Pandas is an open-source Python library primarily used for data analysis. The collection of tools in the Pandas package is an essential resource for preparing, transforming, and aggregating data in Python.
The Pandas library is based on the NumPy package and is compatible with a wide array of existing modules. The addition of two new tabular data structures, Series and DataFrames, enables users to utilize features similar to those in relational databases or spreadsheets.
This article shows you how to install Python Pandas and introduces basic Pandas commands.

How to Install Python Pandas
Python’s popularity has resulted in the creation of numerous distributions and packages. Package managers are efficient tools used to automate the installation process, manage upgrades, configure, and remove Python packages and dependencies.
Note: Python version 3.6.1 or later is a prerequisite for a Pandas installation. Use our detailed guide to check your current Python version. If you do not have the required Python version you can use one of these detailed guides:
Install Pandas with Anaconda
The Anaconda package already contains the Pandas library. Check the current Pandas version by typing the following command in your terminal:
conda list pandasThe output confirms the Pandas version and build.

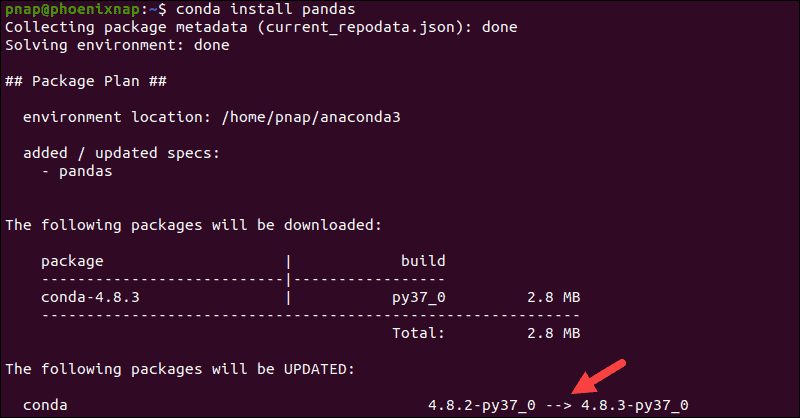
If Pandas is not present on your system, you can also use the conda tool to install Pandas:
conda install pandasAnaconda manages the entire transaction by installing a collection of modules and dependencies.
Install Pandas with pip
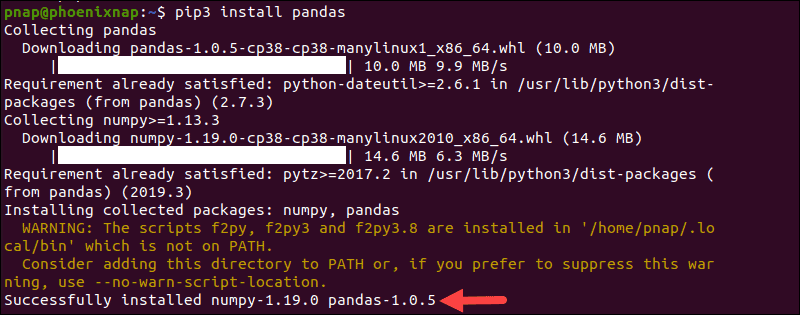
The PyPI software repository is administered regularly and maintains the latest versions of Python-based software. Install pip, the PyPI package manager, and use it to deploy Python pandas:
pip3 install pandasThe download and installation process takes a few moments to complete.
Install Pandas on Linux
Installing a prepackaged solution might not always be the preferred option. You can install Pandas on any Linux distribution using the same method as with other modules. For example, use the following command to install the basic Pandas module on Ubuntu 20.04:
sudo apt install python3-pandas -y Keep in mind that packages in Linux repositories often do not contain the latest available version.
Using Python Pandas
Python’s flexibility allows you to use Pandas in a wide variety of frameworks. This includes basic Python code editors, commands issued from your terminal’s Python shell, interactive environments such as Spyder, PyCharm, Atom, and many others. The practical examples and commands in this tutorial are presented using Jupyter Notebook.
Importing Python Pandas Library
To analyze and work on data, you need to import the Pandas library in your Python environment. Start a Python session and import Pandas using the following commands:
import pandas as pdimport numpy as npIt is considered good practice to import pandas as pd and the numpy scientific library as np. This action allows you to use pd or np when typing commands. Otherwise, it would be necessary to enter the full module name every time.

