
Cassandra is an open-source distributed database software for handling NoSQL databases. This software uses CQL (Cassandra Query Language) as the basis for communication. CQL keeps data in tables arranged in a set of rows with columns that contain key-value pairs.
CQL tables are grouped in data containers called keyspaces in Cassandra. Data stored in one keyspace is unrelated to other data in the cluster. So, you can have tables for multiple different purposes in separate keyspaces in a cluster, and the data will not coincide.
In this guide, you will learn how to create a Cassandra table for a few different purposes, and how to alter, drop, or truncate tables using the Cassandra shell.

Note: Learn how Cassandra works in our Cassandra vs MongoDB comparison article.
Prerequisites
- Cassandra database software installed on your system
- Access to a terminal or command-line tool to load cqlsh
- A user with the necessary permissions to execute the commands
Selecting Keyspace for Cassandra Table
Before you start adding a table, you need to determine the keyspace where you want to create your table. There are two options to do this.
Option 1: The USE Command
Run the USE command to select a keyspace to which all your commands will apply. To do that, in the cqlsh shell type:
USE keyspace_name;Then, you can start adding tables.
Option 2: Specify the Keyspace Name in the Query
The second option is to specify the keyspace name in the query for table creation. The first part of the command, before column names and options, looks like this:
CREATE TABLE keyspace_name.table_nameThis way, you immediately create a table in the keyspace you defined.
Basic Syntax for Creating Cassandra Tables
Creating tables using CQL looks similar to SQL queries. In this section, we will show you the basic syntax for creating tables in Cassandra.
The basic syntax for creating a table looks like this:
CREATE TABLE tableName (
columnName1 dataType,
columnName2 dataType,
columnName2 datatype
PRIMARY KEY (columnName)
);Optionally, you can define additional table properties and values using WITH:
WITH propertyName=propertyValue;For example, use it to define how to store the data on disk or whether to use compression.
Cassandra Primary Key Types
Every table in Cassandra needs to have a primary key, which makes a row unique. With primary keys, you determine which node stores the data and how it partitions it.
There are two types of primary keys:
- Simple primary key. Contains only one column name as the partition key to determine which nodes will store the data.
- Compound primary key. Uses one partitioning key and multiple clustering columns to define where to store the data and how to sort it on a partition.
- Composite partition key. In this case, there are several columns that determine where to store data. This way, you can break data into smaller pieces to distribute it across multiple partitions to avoid hotspotting.
How to Create Cassandra Table
The following sections explain how to create tables with different types of primary keys. First, select a keyspace where you want to create a table. In our case:
USE businesinfo;Every table contains columns and a Cassandra data type for every entry.
Create Table with Simple Primary Key
The first example is a basic table with suppliers. The ID is unique for every supplier, and it will serve as the primary key.
The CQL query looks like this:
CREATE TABLE suppliers (
supp_id int PRIMARY KEY,
supp_city text,
supp_email text,
supp_fee int,
supp_name text,
supp_phone int
);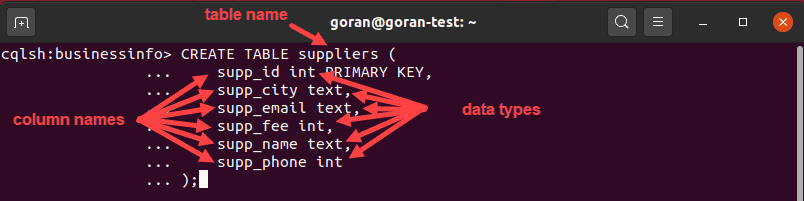
This query created a table called supplier with supp_id as the primary key for the table. When you use a simple primary key with the column name as the partition key, you can either put it at the beginning of the query (next to the column that will serve as the primary key) or at the bottom and then specify the column name:
CREATE TABLE suppliers (
supp_id int,
supp_city text,
supp_email text,
supp_fee int,
supp_name text,
supp_phone int
PRIMARY KEY(supp_id)
);To see if the table is in the keyspace, type in:
DESCRIBE TABLES;The output lists all tables in that keyspace along with the one you created.

To show the contents of the tables, enter:
SELECT * FROM suppliers;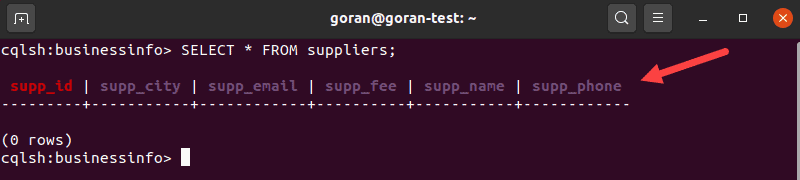
The output shows all columns defined while creating a table.
