fast read speeds.
- Redundancy and fault tolerance.
- Simple to configure and manage.
Disadvantages
- Uses only half of the storage capacity.
- More expensive (needs twice as many drives).
When to Use RAID 1
Use RAID 1 in critical systems where uptime and data integrity are essential (financial records, medical systems, home servers, or business workstations).
RAID 2 (Bit-Level Striping with Hamming ECC)
RAID 2 uses bit-level striping and stores error correction codes (ECC) on dedicated disks for Hamming-based ECC. The setup requires multiple drives for data and redundancy. The controller synchronizes disk operations between these units.
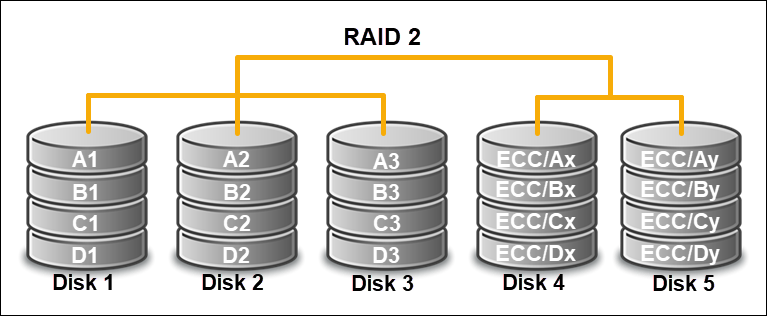
Unlike other RAID types, RAID 2 splits data into bits across disks. ECC calculations happen during writes, while reads are used to verify and correct any errors.
The setup ensures data integrity and high reliability, but it's rarely used today. Modern drives have built-in error correction, which makes RAID 2 obsolete in most cases.
It offers strong fault tolerance due to correctable errors. AFR depends on the number of ECC disks and the total array size. Typically, its implementation is comparable to RAID 5 or better.
Advantages
- Bit-level error correction.
- High data reliability.
Disadvantages
- Expensive and complex.
- Requires synchronized disk spindles.
- Obsolete.
When to Use RAID 2
RAID 2 is rare today. It's historically relevant for systems that require hardware-level data correction. Modern RAID levels replace it because newer drive technologies have built-in ECC.
RAID 3 (Byte-Level Striping with Dedicated Parity)
RAID 3 uses byte-level striping on two or more disks, and an additional dedicated parity disk for fault tolerance. Therefore, a minimum of three drives and a controller are required to manage synchronized spinning in the array.
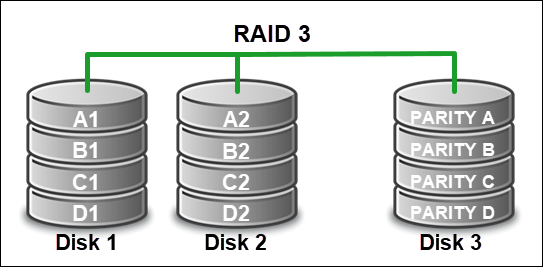
It's efficient for large and sequential data transfers, but bad at random access. The additional dedicated parity disk stores checksums to help rebuild data in case of a single drive failure.
RAID 3 tolerates one disk failure. To calculate AFR (assuming rebuild is initiated immediately after failure), use:
AFR_RAID_3 = AFR_single_disk x (n - 1)
Therefore, for three disks (n = 3) with an average disk AFR of 3% (AFR_single_disk = 0.03), the total AFR is around 6%.
Advantages
- High throughput for large, sequential data.
- Data recovery is possible after one disk failure.
Disadvantages
- Poor performance for small/random reads and writes.
- Requires synchronized disks and additional hardware.
- A single parity disk becomes a bottleneck.
When to Use RAID 3
RAID 3 is rarely used today. It was used for workloads with large sequential data transfers, such as scientific computing or video editing.
RAID 4 (Block-Level Striping with Dedicated Parity)
RAID 4 uses block-level striping on two or more disks with a dedicated parity disk for redundancy (at least three disks). The disks do not require synchronized spinning and eliminate the need for a specialized controller.
