
HDFS (Hadoop Distributed File System) is a vital component of the Apache Hadoop project. Hadoop is an ecosystem of software that work together to help you manage big data. The two main elements of Hadoop are:
- MapReduce – responsible for executing tasks
- HDFS – responsible for maintaining data
In this article, we will talk about the second of the two modules. You will learn what HDFS is, how it works, and the basic HDFS terminology.

Note: If you are running an Ubuntu system and want to set up Hadoop, refer to How to Install Hadoop on Ubuntu.
What is HDFS?
Hadoop Distributed File System is a fault-tolerant data storage file system that runs on commodity hardware. It was designed to overcome challenges traditional databases couldn’t. Therefore, its full potential is only utilized when handling big data.
The main issues the Hadoop file system had to solve were speed, cost, and reliability.
What are the Benefits of HDFS?
The benefits of HDFS are, in fact, solutions that the file system provides for the previously mentioned challenges:
- It is fast. It can deliver more than 2 GB of data per second thanks to its cluster architecture.
- It is free. HDFS is an open-source software that comes with no licensing or support cost.
- It is reliable. The file system stores multiple copies of data in separate systems to ensure it is always accessible.
These advantages are especially significant when dealing with big data and were made possible with the particular way HDFS handles data.
Note: Hadoop is just one solution to big data processing. Another popular open-source framework is Spark. Want to learn more about the key differences between these big data processing solutions? Check out Hadoop Vs Spark – Detailed Comparison.
How Does HDFS Store Data?
HDFS divides files into blocks and stores each block on a DataNode. Multiple DataNodes are linked to the master node in the cluster, the NameNode. The master node distributes replicas of these data blocks across the cluster. It also instructs the user where to locate wanted information.
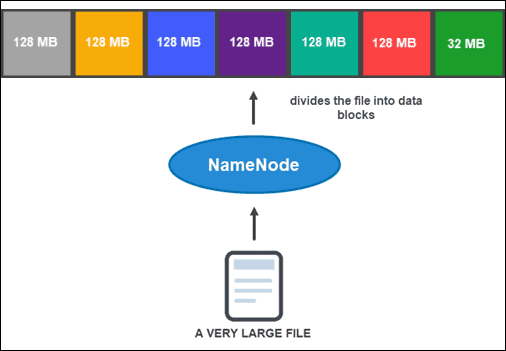
However, before the NameNode can help you store and manage the data, it first needs to partition the file into smaller, manageable data blocks. This process is called data block splitting.
Data Block Splitting
By default, a block can be no more than 128 MB in size. The number of blocks depends on the initial size of the file. All but the last block are the same size (128 MB), while the last one is what remains of the file.
For example, an 800 MB file is broken up into seven data blocks. Six of the seven blocks are 128 MB, while the seventh data block is the remaining 32 MB.
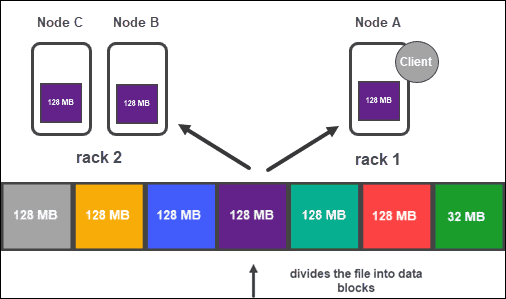
Then, each block is replicated into several copies.
Data Replication
Based on the cluster’s configuration, the NameNode creates a number of copies of each data block using the replication method.
It is recommended to have at least three replicas, which is also the default setting. The master node stores them onto separate DataNodes of the cluster. The state of nodes is closely monitored to ensure the data is always available.
To ensure high accessibility, reliability, and fault-tolerance, developers advise setting up the three replicas using the following topology:
- Store the first replica on the node where the client is located.
- Then, store the second replica on a different rack.
- Finally, store the third replica on the same rack as the second replica, but on a different node.
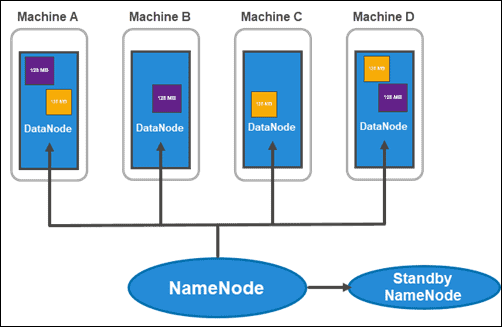
HDFS Architecture: NameNodes and DataNodes
HDFS has a master-slave architecture. The master node is the NameNode, which manages over multiple slave nodes within the cluster, known as DataNodes.
