
Today, we have many free solutions for big data processing. Many companies also offer specialized enterprise features to complement the open-source platforms.
The trend started in 1999 with the development of Apache Lucene. The framework soon became open-source and led to the creation of Hadoop. Two of the most popular big data processing frameworks in use today are open source – Apache Hadoop and Apache Spark.
There is always a question about which framework to use, Hadoop, or Spark.
In this article, learn the key differences between Hadoop and Spark and when you should choose one or another, or use them together.

Note: Before diving into direct Hadoop vs. Spark comparison, we will take a brief look at these two frameworks.
What is Hadoop?
Apache Hadoop is a platform that handles large datasets in a distributed fashion. The framework uses MapReduce to split the data into blocks and assign the chunks to nodes across a cluster. MapReduce then processes the data in parallel on each node to produce a unique output.
Every machine in a cluster both stores and processes data. Hadoop stores the data to disks using HDFS. The software offers seamless scalability options. You can start with as low as one machine and then expand to thousands, adding any type of enterprise or commodity hardware.
The Hadoop ecosystem is highly fault-tolerant. Hadoop does not depend on hardware to achieve high availability. At its core, Hadoop is built to look for failures at the application layer. By replicating data across a cluster, when a piece of hardware fails, the framework can build the missing parts from another location.
The Apache Hadoop Project consists of four main modules:
- HDFS – Hadoop Distributed File System. This is the file system that manages the storage of large sets of data across a Hadoop cluster. HDFS can handle both structured and unstructured data. The storage hardware can range from any consumer-grade HDDs to enterprise drives.
- MapReduce. The processing component of the Hadoop ecosystem. It assigns the data fragments from the HDFS to separate map tasks in the cluster. MapReduce processes the chunks in parallel to combine the pieces into the desired result.
- YARN. Yet Another Resource Negotiator. Responsible for managing computing resources and job scheduling.
- Hadoop Common. The set of common libraries and utilities that other modules depend on. Another name for this module is Hadoop core, as it provides support for all other Hadoop components.

The nature of Hadoop makes it accessible to everyone who needs it. The open-source community is large and paved the path to accessible big data processing.
What is Spark?
Apache Spark is an open-source tool. This framework can run in a standalone mode or on a cloud or cluster manager such as Apache Mesos, and other platforms. It is designed for fast performance and uses RAM for caching and processing data.
Spark performs different types of big data workloads. This includes MapReduce-like batch processing, as well as real-time stream processing, machine learning, graph computation, and interactive queries. With easy to use high-level APIs, Spark can integrate with many different libraries, including PyTorch and TensorFlow. To learn the difference between these two libraries, check out our article on PyTorch vs. TensorFlow.
The Spark engine was created to improve the efficiency of MapReduce and keep its benefits. Even though Spark does not have its file system, it can access data on many different storage solutions. The data structure that Spark uses is called Resilient Distributed Dataset (RDD).
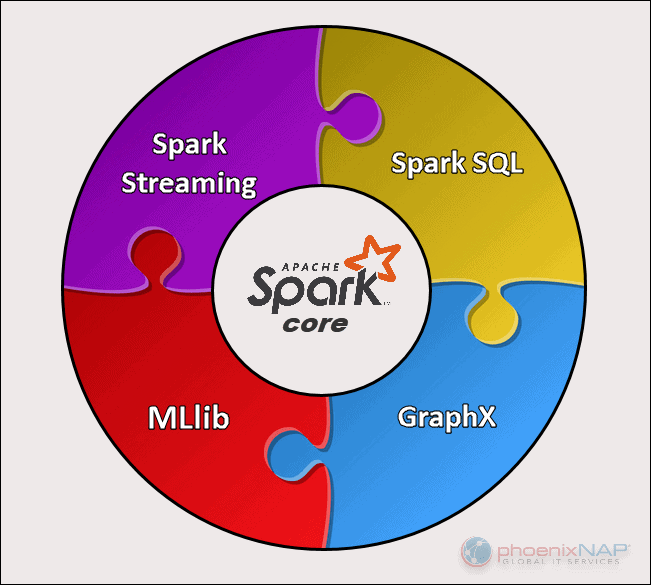
There are five main components of Apache Spark:
- Apache Spark Core. The basis of the whole project. Spark Core is responsible for necessary functions such as scheduling, task dispatching, input and output operations, fault recovery, etc. Other functionalities are built on top of it.
