
MapReduce is a processing module in the Apache Hadoop project. Hadoop is a platform built to tackle big data using a network of computers to store and process data.
What is so attractive about Hadoop is that affordable dedicated servers are enough to run a cluster. You can use low-cost consumer hardware to handle your data.
Hadoop is highly scalable. You can start with as low as one machine, and then expand your cluster to an infinite number of servers. The two major default components of this software library are:
- MapReduce
- HDFS – Hadoop distributed file system
In this article, we will talk about the first of the two modules. You will learn what MapReduce is, how it works, and the basic Hadoop MapReduce terminology.

Note: If you want to start using Hadoop, follow our guide on Installing Hadoop on Ubuntu.
What is Hadoop MapReduce?
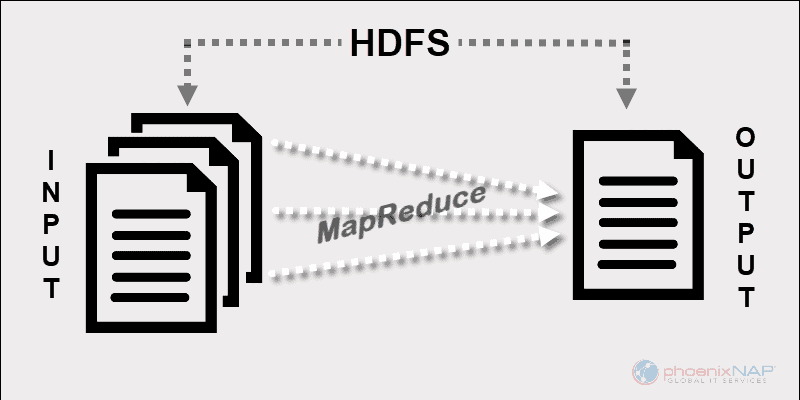
Hadoop MapReduce’s programming model facilitates the processing of big data stored on HDFS.
By using the resources of multiple interconnected machines, MapReduce effectively handles a large amount of structured and unstructured data.
Before Spark and other modern frameworks, this platform was the only player in the field of distributed big data processing.
MapReduce assigns fragments of data across the nodes in a Hadoop cluster. The goal is to split a dataset into chunks and use an algorithm to process those chunks at the same time. The parallel processing on multiple machines greatly increases the speed of handling even petabytes of data.
Distributed Data Processing Apps
This framework allows for the writing of applications for distributed data processing. Usually, Java is what most programmers use since Hadoop is based on Java.
However, you can write MapReduce apps in other languages, such as Ruby or Python. No matter what language a developer may use, there is no need to worry about the hardware that the Hadoop cluster runs on.
Scalability
Hadoop infrastructure can employ enterprise-grade servers, as well as commodity hardware. MapReduce creators had scalability in mind. There is no need to rewrite an application if you add more machines. Simply change the cluster setup, and MapReduce continues working with no disruptions.
What makes MapReduce so efficient is that it runs on the same nodes as HDFS. The scheduler assigns tasks to nodes where the data already resides. Operating in this manner increases available throughput in a cluster.
Note: If you are ready for an in-depth article on Hadoop, see Hadoop Architecture Explained (With Diagrams).
How MapReduce Works
At a high level, MapReduce breaks input data into fragments and distributes them across different machines.
The input fragments consist of key-value pairs. Parallel map tasks process the chunked data on machines in a cluster. The mapping output then serves as input for the reduce stage. The reduce task combines the result into a particular key-value pair output and writes the data to HDFS.
The Hadoop Distributed File System usually runs on the same set of machines as the MapReduce software. When the framework executes a job on the nodes that also store the data, the time to complete the tasks is reduced significantly.
Basic Terminology of Hadoop MapReduce
As we mentioned above, MapReduce is a processing layer in a Hadoop environment. MapReduce works on tasks related to a job. The idea is to tackle one large request by slicing it into smaller units.
JobTracker and TaskTracker
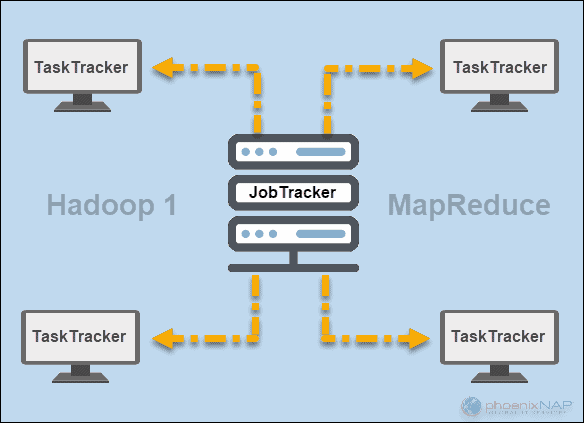
In the early days of Hadoop (version 1), JobTracker and TaskTracker daemons ran operations in MapReduce. At the time, a Hadoop cluster could only support MapReduce applications.
