
The need to capture and process big data is the main driving force behind NoSQL database popularity. The stored data must be accessible at all times, from any location, and on any device. One way to cater to the growing demand is to scale up and buy a bigger server. However, it is more efficient to scale out and use a cluster of on-demand servers.
The relational database model is not well-suited for a distributed system spanning multiple machines. NoSQL databases provide a viable solution by focusing on performance and availability while also sacrificing some of the consistency usually identified with relational databases.
Aside from answering the question “What is NoSQL”, this tutorial uses straightforward examples to highlight basic NoSQL concepts, features, and types.

What is NoSQL? (NoSQL Definition)
NoSQL (Not SQL or Not Only SQL) is a generic term used for databases that do not depend on a relational model. The data does not need to have a strict schema nor the usual SQL table structure. Most commonly, the data is aggregated as key-value pairs, JSON documents, graphs, or wide-column tables.
By using NoSQL databases, you can store immense volumes of unstructured data as it comes in and structure it at a later point. As expected, this leads to much better throughput, read/write speeds, and allows you to scale out servers horizontally.
Non-relational databases, when applied in the right use-case environment, bring significant benefits in terms of performance and flexibility. However, not applying a schema at the data entry point also means it is more difficult to query NoSQL databases, maintain data consistency, and establish relationships between data sets.
How NoSQL Works
The basic idea behind NoSQL is to optimize the database performance for horizontal scaling, large data volumes, and low latency by forgoing some data consistency restrictions present in RDBMSs. Instead of rigid data models such as tables, columns, or rows, NoSQL databases offer flexible models. In use cases that do not require relational consistency, these models help NoSQLs perform better than relational databases.
Note: Learn more about NoSQL database modelling techniques.
Features of NoSQL Databases
NoSQL databases are structurally diverse and offer various data storage models. There are, however, several common attributes that distinguish NoSQL from relational databases.
Schema on Read
A NoSQL database allows you to store data before applying a structure or schema.
The schema is applied by the application code only when it accesses data. This process is often referred to as schema on read. By not structuring data in advance, NoSQL databases can write and read immense volumes of data significantly faster than a relational database can.
NoSQL vs Relational Databases
In contrast, an SQL relational model, structures incoming data before it is written to a database. Predefined schema design is used to classify all the possible data types in advance. The schema is applied across the board as data is structured and stored within tables, columns, and rows.
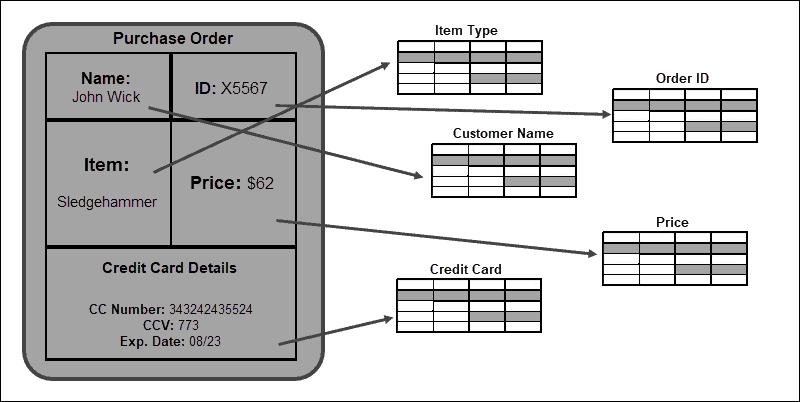
The strict tabular structure is an advantage when establishing relationships between tables and database elements. The consistency and integrity of the data are guaranteed by complying with this schema.
Note: For an in-depth comparison of relational and NoSQL databases, please refer to our article SQL vs NoSQL.
Non-Relational Data Model
NoSQL databases do not establish relationships between individual records. One record is usually stored as an individual JSON document and replicated across multiple nodes in a cluster.
We’ll use a simple example involving data about music bands. In a non-relational model, the BandID, Band Name, Country, Genre, Label, AlbumID, Album Name, and Release Date attributes are stored in a single Radiohead document. If you need to find the release date for the Radiohead album, OK Computer, the response is lightning fast. The query provides results much quicker as it does not need to retrieve information from multiple tables (as in relational databases), but rather from a single entry.
The aggregated data in one record cannot be related to the aggregated data in another record. Each relevant record in the database needs to be updated if you want to add an attribute such as a streaming service. NoSQL databases are, therefore, best suited for large volumes of data that do not need to be structured or related at a later point.
