
Missing data is a common problem when working with realistic datasets. Knowing and analyzing the causes of missing values helps provide a clearer picture of the steps to resolve the issue. Python provides many methods to analyze and resolve the problem of unaccounted data.
This tutorial explains the causes and solutions of missing data through a practical example in Python.

Prerequisites
Note: Not sure which version of Python is on the machine? Find out by following our tutorial: How to Check Python Version in Linux, Mac, & Windows.
How Does Missing Data Affect Your Algorithm?
There are three ways missing data affects your algorithm and research:
- Missing values provide a wrong idea about the data itself, causing ambiguity. For example, calculating an average for a column with half of the information unavailable or set to zero gives the wrong metric.
- When data is unavailable, some algorithms do not work. Some machine learning algorithms with datasets containing NaN (Not a Number) values throw an error.
- The pattern of missing data is an essential factor. If data from a dataset is missing at random, then the information is still helpful in most cases. However, if there is missing information systematically, all analysis is biased.
Note: Learn how to perform a common task in Python, finding the average of a list.
What Can Cause Missing Data?
The cause of missing data depends on the data collection methods. Identifying the cause helps determine which path to take when analyzing a dataset.
Here are some examples of why datasets have missing values:
Surveys. Data gathered through surveys often has missing information. Whether for privacy reasons or just not knowing an answer to a specific question, questionnaires often have missing data.
IoT. Many problems arise when working with IoT devices and collecting data from sensor systems to edge computing servers. A temporary loss of communication or a malfunctioning sensor often causes pieces of data to go missing.
Restricted access. Some data has limited access, especially data protected by HIPAA, GDPR, and other regulations.
Manual error. Manually entered data usually has inconsistencies because of the nature of the job or the vast amount of information.
How To Handle Missing Data?
To analyze and explain the process of how to handle missing data in Python, we will use:
- The San Francisco Building Permits dataset
- Jupyter Notebook environment
The ideas apply to different datasets as well as other Python IDEs and editors.
Import and View the Data
Download the dataset and copy the path of the file. Using the Pandas library, import and store the Building_Permits.csv data into a variable:
import pandas as pd
data = pd.read_csv('<path to Building_Permits.csv>')To confirm the data imported correctly, run:
data.head()The command shows the first few lines of the data in tabular format:
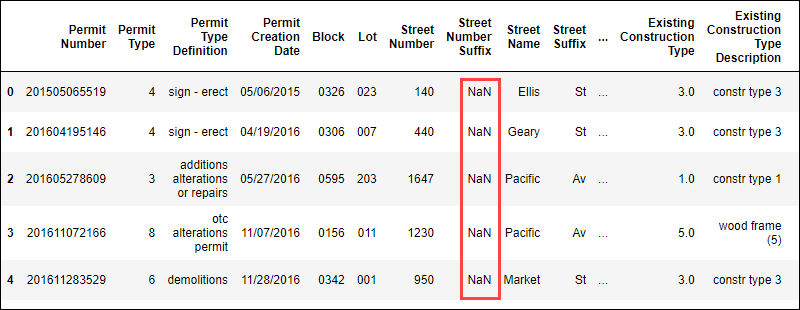
The presence of NaN values indicates there is missing data in this dataset.