It is vital to import the Pandas library each time you start a new Python environment.
Series and DataFrames
Python Pandas uses Series and DataFrames to structure data and prepare it for various analytic actions. These two data structures are the backbone of Pandas’ versatility. Users already familiar with relational databases innately understand basic Pandas concepts and commands.
Pandas Series
Series represent an object within the Pandas library. They give structure to simple, one-dimensional datasets by pairing each data element with a unique label. A Series consists of two arrays – the main array that holds the data and the index array that holds the paired labels.
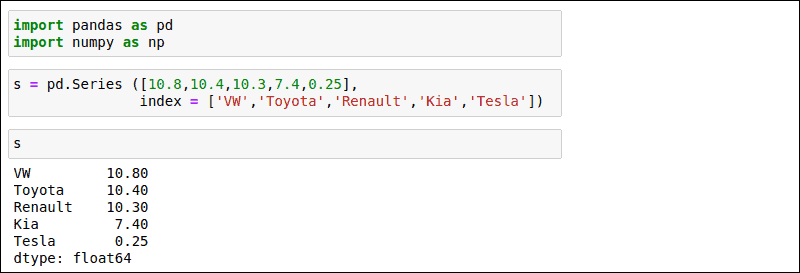
Use the following example to create a basic Series. In this example the Series structures car sale numbers indexed by manufacturer:
s = pd.Series([10.8,10.7,10.3,7.4,0.25],
index = ['VW','Toyota','Renault','KIA','Tesla')
After running the command, type s to view the Series you have just created. The result lists the manufacturers based on the order they were entered.
You can perform a set of complex and varied functions on Series, including mathematical functions, data manipulation, and arithmetic operations between Series. A comprehensive list of Pandas parameters, attributes, and methods is available on the Pandas official page.
Pandas DataFrames
The DataFrame introduces a new dimension to the Series data structure. In addition to the index array, a strictly arranged set of columns provide DataFrames with a table-like structure. Each column can store a different data type. Try to manually create a dict object called ‘data’ with the same car sales data:
data = { 'Company' : ['VW','Toyota','Renault','KIA','Tesla'],
'Cars Sold (millions)' : [10.8,10.7,10.3,7.4,0.25],
'Best Selling Model' : ['Golf','RAV4','Clio','Forte','Model 3']}Pass the ‘data’ object to the pd.DataFrame() constructor:
frame = pd.DataFrame(data)Use the DataFrame’s name, frame, to run the object:
frameThe resulting DataFrame formats the values into rows and columns.
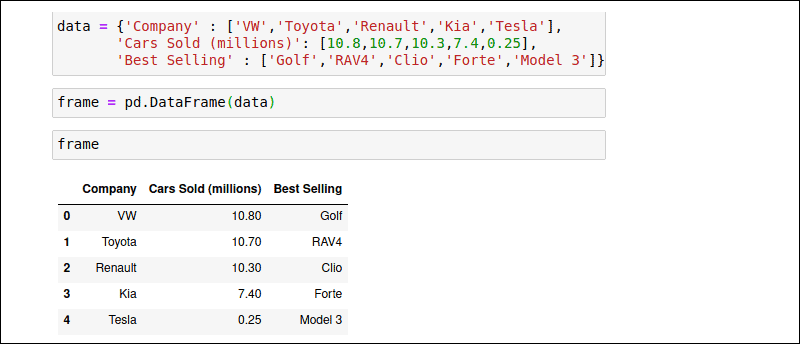
The DataFrame structure allows you to select and filter values based on columns and rows, assign new values, and transposition the data. As with Series, the Pandas official page provides a full list of DataFrame parameters, attributes, and methods.
Reading and Writing with Pandas
Through Series and DataFrames, Pandas introduce a set of functions that enable users to import text files, complex binary formats, and information stored in databases. The syntax for reading and writing data in Pandas is straightforward:
pd.read_filetype = (filename or path)– import data from other formats into Pandas.df.to_filetype = (filename or path)– export data from Pandas to other formats.
