
Learning how to create a Spark DataFrame is one of the first practical steps in the Spark environment. Spark DataFrames help provide a view into the data structure and other data manipulation functions. Different methods exist depending on the data source and the data storage format of the files.
This article explains how to create a Spark DataFrame manually in Python using PySpark.

Prerequisites
- Python 3 installed and configured.
- PySpark installed and configured.
- A Python development environment ready for testing the code examples (we are using the Jupyter Notebook).
Methods for creating Spark DataFrame
There are three ways to create a DataFrame in Spark by hand:
1. Create a list and parse it as a DataFrame using the toDataFrame() method from the SparkSession.
2. Convert an RDD to a DataFrame using the toDF() method.
3. Import a file into a SparkSession as a DataFrame directly.
The examples use sample data and an RDD for demonstration, although general principles apply to similar data structures.
Note: Spark also provides a Streaming API for streaming data in near real-time. Try out the API by following our hands-on guide: Spark Streaming Guide for Beginners.
Create DataFrame from a list of data
To create a Spark DataFrame from a list of data:
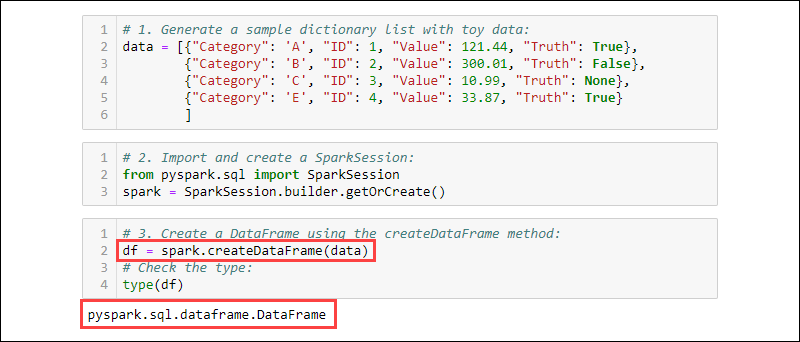
1. Generate a sample dictionary list with toy data:
data = [{"Category": 'A', "ID": 1, "Value": 121.44, "Truth": True},
{"Category": 'B', "ID": 2, "Value": 300.01, "Truth": False},
{"Category": 'C', "ID": 3, "Value": 10.99, "Truth": None},
{"Category": 'E', "ID": 4, "Value": 33.87, "Truth": True}
]
2. Import and create a SparkSession:
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
3. Create a DataFrame using the createDataFrame method. Check the data type to confirm the variable is a DataFrame:
df = spark.createDataFrame(data)
type(df)
Create DataFrame from RDD
A typical event when working in Spark is to make a DataFrame from an existing RDD. Create a sample RDD and then convert it to a DataFrame.
1. Make a dictionary list containing toy data:
data = [{"Category": 'A', "ID": 1, "Value": 121.44, "Truth": True},
{"Category": 'B', "ID": 2, "Value": 300.01, "Truth": False},
{"Category": 'C', "ID": 3, "Value": 10.99, "Truth": None},
{"Category": 'E', "ID": 4, "Value": 33.87, "Truth": True}
]
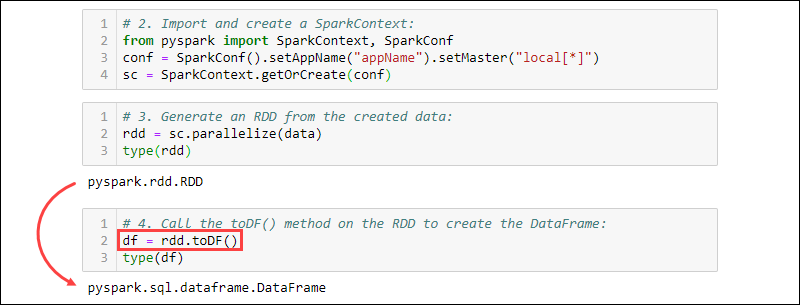
2. Import and create a SparkContext:
from pyspark import SparkContext, SparkConf
conf = SparkConf().setAppName("projectName").setMaster("local[*]")
sc = SparkContext.getOrCreate(conf)
3. Generate an RDD from the created data. Check the type to confirm the object is an RDD:
rdd = sc.parallelize(data)
type(rdd)
4. Call the toDF() method on the RDD to create the DataFrame. Test the object type to confirm:
df = rdd.toDF()
type(df)
Create DataFrame from Data sources
Spark can handle a wide array of external data sources to construct DataFrames. The general syntax for reading from a file is:
spark.read.format('<data source>').load('<file path/file name>')The data source name and path are both String types. Specific data sources also have alternate syntax to import files as DataFrames.