A JobTracker controlled the distribution of application requests to the compute resources in a cluster. Since it monitored the execution and the status of MapReduce, it resided on a master node.
A TaskTracker processed the requests that came from the JobTracker. All task trackers were distributed across the slave nodes in a Hadoop cluster.
YARN
Later in Hadoop version 2 and above, YARN became the main resource and scheduling manager. Hence the name Yet Another Resource Manager. Yarn also worked with other frameworks for the distributed processing in a Hadoop cluster.
MapReduce Job
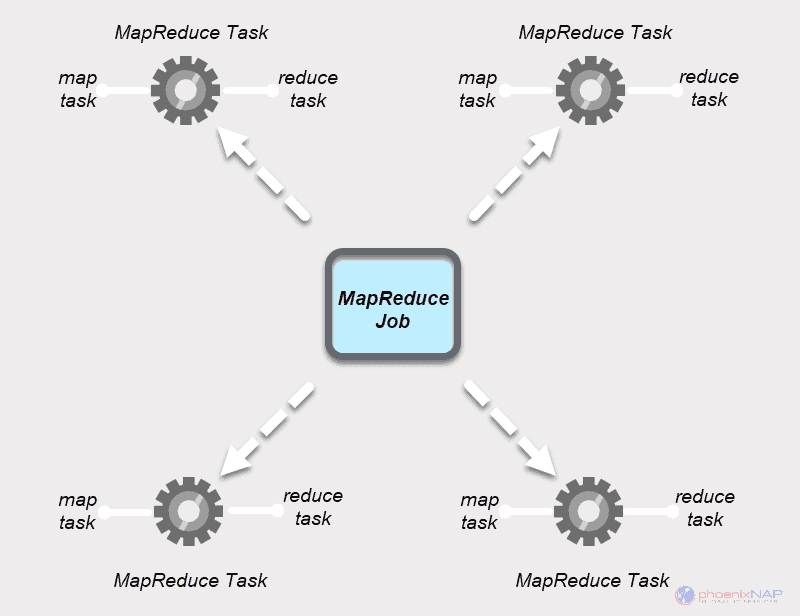
A MapReduce job is the top unit of work in the MapReduce process. It is an assignment that Map and Reduce processes need to complete. A job is divided into smaller tasks over a cluster of machines for faster execution.
The tasks should be big enough to justify the task handling time. If you divide a job into unusually small segments, the total time to prepare the splits and create tasks may outweigh the time needed to produce the actual job output.
MapReduce Task
MapReduce jobs have two types of tasks.
A Map Task is a single instance of a MapReduce app. These tasks determine which records to process from a data block. The input data is split and analyzed, in parallel, on the assigned compute resources in a Hadoop cluster. This step of a MapReduce job prepares the <key, value> pair output for the reduce step.
A Reduce Task processes an output of a map task. Similar to the map stage, all reduce tasks occur at the same time, and they work independently. The data is aggregated and combined to deliver the desired output. The final result is a reduced set of <key, value> pairs which MapReduce, by default, stores in HDFS.
Note: The Reduce stage is not always necessary. Some MapReduce jobs do not require the combining of data from the map task outputs. These MapReduce Applications are called map-only jobs.
The Map and Reduce stages have two parts each.
The Map part first deals with the splitting of the input data that gets assigned to individual map tasks. Then, the mapping function creates the output in the form of intermediate key-value pairs.
The Reduce stage has a shuffle and a reduce step. Shuffling takes the map output and creates a list of related key-value-list pairs. Then, reducing aggregates the results of the shuffling to produce the final output that the MapReduce application requested.
How Hadoop Map and Reduce Work Together
As the name suggests, MapReduce works by processing input data in two stages – Map and Reduce. To demonstrate this, we will use a simple example with counting the number of occurrences of words in each document.
The final output we are looking for is: How many times the words Apache, Hadoop, Class, and Track appear in total in all documents.
For illustration purposes, the example environment consists of three nodes. The input contains six documents distributed across the cluster. We will keep it simple here, but in real circumstances, there is no limit. You can have thousands of servers and billions of documents.