The most common formats include CSV, XLXS, JSON, HTML, and SQL.
| Read | Write |
|---|---|
| pd.read_csv (‘filename.csv’) | df.to_csv (‘filename or path’) |
| pd.read_excel (‘filename.xlsx’) | df.to_excel (‘filename or path’) |
| pd.read_json (‘filename.json’) | df.to_json (‘filename or path’) |
| pd.read_html (‘filename.htm’) | df.to_html (‘filename or path’) |
| pd.read_sql (‘tablename’) | df.to_sql (‘DB Name’) |
In this example, the nz_population CSV file contains New Zealand’s population data for the previous 10 years. Import the CSV file using into the Pandas library with the following command:
pop_df = pd.read_csv('nz_population.csv')Users are free to define the name for the DataFrame (pop_df). Type the name of the newly created DataFrame to display the data array:
pop_df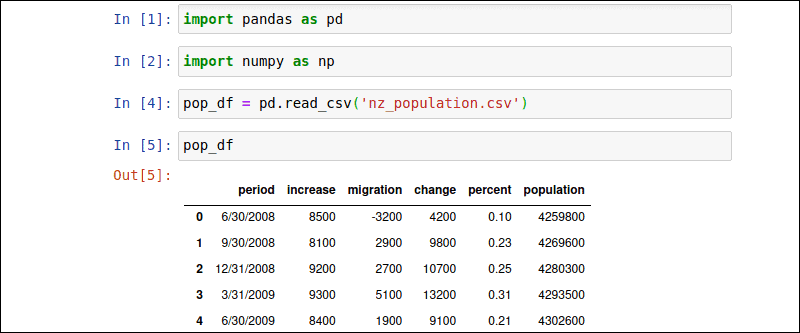
Common Pandas Commands
Once you import a file into the Pandas library, you can use a set of straightforward commands to explore and manipulate the datasets.
Basic DataFrame Commands
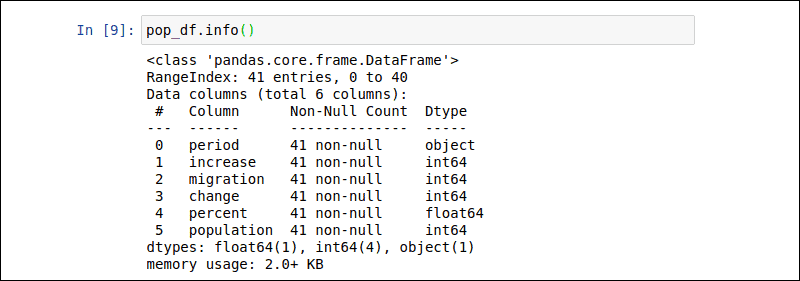
Enter the following command to retrieve an overview of the pop_df DataFrame from the previous example:
pop_df.info()The output provides the number of entries, name of each column, data types, and file size.
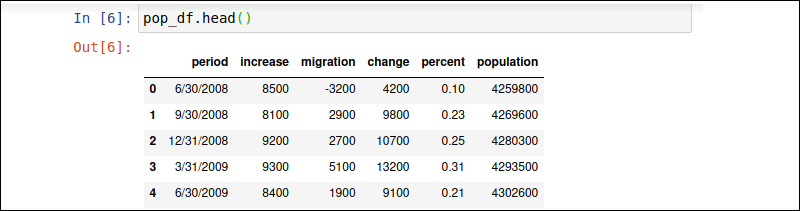
Use the pop_df.head() command to display the first 5 rows of the DataFrame.
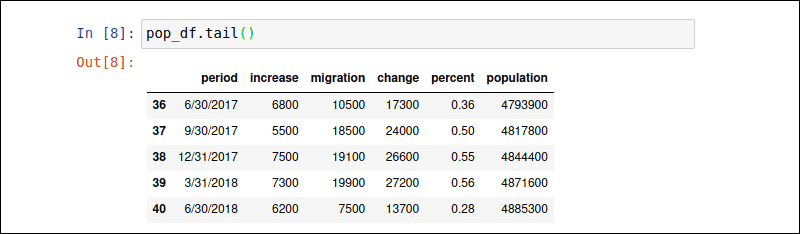
Type the pop_df.tail() command to display the last 5 rows of the pop_df DataFrame.