Creating from CSV file
Create a Spark DataFrame by directly reading from a CSV file:
df = spark.read.csv('<file name>.csv')Read multiple CSV files into one DataFrame by providing a list of paths:
df = spark.read.csv(['<file name 1>.csv', '<file name 2>.csv', '<file name 3>.csv'])By default, Spark adds a header for each column. If a CSV file has a header you want to include, add the option method when importing:
df = spark.read.csv('<file name>.csv').option('header', 'true')Individual options stacks by calling them one after the other. Alternatively, use the options method when more options are needed during import:
df = spark.read.csv('<file name>.csv').options(header = True)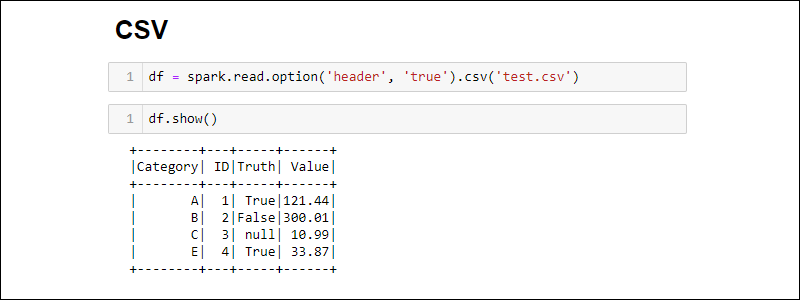
Notice the syntax is different when using option vs. options.
Creating from TXT file
Create a DataFrame from a text file with:
df = spark.read.text('<file name>.txt')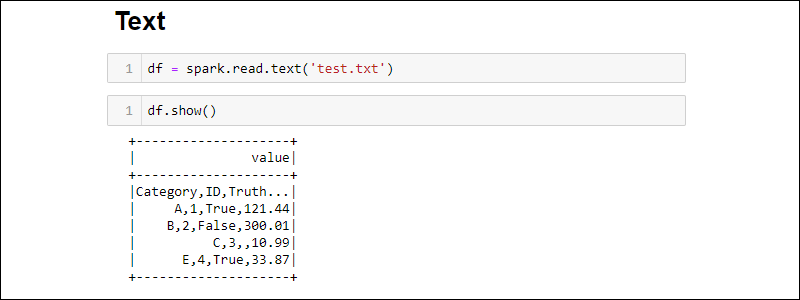
The csv method is another way to read from a txt file type into a DataFrame. For example:
df = spark.read.option('header', 'true').csv('<file name>.txt')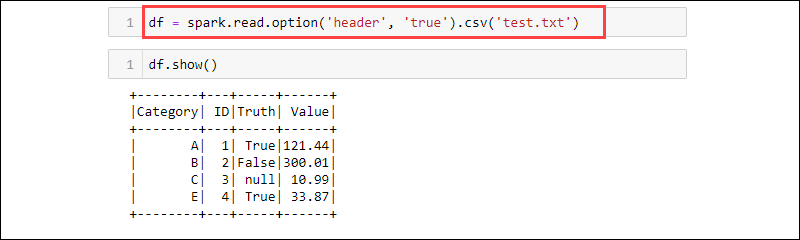
CSV is a textual format where the delimiter is a comma (,) and the function is therefore able to read data from a text file.
Creating from JSON file
Make a Spark DataFrame from a JSON file by running:
df = spark.read.json('<file name>.json')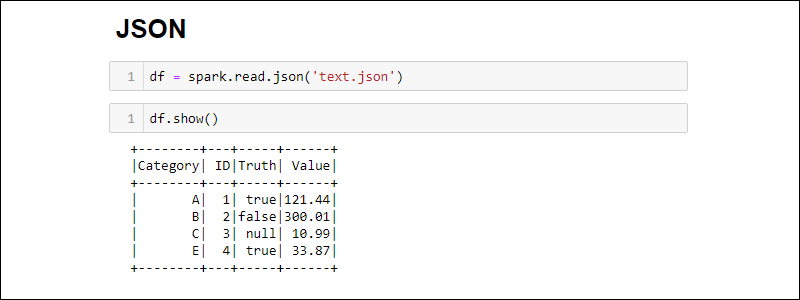
Creating from an XML file
XML file compatibility is not available by default. Install the dependencies to create a DataFrame from an XML source.