BASE vs ACID
Does a database need to cancel an operation and ensure data consistency in case of network failure? Or should databases risk data inconsistencies to ensure high availability?
NoSQL’s primary focus is to maintain availability by offering eventual consistency. Eventual consistency is part of BASE semantics. BASE states that once data is written, it will eventually appear for reading. Without strong guarantees, you only have a limited probability of knowing the current state, as it may not yet have converged. If the system is functioning and you wait long enough after any given set of inputs, you will eventually know the true state of the database.
The downside is that data may not persist after conflicts are reconciled. A read may not get the latest write for an unknown period. A Facebook post not showing up for a few minutes is acceptable, but not being able to see a financial transaction straight away is a significant issue.
ACID
- Atomicity. Only the specified data is affected by an operation.
- Consistency. Each operation moves the database from one consistent state to another consistent state.
- Isolation. One operation does not affect other concurrent operations.
- Durability. The data does not get lost following a successful transaction.
BASE
- Basically Available. Writing and reading operations are available as much as possible but without any strict guarantees.
- Soft State. Without guarantees, we do not know but have expectations that the data eventually becomes consistent.
- Eventual Consistency. If the system is fully functional, and a long enough period has passed, we will eventually know the true state of the database.
Relational databases focus on consistency as the more important feature to maintain. The consistency property of a database ensures that if you write a record to a database and then immediately request that record, you are guaranteed to see it. The ACID set of properties, applied by relational databases, means that once data is written, you have full consistency in reads.
Learn more about the two most popular database transaction models and their differences in the ACID vs BASE article.
Horizontal Scaling
Companies have found effective ways to cash in on data. The rapid growth of the volume, velocity, and variety of that data has led to the surge of NoSQL databases.
Major websites and online platforms needed to overcome some of the limitations of relational databases, such as read/write speeds and the need to normalize data in advance. One significant limitation is the inflexibility of the relational model when it comes to scaling out. In a relational model, data is typically not partitioned or segregated. Instead, it is concentrated on a single node, and databases can only scale up by increasing the power of existing hardware.
NoSQL databases are designed to run efficiently on distributed systems that quickly scale out horizontally. A distributed system has the additional benefit of providing constant high availability. Multiple replicas of a record are kept across servers and racks, and hardware failure does not affect data availability. You can safely use commodity hardware instead of expensive high-end servers to manage soaring data loads.
Types of NoSQL Databases
Non-relational database models can broadly be classified into four categories.
- A key-value store allows you to store any type of data under a unique key.
- A document database uses a similar approach by aggregating different data types within a single JSON or XML document.
- Column-based bases store data under a column of your choice.
- Graph databases establish edges and properties for nodes that represent data elements.
Note: This article provides a brief overview of NoSQL database types. For an in-depth explanation, read our article about existing NoSQL database types.
Key-Value Databases
Key-value databases, sometimes referred to as key-value stores, use the simplest data model – the pairing of a key and a value. An application retrieves the value using the unique key.
The value can contain any data structure or type. It is up to the application trying to access the data to understand the content.
Examples of key-value databases include Redis, Riak, Aerospike, and Oracle NoSQL.
Column Based Databases
Column-based databases focus on the efficiency of read operations. If you need to read several columns of multiple rows quickly, it makes sense to organize data in groups of columns (i.e., column families).
The model structure consists of a row identifier that defines the aggregated data and the row aggregate that is composed of more detailed, secondary-level values (i.e., columns).
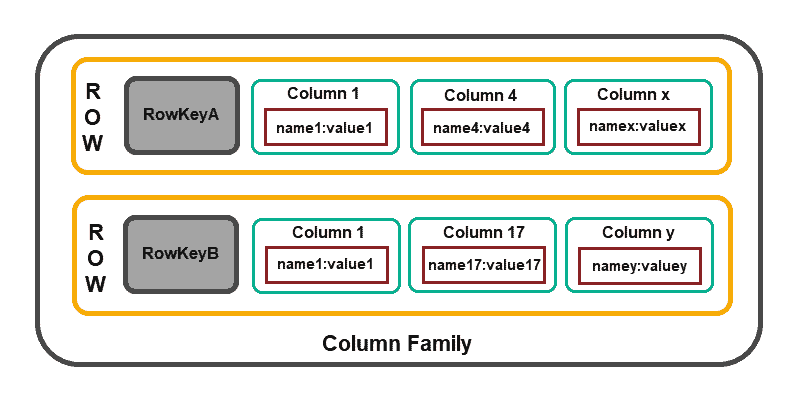
Cassandra, HBase, Amazon DynamoDB and Clickhouse, are some of the widely used column-based solutions.