Select specific rows and columns using their names and the iloc attribute. Select a single column by using its name within square brackets:
pop_df['population']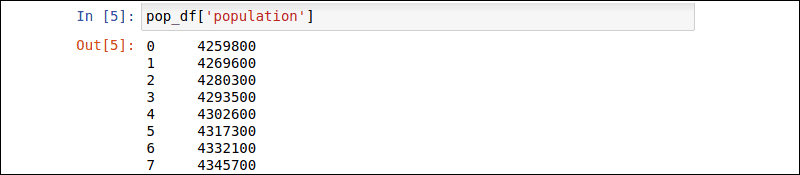
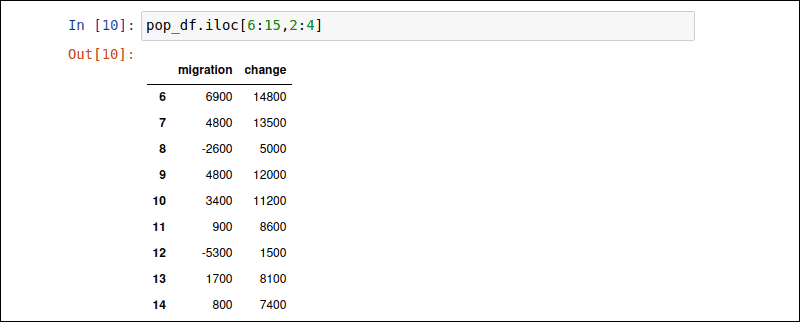
The iloc attribute allows you to retrieve a subset of rows and columns. Rows are specified in front of the comma, and columns after the comma. The following command retrieves data from row 6 to 16, and column 2 to 4:
pop_df.iloc [6:15,2:4]The colon : directs Pandas to show the entire specified subset.
Conditional Expressions
You can select rows based on a conditional expression. The condition is defined within the square brackets []. The following command filters rows where the ‘percent’ column value is greater than 0.50 percent.
pop_df [pop_df['percent'] > 0.50]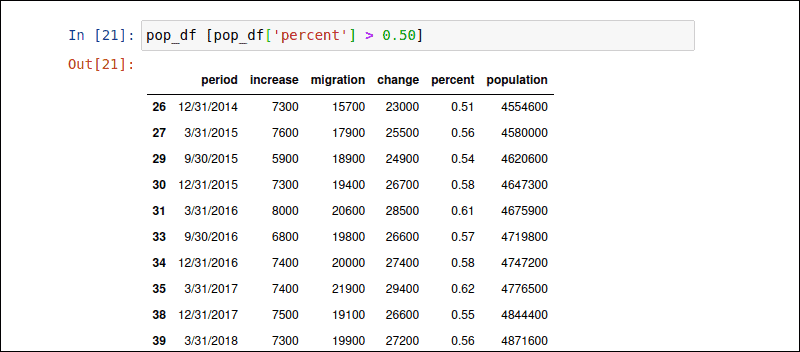
Data Aggregation
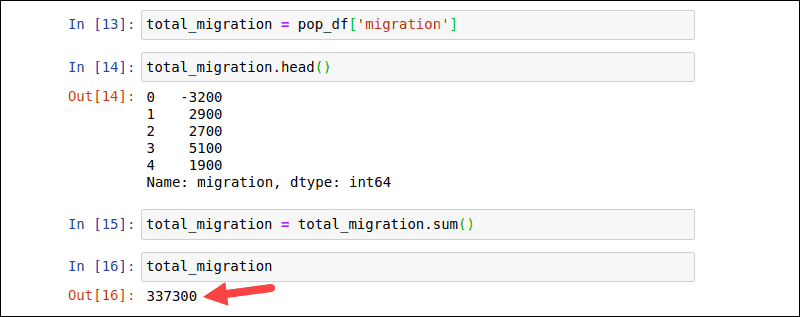
Use functions to calculate values from an entire array and produce a single result. Square brackets [] also allow users to select a single column and turn it into a DataFrame. The following command creates a new total_migration DataFrame from the migration column in pop_df:
total_migration = pop_df['migration']Verify the data by checking the first 5 rows:
total_migration.head()Calculate the net migration into New Zeeland with the df.sum() function:
total_migration = total_migration.sum()total_migrationThe output produces a single result that represents the total sum of the values in the total_migration DataFrame.
Some of the more common aggregation functions include:
df.mean()– Calculate the mean of values.df.median()– Calculate the median of values.df.describe()– Provides a statistical summary .df.min()/df.max()– The minimum and maximum values in the dataset.df.idxmin()/df.idxmax()– The minimum and maximum index values.
These essential functions represent only a small fraction of the available actions and operations Pandas has to offer.
Conclusion
You have successfully installed Python Pandas and learned how to manage simple data structures. The sequence of examples and commands outlined in this tutorial showed you how to prepare, process, and aggregate data in Python Pandas.