
Choosing the right database model is vital for achieving optimal performance, scalability, and data consistency. The two main database models based on transactions are ACID and BASE.
The two types have different approaches to handling transactions, each with specific uses.
This article explains the differences between ACID and BASE database models to help you decide which is best for you.

ACID vs. BASE: Overview
ACID and BASE are two database transaction models with different designs:
- ACID focuses on reliability by following strict rules. It is ideal for systems that require strong consistency, such as financial systems.
- BASE prioritizes being highly available and scalable. It's better suited for distributed systems.
Note: The CAP theorem states that a partition-tolerant distributed system cannot simultaneously achieve strong consistency and high availability.
The table below shows the key differences between these two database models:
| Feature | ACID | BASE |
|---|---|---|
| Availability | Lower availability. | Highly available. |
| Consistency | Strong consistency after each transaction. | Consistent over time. |
| Performance | Slower but accurate. | Faster but less accurate. |
| Scalability | Difficult to scale. | Highly scalable. |
| Use Case | Banking, finance, and e-commerce. | Social media, real-time analytics, and big data. |
The sections below explore these and other differences between ACID and BASE in greater depth.
ACID vs. BASE: In-Depth Comparison
ACID and BASE follow different principles. These differences affect transaction handling, scaling, consistency, and other factors. The sections below explore these differences in greater depth.
Definition
ACID is a transaction model that follows strict rules. It ensures data reliability and consistency. The acronym stands for:
- Atomic. Each transaction is completed fully before continuing. If a transaction cannot be completed without errors, it reverts to its previous state to ensure data validity.
- Consistent. A transaction keeps a database's structure.
- Isolated. Transactions run independently to prevent conflicts.
- Durable. Finished transactions persist, even after system failures.
BASE is a flexible transaction model. It prioritizes availability and scalability over consistency. The acronym stands for:
- Basically Available. Highly available due to replicating data across several nodes.
- Soft state. Allows data values to change over time.
- Eventually consistent. Guarantees data consistency over time. Intermediate reads may show incorrect values.
Scaling
Scaling defines how well a database works with high data volumes and user load. ACID and BASE approach scalability in different ways:
- ACID. Scaling is complex because the model relies on strong consistency. Vertical scaling (adding more CPU, RAM, or storage) helps handle higher loads, but hardware limitations exist.
- BASE. Designed for horizontal scaling. The model spreads data across multiple nodes and is efficient for heavy workloads.
Note: Learn more about the differences between horizontal vs. vertical scaling.
Flexibility
Flexibility is a database's ability to adapt to different data structures and requirements. The ACID and BASE models have different approaches to flexibility:
- ACID. The model focuses on data integrity. It has a rigid schema and works with structured data. Changing a schema or data structure requires significant effort or downtime.
- BASE. The model is more flexible because it uses evolving data models. BASE works with semi-structured and unstructured data due to its relaxed consistency. Schema definition requirements are not as strict, and some databases are schema-less.
Performance
Performance shows how well a database handles queries, transactions, and large data volumes. ACID and BASE differ in performance:
- ACID. A strong focus on consistency may lead to bottlenecks in high-traffic environments. Strict consistency and isolation require greater processing power. Response times are slower with high data volumes.
- BASE. The model prioritizes availability over consistency, resulting in better performance. Transactions are not fully processed, and the changes sync later in order to improve response times and throughput.
Note: There are many things that can contribute to a slower server response time. Check out our practical tips on reducing server response times.