Another way to see the details of a table is to use DESCRIBE and specify a table name:
DESCRIBE suppliers;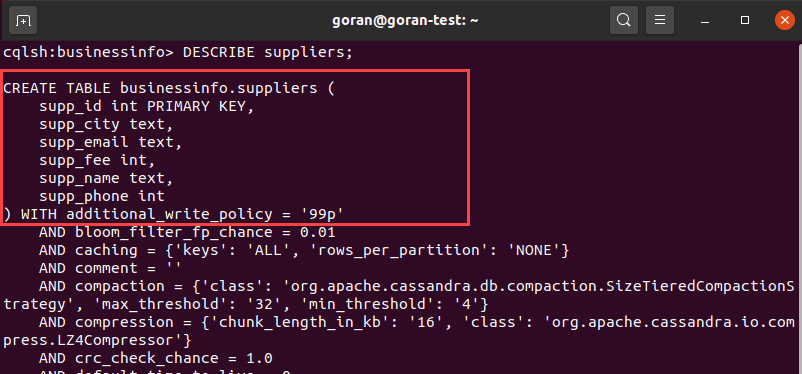
The output displays the columns and the default settings for the table.
Create Table with Compound Primary Key
To query and get the results sorted in a specific order, create a table with a compound primary key.
For example, create a table for suppliers and all the products they offer. Since the products may not be unique for each supplier, you need to add one or more clustering columns in the primary key to make it unique.
The table schema looks like this:
CREATE TABLE suppliers_by_product (
supp_product text,
supp_id int,
supp_product_quantity text,
PRIMARY KEY(supp_product, supp_id)
);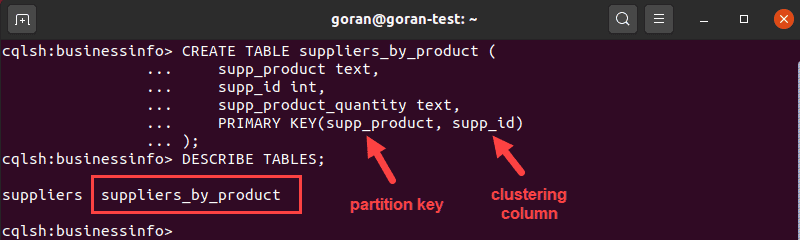
In this case, we used supp_product and supp_id to create a unique compound key. Here, the first entry in the brackets supp_product is the partition key. It determines where to store the data, that is, how the system partitions the data.
The next entry is the clustering column that determines how Cassandra sorts the data, in our case this is by supp_id.
The image above shows the table was created successfully. To check the table details, run the DESCRIBE TABLE query for the new table:
DESCRIBE TABLE suppliers_by_product;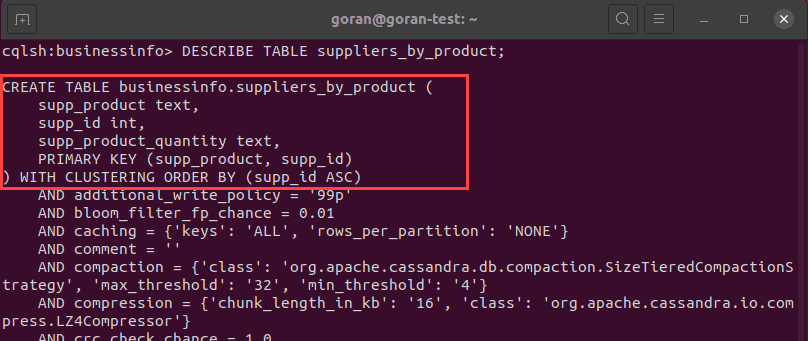
The default settings for the clustering order is ascending (ASC). You can change to descending (DESC) by adding the following statement after the primary key:
WITH CLUSTERING ORDER BY (supp_id DESC);We specified one clustering column after the partition key. In case you need to sort the data using two columns, append another column inside the primary key brackets.
Create Tables Using Composite Partition Key
Creating a table with a composite partition key is helpful when one node stores a high volume of data, and you want to split the load on multiple nodes.
In this case, define a primary key with a partition key that consists of multiple columns. You need to use double brackets. Then, add clustering columns as we did previously to create a unique primary key.
For example:
CREATE TABLE suppliers_by_product_type (
supp_product_consume text,
supp_product_stock text,
supp_id int,
supp_name text,
PRIMARY KEY((supp_product_consume, supp_product_stock), supp_id)
);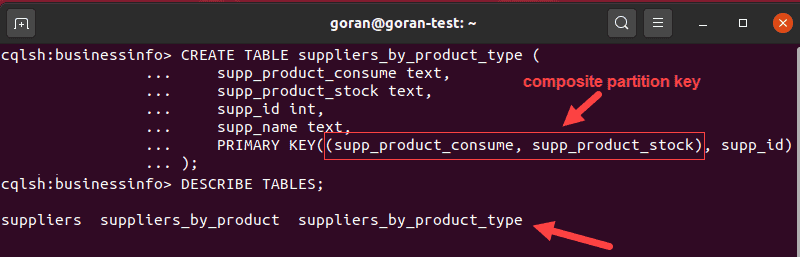
In the example above, we separated the data into two categories, supplier consumable products, and stockable products, and distributed the data using a composite partition key.
