
A Spark DataFrame is an integrated data structure with an easy-to-use API for simplifying distributed big data processing. DataFrame is available for general-purpose programming languages such as Java, Python, and Scala.
It is an extension of the Spark RDD API optimized for writing code more efficiently while remaining powerful.
This article explains what Spark DataFrame is, the features, and how to use Spark DataFrame when collecting data.

Prerequisites
- Spark installed and configured (Follow our guide: How to install Spark on Ubuntu, How to install Spark on Windows 10).
- An environment configured for using Spark in Java, Python, or Scala (this guide uses Python).
What is a DataFrame?
A DataFrame is a programming abstraction in the Spark SQL module. DataFrames resemble relational database tables or excel spreadsheets with headers: the data resides in rows and columns of different datatypes.

Processing is achieved using complex user-defined functions and familiar data manipulation functions, such as sort, join, group, etc.
The information for distributed data is structured into schemas. Every column in a DataFrame contains the column name, datatype, and nullable properties. When nullable is set to true, a column accepts null properties as well.

Note: Learn how to run PySpark on Jupyter Notebook.
How Does a DataFrame Work?
The DataFrame API is a part of the Spark SQL module. The API provides an easy way to work with data within the Spark SQL framework while integrating with general-purpose languages like Java, Python, and Scala.
While there are similarities with Python Pandas and R data frames, Spark does something different. This API is tailormade to integrate with large-scale data for data science and machine learning and brings numerous optimizations.
Spark DataFrames are distributable across multiple clusters and optimized with Catalyst. The Catalyst optimizer takes queries (including SQL commands applied to DataFrames) and creates an optimal parallel computation plan.
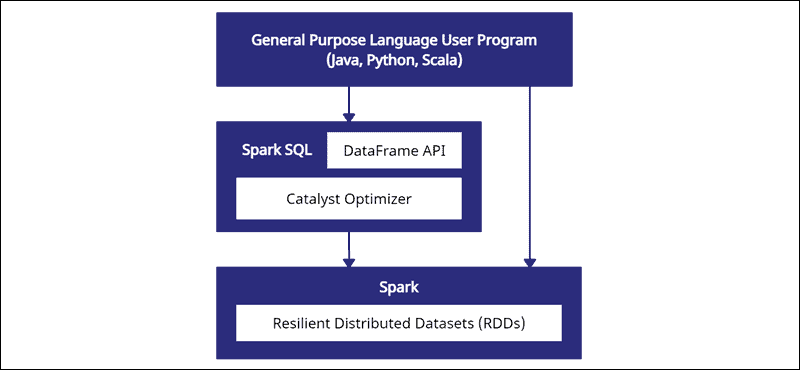
If you have Python and R data frame experience, the Spark DataFrame code looks familiar. On the other hand, if you use Spark RDDs (Resilient Distributed Dataset), having information about the data structure gives optimization opportunities.
The creators of Spark designed DataFrames to tackle big data challenges in the most efficient way. Developers can harness the power of distributed computing with familiar but more optimized APIs.
Features of Spark DataFrames
Spark DataFrame comes with many valuable features:
- Support for various data formats, such as Hive, CSV, XML, JSON, RDDs, Cassandra, Parquet, etc.
- Support for integration with various Big Data tools.
- The ability to process kilobytes of data on smaller machines and petabytes on clusters.
- Catalyst optimizer for efficient data processing across multiple languages.
- Structured data handling through a schematic view of data.
- Custom memory management to reduce overload and improve performance compared to RDDs.