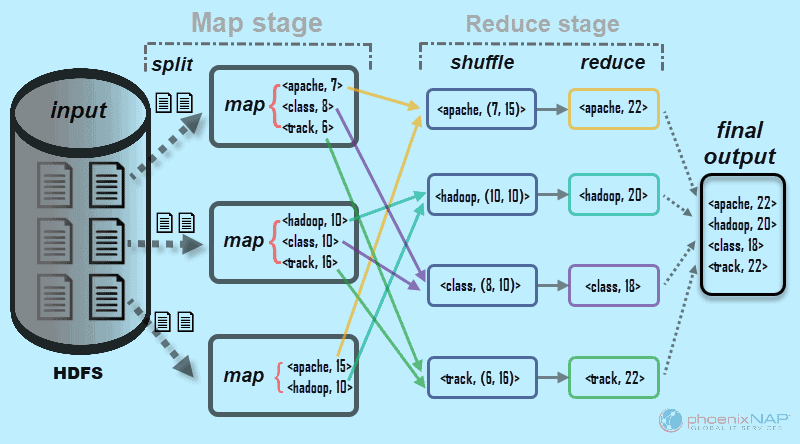
1. First, in the map stage, the input data (the six documents) is split and distributed across the cluster (the three servers). In this case, each map task works on a split containing two documents. During mapping, there is no communication between the nodes. They perform independently.
2. Then, map tasks create a <key, value> pair for every word. These pairs show how many times a word occurs. A word is a key, and a value is its count. For example, one document contains three of four words we are looking for: Apache 7 times, Class 8 times, and Track 6 times. The key-value pairs in one map task output look like this:
- <apache, 7>
- <class, 8>
- <track, 6>
This process is done in parallel tasks on all nodes for all documents and gives a unique output.
3. After input splitting and mapping completes, the outputs of every map task are shuffled. This is the first step of the Reduce stage. Since we are looking for the frequency of occurrence for four words, there are four parallel Reduce tasks. The reduce tasks can run on the same nodes as the map tasks, or they can run on any other node.
The shuffle step ensures the keys Apache, Hadoop, Class, and Track are sorted for the reduce step. This process groups the values by keys in the form of <key, value-list> pairs.
4. In the reduce step of the Reduce stage, each of the four tasks process a <key, value-list> to provide a final key-value pair. The reduce tasks also happen at the same time and work independently.
In our example from the diagram, the reduce tasks get the following individual results:
- <apache, 22>
- <hadoop, 20>
- <class, 18>
- <track, 22>
Note: The MapReduce process is not necessarily successive. The Reduce stage does not have to wait for all map tasks to complete. Once a map output is available, a reduce task can begin.
5. Finally, the data in the Reduce stage is grouped into one output. MapReduce now shows us how many times the words Apache, Hadoop, Class, and track appeared in all documents. The aggregate data is, by default, stored in the HDFS.
The example we used here is a basic one. MapReduce performs much more complicated tasks.
Some of the use cases include:
- Turning Apache logs into tab-separated values (TSV).
- Determining the number of unique IP addresses in weblog data.
- Performing complex statistical modeling and analysis.
- Running machine-learning algorithms using different frameworks, such as Mahout.
How Hadoop Partitions Map Input Data
The partitioner is responsible for processing the map output. Once MapReduce splits the data into chunks and assigns them to map tasks, the framework partitions the key-value data. This process takes place before the final mapper task output is produced.
MapReduce partitions and sorts the output based on the key. Here, all values for individual keys are grouped, and the partitioner creates a list containing the values associated with each key. By sending all values of a single key to the same reducer, the partitioner ensures equal distribution of map output to the reducer.
Note: The number of map output files depends on the number of different partitioning keys and the configured number of reducers. That amount of reducers is defined in the reducer configuration file.
The default partitioner well-configured for many use cases, but you can reconfigure how MapReduce partitions data.
If you happen to use a custom partitioner, make sure that the size of the data prepared for every reducer is roughly the same. When you partition data unevenly, one reduce task can take much longer to complete. This would slow down the whole MapReduce job.
Conclusion
The challenge with handling big data was that traditional tools were not ready to deal with the volume and complexity of the input data. That is where Hadoop MapReduce came into play.
The benefits of using MapReduce include parallel computing, error handling, fault-tolerance, logging, and reporting. This article provided the starting point in understanding how MapReduce works and its basic concepts.