- Spark Streaming. This component enables the processing of live data streams. Data can originate from many different sources, including Kafka, Kinesis, Flume, etc.
- Spark SQL. Spark uses this component to gather information about the structured data and how the data is processed.
- Machine Learning Library (MLlib). This library consists of many machine learning algorithms. MLlib’s goal is scalability and making machine learning more accessible.
- GraphX. A set of APIs used for facilitating graph analytics tasks.
Note: See also how Spark compares to Storm in our article Apache Storm vs. Spark: Side-by-Side Comparison
Key Differences Between Hadoop and Spark
The following sections outline the main differences and similarities between the two frameworks. We will take a look at Hadoop vs. Spark from multiple angles.
Some of these are cost, performance, security, and ease of use.
The table below provides an overview of the conclusions made in the following sections.
Hadoop and Spark Comparison
| Category for Comparison | Hadoop | Spark |
|---|---|---|
| Performance | Slower performance, uses disks for storage and depends on disk read and write speed. | Fast in-memory performance with reduced disk reading and writing operations. |
| Cost | An open-source platform, less expensive to run. Uses affordable consumer hardware. Easier to find trained Hadoop professionals. | An open-source platform, but relies on memory for computation, which considerably increases running costs. |
| Data Processing | Best for batch processing. Uses MapReduce to split a large dataset across a cluster for parallel analysis. | Suitable for iterative and live-stream data analysis. Works with RDDs and DAGs to run operations. |
| Fault Tolerance | A highly fault-tolerant system. Replicates the data across the nodes and uses them in case of an issue. | Tracks RDD block creation process, and then it can rebuild a dataset when a partition fails. Spark can also use a DAG to rebuild data across nodes. |
| Scalability | Easily scalable by adding nodes and disks for storage. Supports tens of thousands of nodes without a known limit. | A bit more challenging to scale because it relies on RAM for computations. Supports thousands of nodes in a cluster. |
| Security | Extremely secure. Supports LDAP, ACLs, Kerberos, SLAs, etc. | Not secure. By default, the security is turned off. Relies on integration with Hadoop to achieve the necessary security level. |
| Ease of Use and Language Support | More difficult to use with less supported languages. Uses Java or Python for MapReduce apps. | More user friendly. Allows interactive shell mode. APIs can be written in Java, Scala, R, Python, Spark SQL. |
| Machine Learning | Slower than Spark. Data fragments can be too large and create bottlenecks. Mahout is the main library. | Much faster with in-memory processing. Uses MLlib for computations. |
| Scheduling and Resource Management | Uses external solutions. YARN is the most common option for resource management. Oozie is available for workflow scheduling. | Has built-in tools for resource allocation, scheduling, and monitoring. |
Performance
When we take a look at Hadoop vs. Spark in terms of how they process data, it might not appear natural to compare the performance of the two frameworks. Still, we can draw a line and get a clear picture of which tool is faster.
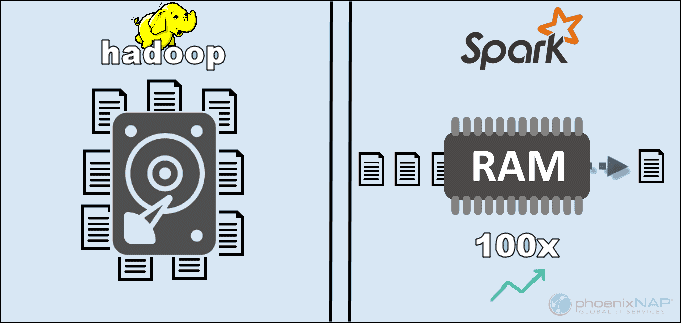
By accessing the data stored locally on HDFS, Hadoop boosts the overall performance. However, it is not a match for Spark’s in-memory processing. According to Apache’s claims, Spark appears to be 100x faster when using RAM for computing than Hadoop with MapReduce.