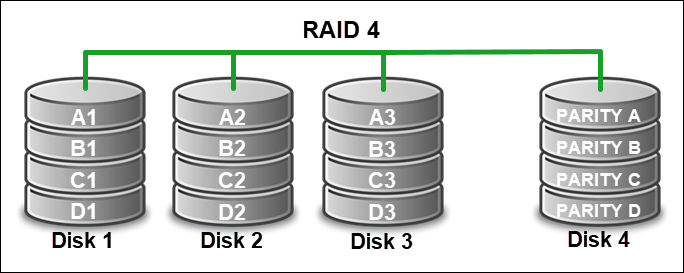
Each data block is on a separate disk, while parity information for each block is on a separate dedicated disk. This setup allows simultaneous read access and improves read performance. Write operations suffer because every operation requires updates to the same parity disk, creating a bottleneck.
RAID 4 tolerates a single disk failure. To calculate the AFR for an array, use:
AFR_RAID_4 = AFR_individual x (n-1)
For a three-disk setup (n = 3) with an average disk AFR of 3% (AFR_individual = 0.03), the AFR is around 6%. If the parity disk fails, redundancy is lost until the disk is replaced and rebuilt.
Advantages
- Fast read performance.
- Low storage overhead.
- Simultaneous read request support.
Disadvantages
- Bottlenecks on parity disk during writes.
- Slow write performance.
- The parity disk is a single point of failure.
When to Use RAID 4
RAID 4 is uncommon in modern systems. RAID 5 is a common alternative since it offers better performance and fault tolerance. It's suitable for large, sequential read-heavy workloads.
RAID 5 (Block-Level Striping with Distributed Parity)
RAID 5 combines block-level striping and distributed parity. It is the most common RAID implementation. The setup requires at least three disks and scales up to 16. Data and parity information are striped across all drives to allow recovery from a single drive failure.
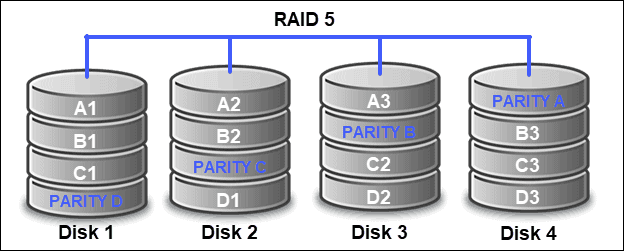
RAID 5 enables fast read performance and parallel access to drives. It provides fault tolerance through parity and minimizes storage overhead compared to RAID 1. If a disk fails, the system reconstructs data from the parity spread across the remaining disks.
RAID 5 tolerates one disk failure. If each disk has a 2% probability of failure and has three disks total, the probability of a second failure during the rebuild period is very low (but not zero).
Advantages
- High performance and capacity.
- Effiocient storage use.
- Tolerates single drive failure.
Disadvantages
- Rebuild time is lengthy and risky.
- Slower writes due to parity calculations.
- Data loss in case of simultaneous disk failure.
When to Use RAID 5
RAID 5 is ideal for file, application, and web servers. It provides a balance of performance, cost-efficiency, and fault tolerance.
RAID 6 (Block-Level Striping with Double Distributed Parity)
RAID 6 is an extension of RAID 5 with an extra parity block. The addition allows for two simultaneous disk failures. The setup is fault-tolerant because it uses block-level striping with two parity blocks per data stripe.
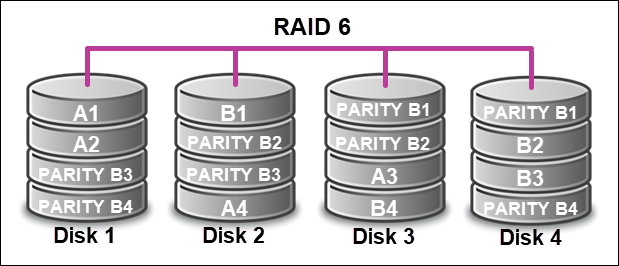
The setup requires at least four disks, but it's more efficient with six or more. Data and parity are across all drives and enable parallel read operations. Write performance is slower due to two parity block calculations and writing.
RAID 6 tolerates two disk failures. The probability of two simultaneous failures is low, so the probability of a third disk failing during rebuild is extremely low. Compared to RAID 5, it has higher reliability for larger arrays where a second failure during rebuild is possible.
Advantages
- Two drive failure tolerance.
- Storage efficiency for large arrays.
- Fast read operations.
Disadvantages
- Slow write performance.
- Long rebuild times (can be over 24h).
- More expensive due to additional parity.