Note: With this kind of partitioning, each product category is stored on a separate node instead of having all products on one partition.
If you use a compound primary key with a simple partition key and multiple clustering columns instead, then one node would handle all the data sorted by multiple columns.
Cassandra Drop Table
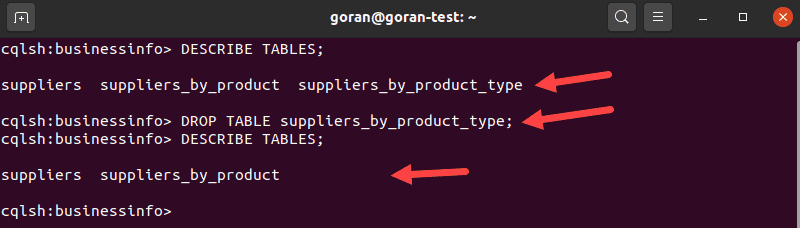
To delete a table in Cassandra, use the DROP TABLE statement. To choose a table you want to delete, enter:
DESCRIBE TABLES;Find the table you want to drop. Use the table’s name to remove it:
DROP TABLE suppliers_by_product_type;Run the DESCRIBE TABLES query again to verify you deleted the table successfully.
Cassandra Alter Table
Cassandra CQL allows you to add or remove columns from a table. Use the ALTER TABLE command to make changes to a table.
Add a Column to a Table
Before adding a column to a table, we suggest you view the contents of the table to verify the column name does not exist already.
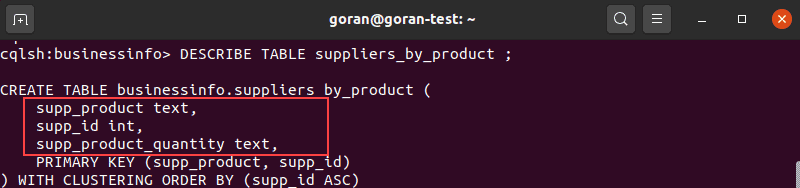
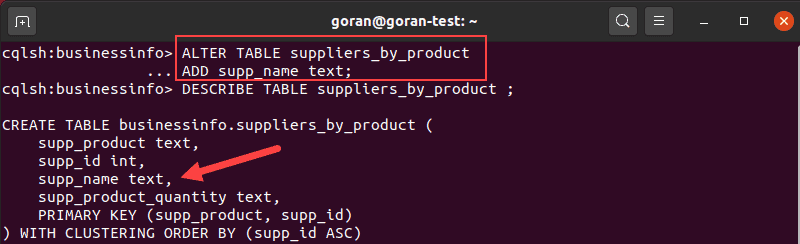
Once you verify, use the ALTER TABLE query in this format to add a column:
ALTER TABLE suppliers_by_product
ADD supp_name text;Describe the table to confirm the column appears on the list.
Delete a Column from a Table
Similar to adding a column, you can drop a column from a table. Locate the column you want to remove by using DESCRIBE TABLES query.
Then enter:
ALTER TABLE suppliers_by_product
DROP supp_product_quantity;Note: Do not specify the data type for the column when you want to remove it from a table. An error occurs if you do: “SyntaxException: line 1:48 mismatched input ‘text’ expecting EOF (ALTER TABLE suppliers_by_product DROP supp_name [text]…)”
Cassandra Truncate Table
If you do not want to delete an entire table, but you need to remove all rows, use the TRUNCATE command.
For example, to delete all rows from the table suppliers, enter:
TRUNCATE suppliers;To verify there are no rows in your table anymore, use the SELECT statement.
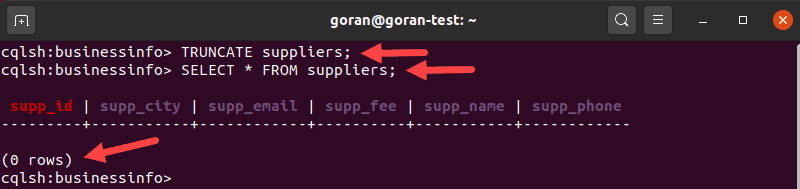
Once you truncate a table, the changes are permanent, so be careful when using this query.
Conclusion
This tutorial showed you how to create tables in Cassandra for different purposes using the simple and compound primary keys. The examples also included the usage of a composite partition key to distribute the data across the nodes.
We also covered how you can delete, alter, and truncate tables in Cassandra. Make sure you are dropping or making changes to the right tables to avoid potential issues.