Find Missing Values
Find how many missing values there are per column by running:
data.isnull().sum()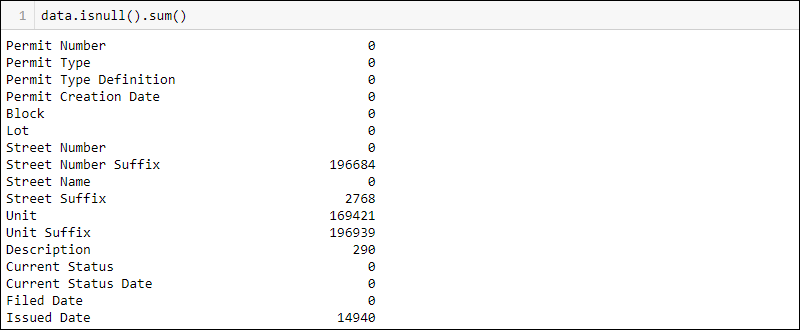
The numbers provide more meaning when displayed as percentages. To display the sums as a percent, divide the number by the total length of the dataset:
data.isnull().sum()/len(data)To show the columns with the highest percentage of missing data first, add .sort_values(ascending=False) to the previous line of code:
data.isnull().sum().sort_values(ascending = False)/len(data)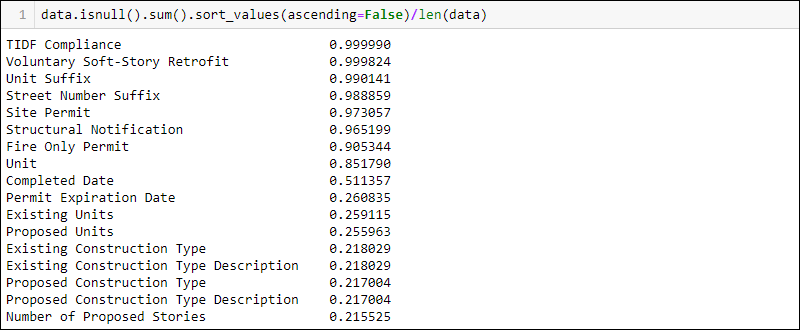
Before removing or altering any values, check the documentation for any reasons why data is missing. For example, the TIDF Compliance column has nearly all data missing. However, the documentation states this is a new legal requirement, so it makes sense that most values are missing.
Mark Missing Values
Display the general statistical data for a dataset by running:
data.describe()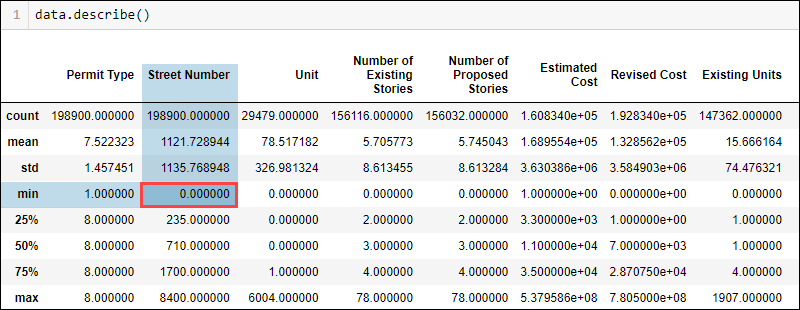
Depending on the data type and the domain knowledge, some values do not fit in logically. For example, a street number cannot be zero. However, the minimum value shows zero, indicating probable missing values in the street number column.
To see how many Street Number values are 0, run:
(data['Street Number'] == 0).sum()Using the NumPy library, exchange the value for NaN to indicate the missing piece of information:
import numpy as np
data['Street Number'] = data['Street Number'].replace(0, np.nan)Checking the updated statistical data now indicates the minimum street number is 1.
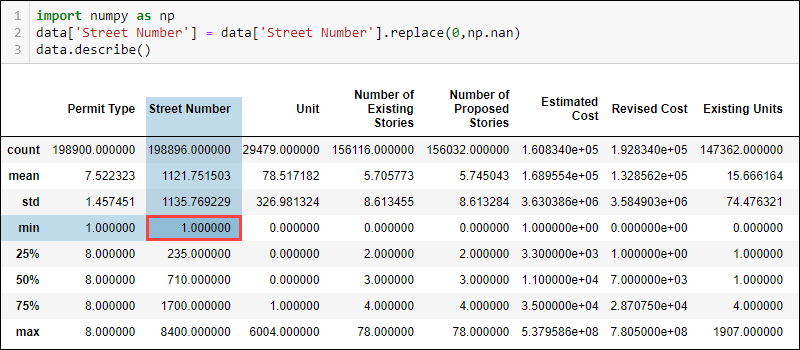
Likewise, the sum of NaN values now shows there is missing data in the street number column.
Other values in the Street Number column also change, such as the count and mean. The difference is not huge due to only a few values being 0. However, with more significant amounts of wrongly labeled data, the differences in metrics are also more noticeable.
Drop Missing Values
The easiest way to handle missing values in Python is to get rid of the rows or columns where there is missing information.