Synchronization
Synchronization affects data consistency across nodes or instances. ACID and BASE have entirely different approaches to data coordination:
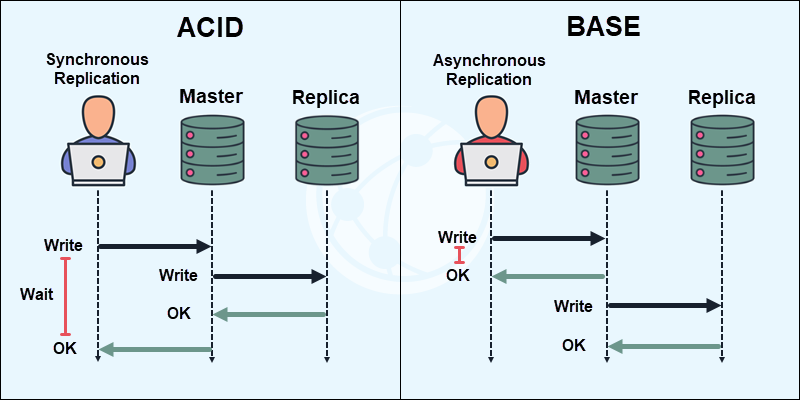
- ACID. Strict synchronization ensures all transactions remain consistent across all nodes before completing a transaction. It uses synchronous replication to confirm changes on all nodes. The approach guarantees data is consistent, but takes longer to complete.
- BASE. BASE uses asynchronous replication, meaning changes happen over time rather than immediately. This approach is faster but results in data inconsistency across replicas.
Reliability
Reliability defines how stable a database is and how well it recovers from failures. ACID and BASE handle reliability in different ways:
- ACID. The model is highly reliable due to following strict rules and having clearly defined security mechanisms. Every transaction finishes or is entirely undone, which prevents data corruption.
- BASE. By focusing on availability, data conflicts are possible. Failure recovery mechanisms typically exist but vary across implementations.
Security
One part of database security is how well a database protects data from unauthorized access. The database transaction models differ in security:
- ACID. The model is typically more secure due to using structured schemas, strict access control, and logs. All these ensure data integrity and greater security.
- BASE. There are some security challenges due to outdated information being available due to late copying. Some databases that use a BASE model completely lack built-in authentication.
Data Integrity
Data integrity is another key point that ensures data remains consistent, accurate, and complete over time. The differences are:
- ACID. Strong data integrity is guaranteed through transaction isolation, consistency checks, and rollback mechanisms.
- BASE. Data integrity requirements are lenient. Temporary mismatches are allowed, resulting in better database performance and scalability. Developers manage data integrity at the application level.
Examples
Database management systems use both ACID and BASE transaction models to model databases. Most relational databases are ACID compliant, while NoSQL databases tend to conform to the BASE model.
The table below lists some notable examples of ACID and BASE databases:
| ACID Databases | BASE Databases |
|---|---|
| MySQL | MongoDB |
| PostgreSQL | Apache Cassandra |
| Microsoft MySQL Database | Couchbase |
| IBM Db2 | Redis |
| Oracle Database | Amazon DynamoDB |
Note: To learn more about the differences between relational and NoSQL databases, read our article SQL vs NoSQL: The Main Differences.
Use Cases
Due to the different processing approaches, each transaction model is suitable for different use cases:
- ACID. It is ideal for OLTP environments with many small simultaneous transactions and zero error tolerance. Examples include e-commerce, banking, and enterprise applications.
- BASE. The model is typically found in environments where high availability is more important than consistency, such as data warehousing and OLAP systems. Examples include business intelligence, real-time analytics, and recommendation engines.
Note: For more details, see our in-depth comparison between OLTP vs. OLAP.
ACID vs. BASE Database: How to Choose
The choice between ACID and BASE databases depends on the specific application requirements. Consider the following factors when choosing:
- Consistency vs. availability. ACID is better suited for applications that require strong consistency. BASE is better for scalability and availability.
- Workload type. ACID is ideal for OLTP systems that have frequent transactions. On the other hand, BASE is better for OLAP and big data applications.
- Scalability. ACID databases are harder to change and are more suitable for vertically scaled systems. BASE databases are highly scalable and distributed by nature.
- Latency and performance. ACID transactions require strict synchronization, which leads to higher latency under heavy traffic. BASE systems have low-latency transactions and perform faster in distributed environments.
- Compliance. ACID databases are preferred in highly regulated industries due to their strict consistency and security. BASE works best in cases where data mismatches are acceptable, such as IoT, CDNs, and social media.
Conclusion
This guide showed the main differences between ACID and BASE database transaction models. We also provided use cases and pieces of advice on how to choose between them.
Next, learn more about different database schemas in our star vs. snowflake schema comparison guide.