The dominance remained with sorting the data on disks. Spark was 3x faster and needed 10x fewer nodes to process 100TB of data on HDFS. This benchmark was enough to set the world record in 2014.
The main reason for this supremacy of Spark is that it does not read and write intermediate data to disks but uses RAM. Hadoop stores data on many different sources and then process the data in batches using MapReduce.
All of the above may position Spark as the absolute winner. However, if the size of data is larger than the available RAM, Hadoop is the more logical choice. Another point to factor in is the cost of running these systems.
Cost
Comparing Hadoop vs. Spark with cost in mind, we need to dig deeper than the price of the software. Both platforms are open-source and completely free. Nevertheless, the infrastructure, maintenance, and development costs need to be taken into consideration to get a rough Total Cost of Ownership (TCO).
The most significant factor in the cost category is the underlying hardware you need to run these tools. Since Hadoop relies on any type of disk storage for data processing, the cost of running it is relatively low.
On the other hand, Spark depends on in-memory computations for real-time data processing. So, spinning up nodes with lots of RAM increases the cost of ownership considerably.
Another concern is application development. Hadoop has been around longer than Spark and is less challenging to find software developers.
The points above suggest that Hadoop infrastructure is more cost-effective. While this statement is correct, we need to be reminded that Spark processes data much faster. Hence, it requires a smaller number of machines to complete the same task.
Data Processing
The two frameworks handle data in quite different ways. Although both Hadoop with MapReduce and Spark with RDDs process data in a distributed environment, Hadoop is more suitable for batch processing. In contrast, Spark shines with real-time processing.
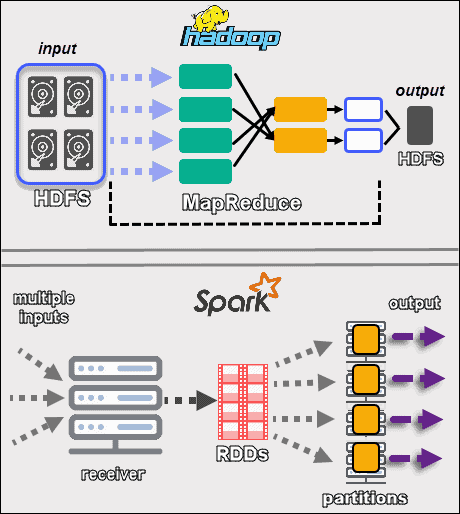
Hadoop’s goal is to store data on disks and then analyze it in parallel in batches across a distributed environment. MapReduce does not require a large amount of RAM to handle vast volumes of data. Hadoop relies on everyday hardware for storage, and it is best suited for linear data processing.
Apache Spark works with resilient distributed datasets (RDDs). An RDD is a distributed set of elements stored in partitions on nodes across the cluster. The size of an RDD is usually too large for one node to handle. Therefore, Spark partitions the RDDs to the closest nodes and performs the operations in parallel. The system tracks all actions performed on an RDD by the use of a Directed Acyclic Graph (DAG).
With the in-memory computations and high-level APIs, Spark effectively handles live streams of unstructured data. Furthermore, the data is stored in a predefined number of partitions. One node can have as many partitions as needed, but one partition cannot expand to another node.
Fault Tolerance
Speaking of Hadoop vs. Spark in the fault-tolerance category, we can say that both provide a respectable level of handling failures. Also, we can say that the way they approach fault tolerance is different.
Hadoop has fault tolerance as the basis of its operation. It replicates data many times across the nodes. In case an issue occurs, the system resumes the work by creating the missing blocks from other locations. The master nodes track the status of all slave nodes. Finally, if a slave node does not respond to pings from a master, the master assigns the pending jobs to another slave node.