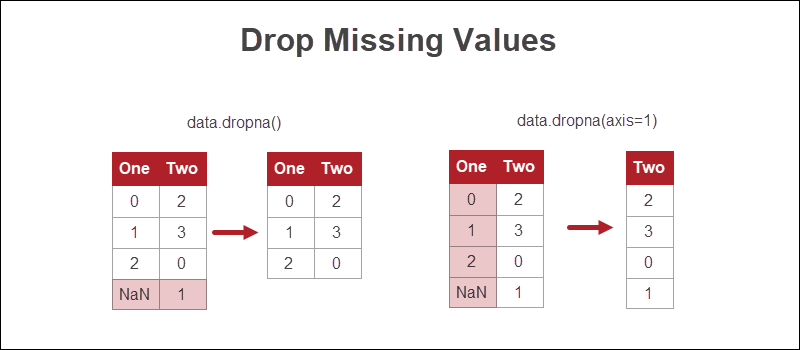
Although this approach is the quickest, losing data is not the most viable option. If possible, other methods are preferable.
Drop Rows with Missing Values
To remove rows with missing values, use the dropna function:
data.dropna()When applied to the example dataset, the function removed all rows of data because every row of data contains at least one NaN value.
Drop Columns with Missing Values
To remove columns with missing values, use the dropna function and provide the axis:
data.dropna(axis = 1)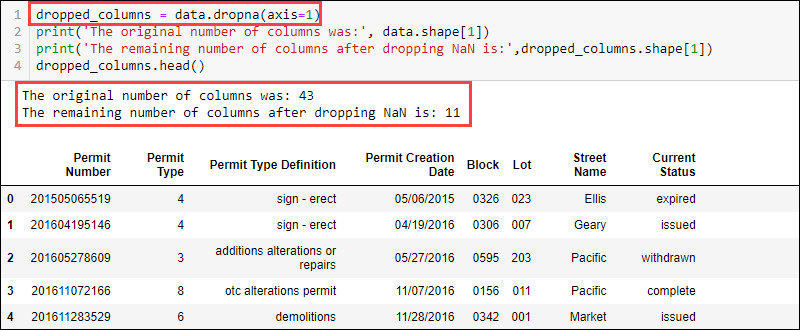
The dataset now contains 11 columns compared to the initially available 43.
Impute Missing Values
Imputation is a method of filling missing values with numbers using a specific strategy. Some options to consider for imputation are:
- A mean, median, or mode value from that column.
- A distinct value, such as 0 or -1.
- A randomly selected value from the existing set.
- Values estimated using a predictive model.
The Pandas DataFrame module provides a method to fill NaN values using various strategies. For example, to replace all NaN values with 0:
data.fillna(0)The fillna function provides different methods for replacing missing values. Backfilling is a common method that fills the missing piece of information with whatever value comes after it:
data.fillna(method = 'bfill')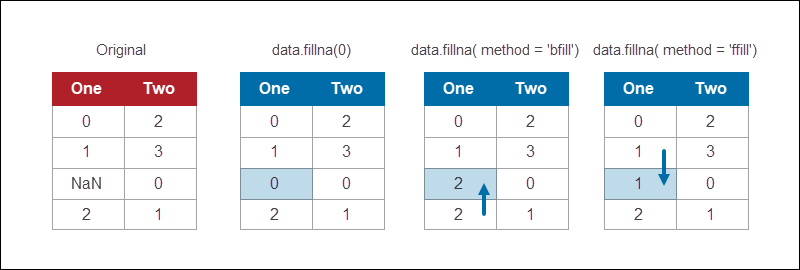
If the last value is missing, fill all the remaining NaN's with the desired value. For example, to backfill all possible values and fill the remaining with 0, use:
data.fillna(method = 'bfill', axis = 0).fillna(0)Similarly, use ffill to fill values forward. Both the forward fill and backward fill methods work when the data has a logical order.
Algorithms That Support Missing Values
There are machine learning algorithms that are robust with missing data. Some examples include:
- kNN (k-Nearest Neighbor)
- Naïve Bayes
Other algorithms, such as classification or regression trees, use the unavailable information as a unique identifier.
Note: Learn how to comment in Python. Comments are useful for debugging and understanding your own code after a longer period of time.
Conclusion
Addressing missing values is an important part of data preparation for data science and machine learning. The process requires some domain knowledge and proper decision-making in each situation.
To run the data through a machine learning model, install Keras and try to create a deep learning model for the dataset.



