
Apache Storm and Spark are platforms for big data processing that work with real-time data streams. The core difference between the two technologies is in the way they handle data processing. Storm parallelizes task computation while Spark parallelizes data computations. However, there are other basic differences between the APIs.
This article provides an in-depth comparison of Apache Storm vs. Spark Streaming.

Storm vs. Spark: Definitions
Apache Storm is a real-time stream processing framework. The Trident abstraction layer provides Storm with an alternate interface, adding real-time analytics operations.
On the other hand, Apache Spark is a general-purpose analytics framework for large-scale data. The Spark Streaming API is available for streaming data in near real-time, alongside other analytical tools within the framework.
Storm vs. Spark: Comparison
Both Storm and Spark are free-to-use and open-source Apache projects with a similar intent. The table below outlines the main difference between the two technologies:
| Storm | Spark | |
|---|---|---|
| Programming Languages | Multi-language integration | Support for Python, R, Java, Scala |
| Processing Model | Stream processing with micro-batching available through Trident | Batch processing with micro-batching available through Streaming |
| Primitives | Tuple stream Tuple batch Partition | DStream |
| Reliability | Exactly once (Trident) At least once At most once | Exactly once |
| Fault Tolerance | Automatic restart by the supervisor process | Worker restart through resource managers |
| State Management | Supported through Trident | Supported through Streaming |
| Ease of Use | Harder to operate and deploy | Easier to manage and deploy |
Programming Languages
The availability of integration with other programming languages is one of the top factors when choosing between Storm and Spark and one of the key differences between the two technologies.
Storm
Storm has a multi-language feature, making it available for virtually any programming language. The Trident API for streaming and processing is compatible with:
- Java
- Clojure
- Scala
Spark
Spark provides high-level Streaming APIs for the following languages:
- Java
- Scala
- Python
Some advanced features, such as streaming from custom sources, are unavailable for Python. However, streaming from advanced external sources such as Kafka or Kinesis is available for all three languages.
Processing Model
The processing model defines how data streaming is actualized. The information is processed in one of the following ways:
- One record at a time.
- In discretized batches.
Storm
The processing model of core Storm operates on tuple streams directly, one record at a time, making it a proper real-time streaming technology. The Trident API adds the option to use micro-batches.
Spark
The Spark processing model divides data into batches, grouping the records before further processing. The Spark Streaming API provides the option to split data into micro-batches.
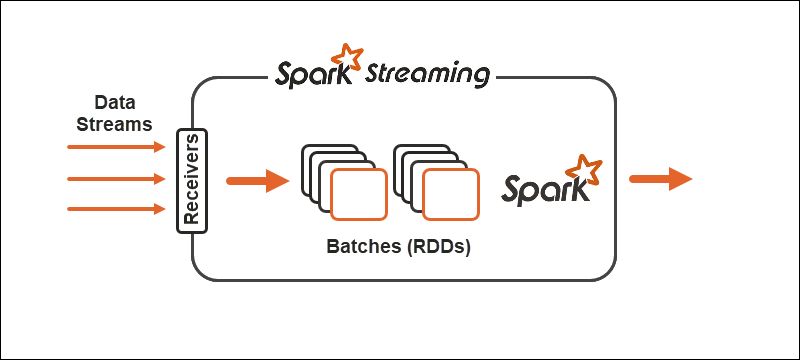
Primitives
Primitives represent the basic building blocks of both technologies and the way transformation operations execute on the data.
Storm
Core Storm operates on tuple streams, while Trident operates on tuple batches and partitions. The Trident API works on collections in a similar way comparable to high-level abstractions for Hadoop. The main primitives of Storm are:
- Spouts that generate a real-time stream from a source.
- Bolts that perform data processing and hold persistence.
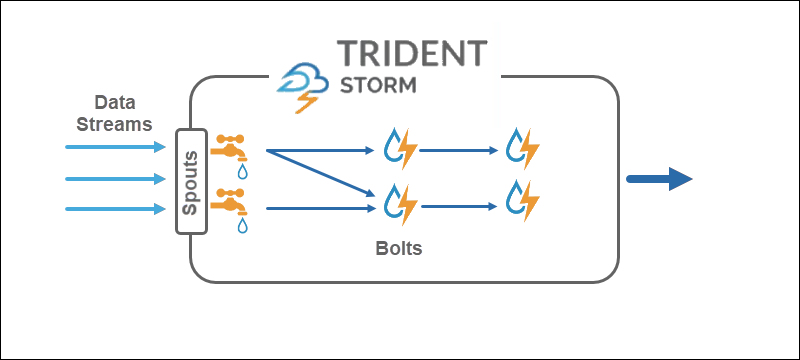
In Trident topology, operations group into bolts. Group bys, joins, aggregations, run functions, and filters are available on isolated batches and across different collections. The aggregation stores persistently in-memory backed by HDFS or in some other store like Cassandra.
Spark
With Spark Streaming, the continuous stream of data divides into discretized streams (DStreams), a sequence of Resilient Distributed Databases (RDDs).
Spark allows two general types of operators on primitives:
1. Stream transformation operators where one DStream transforms into another DStream.
2. Output operators help write information to external systems.
Note: Check out the Spark DataFrame extension for the RDD API for added efficiency.
Reliability
Reliability refers to the assurance of data delivery. There are three possible guarantees when dealing with data streaming reliability:
- At least once. Data delivers once, with multiple deliveries being a possibility as well.
- At most once. Data delivers only once, and any duplicates drop. A possibility of data not arriving exists.
- Exactly once. Data delivers once, without any losses or duplicates. The guarantee option is optimal for data streaming, although hard to achieve.
Storm
Storm is flexible when it comes to data streaming reliability. At its core, at least once and at most once options are possible. Together with the Trident API, all three configurations are available.
Spark
Spark tries to take the optimal route by focusing on the exactly-once data streaming configuration. If a worker or driver fails, at least once semantics apply.
Fault Tolerance
Fault tolerance defines the behavior of the streaming technologies in the event of failure. Both Spark and Storm are fault-tolerant at a similar level.
Spark
In case of worker failure, Spark restarts workers through the resource manager, such as YARN. Driver failure uses a data checkpoint for recovery.
Storm
If a process fails in Storm or Trident, the supervising process handles the restart automatically. ZooKeeper plays a crucial role in state recovery and management.
State Management
Both Spark Streaming and Storm Trident have built-in state management technologies. Tracking of states helps achieve fault tolerance as well as the exactly-once delivery guarantee.
Ease of Use and Development
Ease of use and development depends on how well documented the technology is and how easy it is to operate the streams.
Spark
Spark is easier to deploy and develop out of the two technologies. Streaming is well documented and deploys on Spark clusters. Stream jobs are interchangeable with batch jobs.
Note: Check out our four-step tutorial on Automated Deployment of Spark Cluster on Bare Metal Cloud.
Storm
Storm is a little trickier to configure and develop as it contains a dependency on the ZooKeeper cluster. The advantage when using Storm is due to the multi-language feature.
Storm vs. Spark: How to Choose?
The choice between Storm and Spark depends on the project as well as available technologies. One of the main factors is the programming language and the guarantees of data delivery reliability.
While there are differences between the two data streaming and processing the best path to take is to test both technologies to see what works best for you and the data stream at hand.
Conclusion
Apache Storm with the Trident API and the Spark Streaming API are similar technologies. The article provided Storm vs. Spark head-to-head comparison so you can make an informed decision.
Additionally, think about how you want to store the streamed data and the type of server resources you will need. Read about how Cassandra compares to MongoDB in our article to see which database suits you: Cassandra vs. MongoDB - What are the Differences?