NameNodes
Hadoop 2.x introduced the possibility of having multiple NameNodes per rack. This novelty was quite significant since having a single master node with all the information within the cluster posed a great vulnerability.
The usual cluster consists of two NameNodes:
- an active NameNode
- and a stand-by NameNode
While the first one deals with all client-operations within the cluster, the second one keeps in-sync with all its work if there is a need for failover.
The active NameNode keeps track of the metadata of each data block and its replicas. This includes the file name, permission, ID, location, and number of replicas. It keeps all the information in an fsimage, a namespace image stored on the local memory of the file system. Additionally, it maintains transaction logs called EditLogs, which record all changes made on the system.
Note: Whenever a new block is added, replicated, or deleted, it gets recorded in the EditLogs.
The main purpose of the Stanby NameNode is to solve the problem of the single point of failure. It reads any changes made to the EditLogs and applies it to its NameSpace (the files and the directories in the data). If the master node fails, the Zookeeper service carries out the failover allowing the standby to maintain an active session.
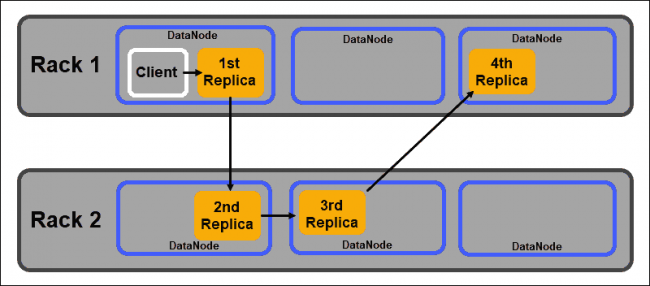
DataNodes
DataNodes are slave daemons that store data blocks assigned by the NameNode. As mentioned above, the default settings ensure each data block has three replicas. You can change the number of replicas, however, it is not advisable to go under three.
The replicas should be distributed in accordance with Hadoop’s Rack Awareness policy which notes that:
- The number of replicas has to be larger than the number of racks.
- One DataNode can store only one replica of a data block.
- One rack cannot store more than two replicas of a data block.
By following these guidelines, you can:
- Maximize network bandwidth.
- Protect against data loss.
- Improve performance and reliability.
Note: Hadoop’s scalability can be fully experienced if run on Bare Metal Cloud infrastructure, which provides hourly billing and the ability to provision thousands of servers with ease. To learn more, read What is Bare Metal Cloud.
Key Features of HDFS
These are the main characteristics of the Hadoop Distributed File System:
1. Manages big data. HDFS is excellent in handling large datasets and provides a solution that traditional file systems could not. It does this by segregating the data into manageable blocks which allow fast processing times.
2. Rack-aware. It follows the guidelines of rack awareness which ensures a system is highly available and efficient.
3. Fault tolerant. As data is stored across multiple racks and nodes, it is replicated. This means that if any of the machines within a cluster fails, a replica of that data will be available from a different node.
4. Scalable. You can scale resources according to the size of your file system. HDFS includes vertical and horizontal scalability mechanisms.
HDFS Real Life Usage
Companies dealing with large volumes of data have long started migrating to Hadoop, one of the leading solutions for processing big data because of its storage and analytics capabilities.
Financial services. The Hadoop Distributed File System is designed to support data that is expected to grow exponentially. The system is scalable without the danger of slowing down complex data processing.
Retail. Since knowing your customers is a critical component for success in the retail industry, many companies keep large amounts of structured and unstructured customer data. They use Hadoop to track and analyze the data collected to help plan future inventory, pricing, marketing campaigns, and other projects.
Telecommunications. The telecom industry manages huge amounts of data and has to process on a scale of petabytes. It uses Hadoop analytics to manage call data records, network traffic analytics, and other telecom related processes.
Energy industry. The energy industry is always on the lookout for ways to improve energy efficiency. It relies on systems like Hadoop and its file system to help analyze and understand consumption patterns and practices.
Insurance. Medical insurance companies depend on data analysis. These results serve as the basis for how they formulate and implement policies. For insurance companies, insight into client history is invaluable. Having the ability to maintain an easily accessible database while continually growing is why so many have turned to Apache Hadoop.
Note: Data stored in the HDSF is queried, managed, and analyzed by Apache Hive, a data warehouse system built on top of Hadoop. If you have an Ubuntu system and want to start using Hive, refer to How to Install Hive on Ubuntu and how to create tables in Hive.
Conclusion
After reading this article, you should have a better understanding of what HDFS is and the role it plays in the Apache Hadoop ecosystem.
If you are dealing with big data, or expect to grow to such a scale, Hadoop and HDFS can make things a lot easier.