Spark uses RDD blocks to achieve fault tolerance. The system tracks how the immutable dataset is created. Then, it can restart the process when there is a problem. Spark can rebuild data in a cluster by using DAG tracking of the workflows. This data structure enables Spark to handle failures in a distributed data processing ecosystem.
Scalability
The line between Hadoop and Spark gets blurry in this section. Hadoop uses HDFS to deal with big data. When the volume of data rapidly grows, Hadoop can quickly scale to accommodate the demand. Since Spark does not have its file system, it has to rely on HDFS when data is too large to handle.
The clusters can easily expand and boost computing power by adding more servers to the network. As a result, the number of nodes in both frameworks can reach thousands. There is no firm limit to how many servers you can add to each cluster and how much data you can process.
Some of the confirmed numbers include 8000 machines in a Spark environment with petabytes of data. When speaking of Hadoop clusters, they are well known to accommodate tens of thousands of machines and close to an exabyte of data.
Ease of Use and Programming Language Support
Spark may be the newer framework with not as many available experts as Hadoop, but is known to be more user-friendly. In contrast, Spark provides support for multiple languages next to the native language (Scala): Java, Python, R, and Spark SQL. This allows developers to use the programming language they prefer.
The Hadoop framework is based on Java. The two main languages for writing MapReduce code is Java or Python. Hadoop does not have an interactive mode to aid users. However, it integrates with Pig and Hive tools to facilitate the writing of complex MapReduce programs.
In addition to the support for APIs in multiple languages, Spark wins in the ease-of-use section with its interactive mode. You can use the Spark shell to analyze data interactively with Scala or Python. The shell provides instant feedback to queries, which makes Spark easier to use than Hadoop MapReduce.
Another thing that gives Spark the upper hand is that programmers can reuse existing code where applicable. By doing so, developers can reduce application-development time. Historical and stream data can be combined to make this process even more effective.
Security
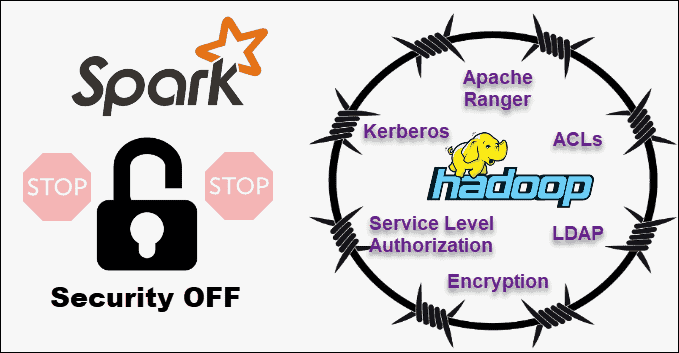
Comparing Hadoop vs. Spark security, we will let the cat out of the bag right away – Hadoop is the clear winner. Above all, Spark’s security is off by default. This means your setup is exposed if you do not tackle this issue.
You can improve the security of Spark by introducing authentication via shared secret or event logging. However, that is not enough for production workloads.
In contrast, Hadoop works with multiple authentication and access control methods. The most difficult to implement is Kerberos authentication. If Kerberos is too much to handle, Hadoop also supports Ranger, LDAP, ACLs, inter-node encryption, standard file permissions on HDFS, and Service Level Authorization.
However, Spark can reach an adequate level of security by integrating with Hadoop. This way, Spark can use all methods available to Hadoop and HDFS. Furthermore, when Spark runs on YARN, you can adopt the benefits of other authentication methods we mentioned above.
Machine Learning
Machine learning is an iterative process that works best by using in-memory computing. For this reason, Spark proved to be a faster solution in this area.
The reason for this is that Hadoop MapReduce splits jobs into parallel tasks that may be too large for machine-learning algorithms. This process creates I/O performance issues in these Hadoop applications.
Mahout library is the main machine learning platform in Hadoop clusters. Mahout relies on MapReduce to perform clustering, classification, and recommendation. Samsara started to supersede this project.