- APIs for Java, R, Python, and Spark.
Note: Familiarize yourself with three different APIs for big data provided by Apache Spark in our post RDD vs. DataFrame vs. Dataset.
How to Create a Spark DataFrame?
There are multiple methods to create a Spark DataFrame. Here is an example of how to create one in Python using the Jupyter Notebook environment:
1. Initialize and create an API session:
#Add pyspark to sys.path and initialize
import findspark
findspark.init()
#Load the DataFrame API session into Spark and create a session
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()2. Create toy data as a list of dictionaries:
#Generate toy data using a dictionary list
data = [{"Category": 'A', "ID": 1, "Value": 121.44, "Truth": True},
{"Category": 'B', "ID": 2, "Value": 300.01, "Truth": False},
{"Category": 'C', "ID": 3, "Value": 10.99, "Truth": None},
{"Category": 'E', "ID": 4, "Value": 33.87, "Truth": True}
]3. Create the DataFrame using the createDataFrame function and pass the data list:
#Create a DataFrame from the data list
df = spark.createDataFrame(data)4. Print the schema and table to view the created DataFrame:
#Print the schema and view the DataFrame in table format
df.printSchema()
df.show()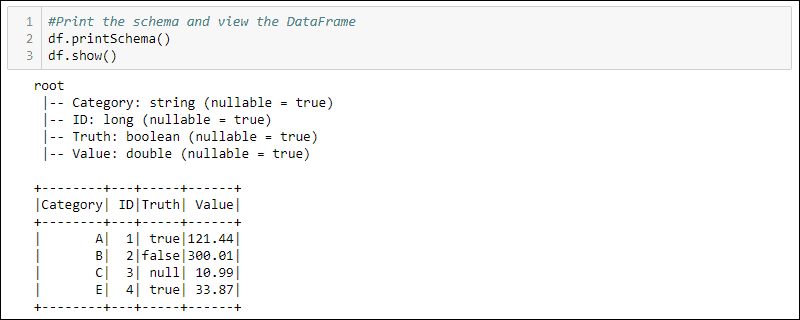
Note: For a step by step tutorial, read our article how to create a Spark DataFrame.
How to Use DataFrames
The structured data stored in a DataFrame provides two manipulation methods
- Using domain-specific language
- Using SQL queries.
The next two methods use the DataFrame from the previous example to select all rows where the Truth column is set to true and sort the data by the Value column.
Method 1: Using Domain-Specific Queries
Python provides built-in methods for filtering and sorting the data. Select the specific column using df.<column name>:
df.filter(df.Truth == True).sort(df.Value).show()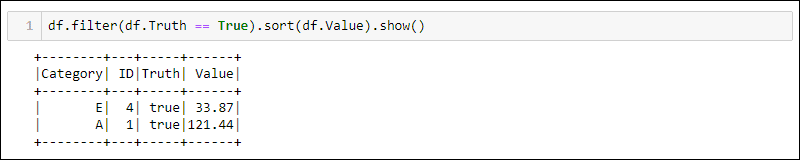
Method 2: Using SQL Queries
To use SQL queries with the DataFrame, create a view with the createOrReplaceTempView built-in method and run the SQL query using the spark.sql method:
df.createOrReplaceTempView('table')
spark.sql('''SELECT * FROM table WHERE Truth=true ORDER BY Value ASC''')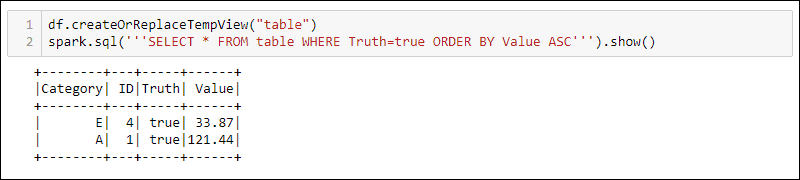
The output shows the SQL query results applied to the temporary view of the DataFrame. This allows creating multiple views and queries over the same data for complex data processing.
Note: DataFrames, along with SQL operations, are a part of Spark Streaming Operations. Learn more about it in our Spark Streaming Guide for Beginners.
Conclusion
Spark provides data structures for manipulating big data with SQL queries and programming languages such as Java, Python, and Scala. After reading this article, you know what a DataFrame is and how the data is structured.
For further reading, learn how to integrate data from different sources for advanced analytics to create complex architectures: Data Warehouse architecture.



