
While the two metrics may sound alike, Recovery Time Objective (RTO) and Recovery Point Objective (RPO) play entirely different roles in backup and disaster recovery (BDR). Understanding the differences between these metrics (as well as how they work in tandem) is key to surviving revenue-threatening incidents without costly downtime or data loss.
This article offers a detailed RTO vs. RPO comparison that explains each metric's distinct role in business continuity (BC) planning. Read on to learn what these parameters entail (both in a technical and business sense) and see why there's no way to keep business assets safe without a well-defined RTO and RPO.
While they have similar goals, business continuity and disaster recovery are not interchangeable terms. Learn the difference between the two practices in our in-depth business continuity vs. disaster recovery comparison.
RTO vs. RPO: Main Differences
Here's what RTO and RPO stand for:
- RTO (Recovery Time Objective) is the time frame within which an asset (product, service, network, etc.) must come back online if it goes down.
- RPO (Recovery Point Objective) is the acceptable amount of data (measured by time) a company is willing to lose in case of an incident.
Both metrics are measurements of time and are vital to effective disaster recovery. Both require comprehensive planning and a proactive security mindset, but there are several noteworthy differences between RTOs and RPOs:
- RTO concentrates on app and infrastructure recovery, while RPO focuses solely on backup frequency and acceptable data losses.
- RTO considers all aspects of the business structure and the entire DR process. RPO only assesses the criticality of data and the cost of replication.
- RTO is the more complex process of the two as it involves more moving parts and variables (hot and cold sites, failovers, go-to response teams, etc.).
- An RPO relies heavily on automation to back up and restore data, while RTOs involve more manual tasks and a more hands-on approach to recovery.
- RPO is easier to calculate as the metric only covers one aspect of the recovery process: data.
- Low RPOs are far cheaper than low RTOs due to the significant difference in scope.
Together, RTOs and RPOs enable a business to know how long it can afford to be down and how recent the data will be following the recovery. Most companies prefer to bounce back from disruptions as quickly as possible; however, the shorter an RTO or RPO is, the higher the cost of recovery (and vice versa).
The best way to guarantee low RTOs and RPOs without expensive upfront investments is to rely on Disaster-Recovery-as-a-Service (DRaaS). No matter what goes wrong, DRaaS ensures you get back to business as usual in minutes rather than hours or days.
What Is RTO?
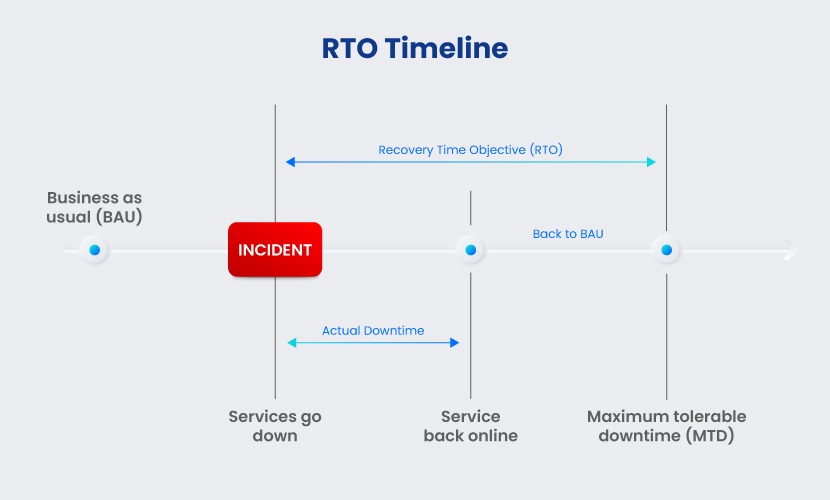
A Recovery Time Objective (RTO) represents the time frame within which an IT resource must fully recover from a disruptive event. For example, a system may have an RTO of 30 minutes. In that case, the incident response team has half an hour to restore operations following an incident.
The RTO "clock" starts ticking when the affected system goes down and ends when the system is fully operational again. Some RTOs start when the responsible team gets a notification about the incident, an approach more common for non-mission-critical systems.
Any system with a defined RTO must also measure the Recovery Time Actual (RTA). RTA represents the actual duration of the recovery process. RTAs and RTOs are rarely identical, but the goal is to keep the RTA within the expected RTO time frame (RTA ≤ RTO).
If the RTA goes past the RTO mark, you can either:
- Revisit the RTO calculation and lower the recovery threshold (an approach that often leads to IT cost reductions).
- Update your disaster recovery plan to ensure faster responses in the future.
An RTO is typically the same as the maximum downtime a system can tolerate without impacting business continuity. Every system has a different tolerance level for being offline, so there's no need to have a low RTO for every asset. For example, an HR database does not require the same recovery speed as your primary server or a firewall.
If you rely on managed IT services, the provider defines RTO expectations in the Service Level Agreement (SLA). The same document also defines all availability, response time, and resolution time metrics.
How to Calculate RTO?
There's no mathematical formula for calculating an RTO that works for every company or system type. Figuring out an optimal recovery time frame starts with an in-depth risk and business impact analysis (BIA) that examines each asset's unique traits, including:
- Consequences of the system going down (monetary, regulative, reputational, etc.).
- Overall mission-criticality (i.e., how impactful system downtime would be to other systems and end-users).
- The estimated cost of an outage (typically calculated in minutes or hours)
- Maximum tolerable period of disruption (MTPD).
- Assessed vulnerabilities currently in the system.
- The current security measures and features that protect the asset.
- Potential threats (power outages, local natural disasters, specific types of cyber attacks, etc.).