1. Download the Spark XML dependency. Save the .jar file in the Spark jar folder.
2. Read an XML file into a DataFrame by running:
df = spark.read\
.format('com.databricks.spark.xml')\
.option('rowTag', 'row')\
.load('test.xml')
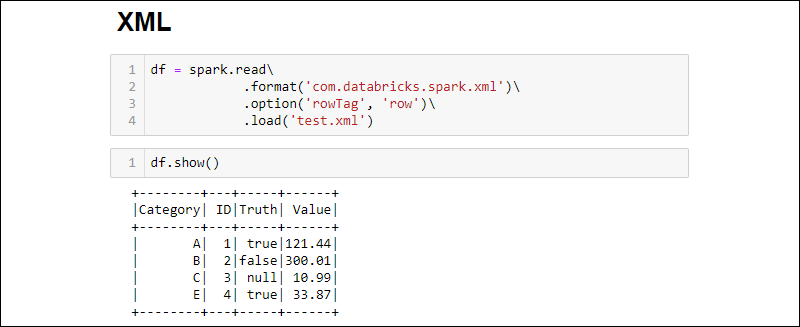
Change the rowTag option if each row in your XML file is labeled differently.
Create DataFrame from RDBMS Database
Reading from an RDBMS requires a driver connector. The example goes through how to connect and pull data from a MySQL database. Similar steps work for other database types.
1. Download the MySQL Java Driver connector. Save the .jar file in the Spark jar folder.
2. Run the SQL server and establish a connection.
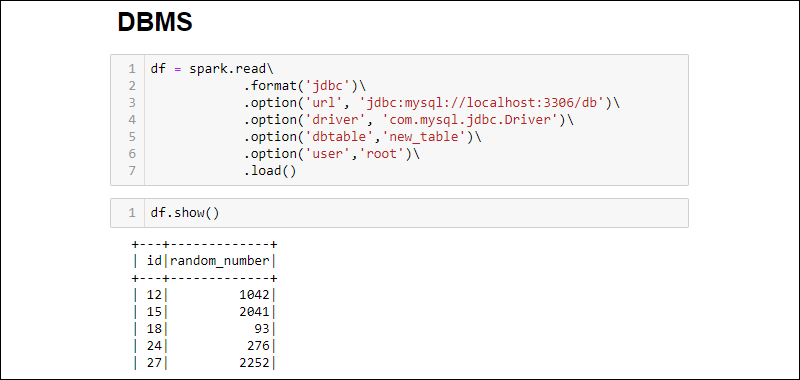
3. Establish a connection and fetch the whole MySQL database table into a DataFrame:
df = spark.read\
.format('jdbc')\
.option('url', 'jdbc:mysql://localhost:3306/db')\
.option('driver', 'com.mysql.jdbc.Driver')\
.option('dbtable','new_table')\
.option('user','root')\
.load()
Note: Need to create a database? Follow our tutorial: How to Create MySQL Database in Workbench.
The added options are as follows:
- The URL is
localhost:3306if the server runs locally. Otherwise, fetch the URL of your database server. - Database name extends the URL to access a specific database on the server. For example, if a database is named
dband the server runs locally, the full URL for establishing a connection isjdbc:mysql://localhost:3306/db. - Table name ensures the whole database table is pulled into the DataFrame. Use
.option('query', '<query>')instead of.option('dbtable', '<table name>')to run a specific query instead of selecting a whole table. - Use the username and password of the database for establishing the connection. When running without a password, omit the specified option.
Conclusion
There are various ways to create a Spark DataFrame. Methods differ based on the data source and format. Play around with different file formats and combine with other Python libraries for data manipulation, such as the Python Pandas library.
Next, learn how to handle missing data in Python by following one of our tutorials: Handling Missing Data in Python: Causes and Solutions.