Spark comes with a default machine learning library, MLlib. This library performs iterative in-memory ML computations. It includes tools to perform regression, classification, persistence, pipeline constructing, evaluating, and many more.
Spark with MLlib proved to be nine times faster than Apache Mahout in a Hadoop disk-based environment. When you need more efficient results than what Hadoop offers, Spark is the better choice for Machine Learning.
Scheduling and Resource Management
Hadoop does not have a built-in scheduler. It uses external solutions for resource management and scheduling. With ResourceManager and NodeManager, YARN is responsible for resource management in a Hadoop cluster. One of the tools available for scheduling workflows is Oozie.
YARN does not deal with state management of individual applications. It only allocates available processing power.
Hadoop MapReduce works with plug-ins such as CapacityScheduler and FairScheduler. These schedulers ensure applications get the essential resources as needed while maintaining the efficiency of a cluster. The FairScheduler gives the necessary resources to the applications while keeping track that, in the end, all applications get the same resource allotment.
Spark, on the other hand, has these functions built-in. The DAG scheduler is responsible for dividing operators into stages. Every stage has multiple tasks that DAG schedules and Spark needs to execute.
Spark Scheduler and Block Manager perform job and task scheduling, monitoring, and resource distribution in a cluster.
Use Cases of Hadoop versus Spark
Looking at Hadoop versus Spark in the sections listed above, we can extract a few use cases for each framework.
Hadoop use cases include:
- Processing large datasets in environments where data size exceeds available memory.
- Building data analysis infrastructure with a limited budget.
- Completing jobs where immediate results are not required, and time is not a limiting factor.
- Batch processing with tasks exploiting disk read and write operations.
- Historical and archive data analysis.
With Spark, we can separate the following use cases where it outperforms Hadoop:
- The analysis of real-time stream data.
- When time is of the essence, Spark delivers quick results with in-memory computations.
- Dealing with the chains of parallel operations using iterative algorithms.
- Graph-parallel processing to model the data.
- All machine learning applications.
Note: If you’ve made your decision, you can follow our guide on how to install Hadoop on Ubuntu or how to install Spark on Ubuntu. If you are working in Windows 10, see How to Install Spark on Windows 10.
Hadoop or Spark?
Hadoop and Spark are technologies for handling big data. Other than that, they are pretty much different frameworks in the way they manage and process data.
According to the previous sections in this article, it seems that Spark is the clear winner. While this may be true to a certain extent, in reality, they are not created to compete with one another, but rather complement.
Of course, as we listed earlier in this article, there are use cases where one or the other framework is a more logical choice. In most other applications, Hadoop and Spark work best together. As a successor, Spark is not here to replace Hadoop but to use its features to create a new, improved ecosystem.
By combining the two, Spark can take advantage of the features it is missing, such as a file system. Hadoop stores a huge amount of data using affordable hardware and later performs analytics, while Spark brings real-time processing to handle incoming data. Without Hadoop, business applications may miss crucial historical data that Spark does not handle.
In this cooperative environment, Spark also leverages the security and resource management benefits of Hadoop. With YARN, Spark clustering and data management are much easier. You can automatically run Spark workloads using any available resources.
This collaboration provides the best results in retroactive transactional data analysis, advanced analytics, and IoT data processing. All of these use cases are possible in one environment.
The creators of Hadoop and Spark intended to make the two platforms compatible and produce the optimal results fit for any business requirement.
Conclusion
This article compared Apache Hadoop and Spark in multiple categories. Both frameworks play an important role in big data applications. While it seems that Spark is the go-to platform with its speed and a user-friendly mode, some use cases require running Hadoop. This is especially true when a large volume of data needs to be analyzed.
Spark requires a larger budget for maintenance but also needs less hardware to perform the same jobs as Hadoop. You should bear in mind that the two frameworks have their advantages and that they best work together.
By analyzing the sections listed in this guide, you should have a better understanding of what Hadoop and Spark each bring to the table.