- The likelihood of the system experiencing problems.
- Industry-specific compliance implications.
Once there's an in-depth understanding of the system, the analysis team defines an optimal RTO from an IT perspective. The next step is to consult with the business unit leaders and senior management to determine whether the suggested RTO is viable from a budget standpoint.
In the case of RTOs, faster always means costlier. Any RTO that expects the system to be back online in under an hour requires a steep investment, so do not set low RTOs for every asset. Determining RTOs requires a balancing act between:
- Consequences of the system suffering downtime.
- The risk of something going wrong with the system.
- The price of setting up the recovery process.
More than 72% of companies are unable to meet their RTO expectations. Be realistic when calculating recovery speeds. An impressive RTO that your system or staff cannot meet does not make a difference in times of crisis.
What Is RPO?
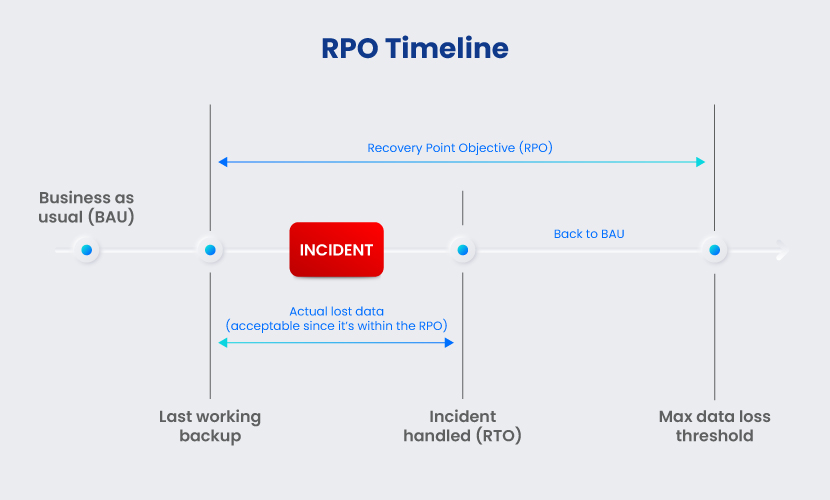
The recovery point objective (RPO) is the maximum amount of data a company is willing to lose during an incident. Teams measure RPOs in hours or minutes since the last working data backup. Once the RPO period passes in a disaster scenario, the quantity of lost data exceeds the maximum allowable threshold.
For example, if a system has an RPO of 3 hours, the team must have a working copy of data not older than 3 hours at all times. In case of a disaster, the affected system can lose up to 3 hours' worth of data without causing long-term issues.
RPOs typically do not apply to archived and historical data. This metric focuses on transactional files and updates that've recently entered a system.
The RPO dictates the frequency at which a company must create backups to ensure data loss does not exceed the tolerance threshold. The shorter the RPO, the less data is at risk of loss (either permanent or temporary).
Like with RTOs, shorter RPOs require a more significant investment than longer ones. Zero or near-zero RPOs typically require:
- High-speed backup tech (such as continuous replication and data mirroring).
- High amounts of network bandwidth to transmit data.
These measures are expensive to set up and maintain, so determining RPOs requires the team to find the middle ground between:
- The impact of data loss.
- The cost of setting up backup and recovery measures.
Any data set with an RPO should also measure the Recovery Point Actual (RPA). This metric represents the exact amount of lost data during an incident, so your RPA must be lower than or equal to the set RPO.
If your RPA fails to meet the RPO, you have two options: lower the RPO expectations or improve your data recovery strategy.
How to Calculate RPO?
Similar to RTOs, there are no universally applicable formulas for determining an RPO. Figuring out RPOs requires an in-depth analysis of each data set. Here are the primary factors:
- The financial and operational consequences of losing data.
- The number of applications that rely on the data set.
- Likelihood of incidents.
- Relevant storage regulations.
- The cost of implementing the RPO strategy.
Most companies back up their data at regular intervals (once an hour, a day, a week, etc.). Here are the four most common RPO time frames and a few usual use cases:
- Continuous or zero RPOs. Data sets that can't afford losses due to their mission-criticality, regulatory requirements, or the difficulty of recreating them. Examples include payment gateway info, patient records, and stock market trading activities.
- One to four hours. This time frame is standard for semi-critical business units with limited loss tolerance. Examples are customer chat logs, product dashboards, and password authentication systems.
- Four to twelve hours. This RPO is the go-to option for data sets that have little impact on a business if something goes wrong, such as marketing or sales statistics databases.
- Between 13 and 24 hours. Longer RPOs are a good fit for non-critical data, such as purchase orders or inventory control files.
Most data sets that do not fall under one of the categories above require weekly backups. You have two options when choosing how to back up your data:
- On-site. You store replicas on a separate computer or in a dedicated server room within your office. These backups are vulnerable to localized events that impact both primary and secondary storage.
- Off-site. Keeping data backups at a secondary facility or a third-party data center removes the danger of losing all storage solutions to a single incident. Most companies that have off-site backups rely on cloud storage.
PhoenixNAP's backup and restore solutions offer state-of-the-art tech that enables you to keep replicas in different geographic regions and meet even the strictest RPOs.

RTO vs. RPO: Vital Thresholds for Downtime and Data Loss
Predicting exactly when incidents will occur is impossible, but preparing for unfortunate events is not. Reliable RTOs and RPOs ensure you can control the aftermath of problems, minimizing disruptions that significantly impact your bottom line. These benefits make setting aside time and resources to prepare RTOs and RPOs a no-brainer decision for most companies.