Note: The column-based approach to storing data proved to be very useful for event-driven data. For example, a specific application can have a dedicated column for writing events or error logs, with rows identified by unique keys containing event timestamps.
Document Databases
Document databases store partially structured data in documents, using JSON, BSON, XML, or other formats. The data inside the document is semi-structured to provide more flexibility when querying. Unlike basic key-value stores, the user does not need to retrieve the entire record, only the relevant part of the document.

Web-facing documents, user comments, and web-publishing apps all benefit from this data model. Famous document-based NoSQLs are MongoDB, OrientDB, Apache CouchDB, and MarkLogic.
Note: MongoDB has managed to position itself as one of the primary advocates of document-oriented NoSQL databases. By taking a closer look at the differences between Cassandra and MongoDB, you can gain valuable insight into how document and column-based databases approach the issue of aggregation and availability.
Graph Databases
Graph databases organize data into Nodes, with Edges establishing relationships between these data nodes.
This data storage model proved to be useful in applications that emphasize relationships, such as social media platforms, customer relations software, and travel and reservation systems.
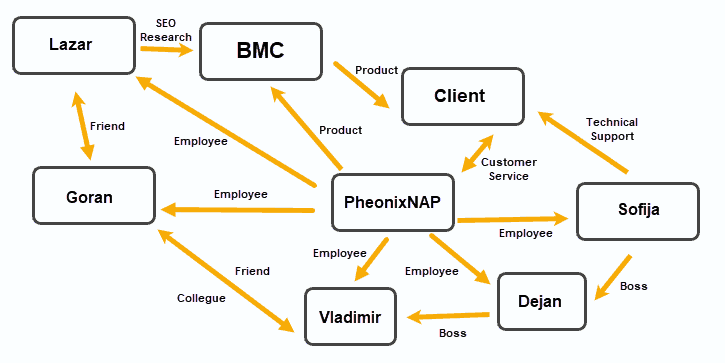
Document-based OrientDB and MarkLogic can function as graph databases. JanusGraph, RedisGraph, and Neo4j are popular graph-based solutions.
Note: Nodes and relationships can be used to make personalized suggestions such as: “you might like this product based on your interests” or “people who bought this product, also bought”. As the database grows, more targeted recommendations can be served.
NoSQL Advantages
- Performance – NoSQL databases offer better performance in the use cases that deal with data that is not highly relational. A NoSQL expects a denormalized schema and optimizes reads accordingly.
- Flexibility – NoSQL’s dynamic schema facilitates storing of unstructured data in optimal ways for a specific case. It enables document creation without defining its structure.
- Scalability – While it is possible to vertically scale RDBMS by upgrading the machine’s memory, storage, or processing power, NoSQL has the added benefit of horizontal scaling. This means that it is possible to handle an increase in traffic by upgrading the database with additional servers.
When to Use NoSQL?
Trying to apply a single database solution for every possible scenario is not a good idea. The different database types covered in this article are designed to deal with specific data problems. This is not limited to NoSQL databases. Even relational databases struggle to standardize various data types into a strict schema.
The inner workings of relational databases are well documented and predictable. The SQL language and the set of tools created using relational technology are omnipresent, with experienced staff readily available. The relational database model allows you to access data in many different and creative ways and not be limited by how the data is stored.
Big Data
Big Data and the value in capturing as much of it as technically possible, is not a suitable workload for the relational model. A NoSQL database that does not use a strict schema, is an excellent choice to store large quantities of assorted and unstructured data.
Software Development
Application development has dramatically benefited from NoSQL databases. Many precious developer hours were wasted on mapping data between in-memory data structures and a relational database. A NoSQL database means you create your model, one that is tailored to meet the needs of the application accessing it and possibly reduce the required amount of coding.
If a database does not have a schema, it means that the application accessing the data needs to have one. This can quickly become an issue if more than one application, developed independently from one another, needs to access the same database.
Inconsistencies on reads are eventually resolved, but the lack of consistency on writes is a serious issue. This problem is often solved by limiting all database interactions within a single application and integrating it with other applications using web services. This solution relates well with the general trend to use web services for integration purposes.
Conclusion
If you determine that a strict schema is limiting your data flow and forcing you to add new fields and tables, a NoSQL database can be an effective solution. You can increase productivity by using a NoSQL database that better matches your application’s needs, scales out quicker, or has excellent throughput.
There are many NoSQL solutions, such as Cassandra and MongoDB, built for specific scenarios that can provide the ingredient you might be missing.