When to Use RAID 6
RAID 6 is ideal for mission-critical applications where data availability and fault tolerance are essential. Examples include enterprise, banking, healthcare, and backup scenarios.
Note: RAID levels 1, 5, and 6 require a solid backup strategy.
RAID 10 (Striping over Mirrored Drives)
RAID 10 is a hybrid level that combines two different RAID levels (RAID 1 and RAID 0). This RAID array, also known as RAID 1+0, mirrors each disk and then stripes data across mirrored pairs.
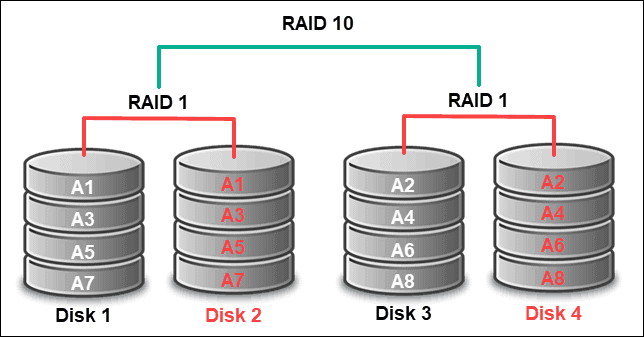
RAID 10 requires at least four disks. Half the drives store mirrored copies while striping distributes data blocks. The setup offers fast read/write speeds and high fault tolerance.
The array is functional if one drive in each mirrored pair is healthy. For total failure, all drives in a single pair must fail. It's more reliable than RAID 5/6 for heavy disk activity.
Advantages
- Suitable for I/O applications.
- High fault tolerance.
- Fast read/write performance.
- Quick rebuilds.
Disadvantages
- Expensive (50% storage capacity).
- Limited scalability.
- Requires at least four drives.
When to Use RAID 10
RAID 10 is ideal for databases, email servers, transaction-heavy applications, and web hosting environments. It provides speed, uptime, and resiliency.
Non-Standard RAID
Standard RAID levels cover typical use cases. However, evolving performance demands and newer hardware have led to non-standard RAID implementations.
Open-source communities and storage vendors typically develop these setups to address specific requirements. They are often innovative and introduce unique redundancy, performance, and scalability approaches.
Notable non-standard RAID types include:
- RAID-DP (Double Parity RAID). RAID-DP is a proprietary extension for RAID 6 developed by NetApp. It's optimized for better performance in NetApp storage systems.
- Linux MD (Multiple Device) RAID 10. A flexible variant of RAID 10 that supports mirroring and striping across any number of disks (not just multiples of four). It has different operation modes to optimize for different I/O patterns and redundancy requirements.
- RAID-Z. A RAID variation created by the ZFS file system that is similar to RAID 5 but with self-healing capabilities. It eliminates the risk of data corruption during rapid shutdowns. There are three levels (Z1-Z3) that indicate disk failure tolerance.
- Declustered RAID. The variant distributes data and parity across all drives to reduce rebuild impact when disks fail. The method speeds the I/O workload and is often used in scale-out distributed storage systems to improve availability and recovery speed.
These non-standard types are found in specialized systems where traditional RAID levels fall short. They are primarily found in enterprise NAS/SAN, cloud environments, or software-defined storage solutions.
Nested (Hybrid) RAID
Nested (or hybrid) RAID combines two or more standard RAID levels to balance redundancy, performance, and tolerance. These setups are often found in enterprise environments where all storage factors are critical.
Hybrid levels combine base RAID level numbers, and the order indicates the application hierarchy.
Common hybrid RAID levels include:
- RAID 01 (0+1). Stripes data across multiple drives and then mirrors the striped set.
- RAID 03 (0+3). Uses byte-level striping across multiple drives combined with a parity disk.
- RAID 10 (1+0). Mirrors data, then stripes it across multiple mirrored pairs.
- RAID 50 (5+0). Combines multiple RAID 5 arrays and stripes data across them.
- RAID 60 (6+0). Multiple RAID 6 arrays with striping.
- RAID 100 (1+0+0). Multiple RAID 10 arrays with striped data across them.
Nested RAID levels are tailored solutions for systems that require advanced features. The choice depends on available resources and requirements.
Conclusion
This guide explained the role of RAID in storage planning and setup. Explore all available RAID setups to see which best suits your business requirements.
To quickly evaluate a RAID configuration, use our free RAID calculator.



