Kubernetes offers much flexibility for orchestrating large container clusters, but the number of features and options can present a challenge for inexperienced users. Applying best practices helps avoid potential hurdles and create a secure and efficient environment.
This article presents Kubernetes best practices for building optimized containers, streamlining deployments, administering reliable services, and managing a full-blown cluster.

15 Kubernetes Best Practices
Kubernetes must be managed carefully to ensure optimal performance and deployment security. The following sections describe the recommended actions for users to take when setting up a cluster.
Improve Deployment Security
Containers offer much less isolation and are inherently less secure than virtual machines. Below is the list of the essential security considerations for a Kubernetes-orchestrated container deployment:
- Use lighter container images to reduce the attack surface for potential attackers. Build your images from scratch to achieve optimal results, and use multiple FROM statements in a single Dockerfile if you need many different components. Small images also boost efficiency and conserve resources.
- Use images from trusted repositories and continuously scan them for potential vulnerabilities. Numerous online tools, such as Anchore or Clair, provide a quick static analysis of container images and inform users of potential threats and issues.
- Provide more isolation by forcing containers to run with non-root users and a read-only filesystem. Running containers as a root user may open the cluster to a security breach, with attackers using privilege escalation to obtain access to the system.
- Set up role-based access control (RBAC) to ensure no user has more permissions than needed to complete their tasks.
- Keep secrets and passwords isolated from your container images. A user with permission to create pods within a namespace can use that role to create a pod and access config maps or secrets.
- Keep cluster-wide logs in a separate backend storage system by integrating a logging solution like the ELK Stack. Logs must be consistent and perpetually available, but Kubernetes containers, pods, and nodes are dynamic and ephemeral entities.
Note: Read Kubernetes Security Best Practices for a more detailed overview of the steps you can take to secure your cluster.
Create Descriptive Labels
Create descriptive labels whenever possible. Most features, plugins, and third-party solutions need labels to identify pods and control automated processes. Kubernetes DaemonSets depend on labels and node selectors to manage pod deployment within a cluster.
Group Multiple Processes Within a Pod
Use Kubernetes container linking abilities to deploy multiple containers on a single pod. For example, a proxy sidecar container can outsource security features to an external resource, as seen in the diagram below:
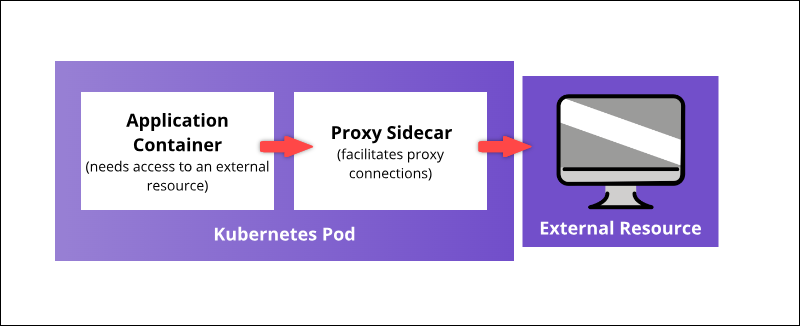
A coupled container can enhance the main container's core functionality or help it adapt to its deployment environment.
Use Init Containers
Create init containers to ensure a service is ready before initiating the pod's main container. One or more init containers usually perform utility tasks or security checks that are not included in the main application container.
Init containers delay the onset of the pod's main container by restarting the pod until a precondition is satisfied. Once the prerequisite is met, the init container self-terminates and allows the main container to start.
Avoid Using latest Tag
Avoid the latest tag when deploying containers in a production environment since it makes it difficult to determine which version of the image is running.
An effective way to ensure that the container always uses the same version of the image is to use the unique image digest as the tag. The example below shows a Redis image with its unique digest:
redisd@sha256:675hgjfn48324cf93ffg43269ee113168c194352dde3eds876677c5cbKubernetes does not automatically update the image version unless the user changes the digest value.
Set Up Readiness and Liveness Probes
Help Kubernetes monitor and interpret the health of your applications by launching liveness and readiness probes. When the user defines a liveness check, and a process meets the requirements, Kubernetes stops the container and starts a new instance to take its place.
Readiness probes conduct audits on the pod level and assess if a pod can accept traffic. If a pod is unresponsive, a readiness probe triggers a process to restart the pod.
Note: It is recommended to set a time delay when configuring readiness probes. Large configuration files can take some time to load. A readiness probe might stop the pod before it manages to load, triggering a restart loop.
The documentation for configuring readiness and liveness probes is available on the official Kubernetes website.
Expose Pods with NodePort
Publish pods to external users by setting the service type to NodePort. Kubernetes reserves the port number specified in the NodePort field across all nodes and forwards all the incoming traffic to the pod. The service is accessible using the internal cluster IP and the node IP with the reserved port.
The example below defines the NodePort 31626 for the Kafka stream processing platform:
apiVersion: v1
kind: Service
metadata:
name: kafka-nodeport
spec:
type: NodePort
ports:
- port: 80
targetPort: 8080
nodePort: 31626
selector:
app: kafkaAlways use a port number within the range configured for NodePort (30000-32767).
Use record Flag to Track Deployment
Clear labels and flags offer fine-grained control over the deployment process. Append the --record flag to a kubectl command to store the command as an annotation. For example:
kubectl apply -f test-deployment.yaml --recordTrack updates with the kubectl rollout history command:
kubectl rollout history deployment test-deploymentThe recorded commands appear in the CHANGE-CAUSE column of the command output:

Rollback to any revision by using the undo command:
kubectl rollout undo deployment test-deployment --to-revision=[revision-number]Map External Services to DNS
Use the ExternalName parameter to map services using a CNAME record, i.e., a fully qualified domain name. This way, clients connecting to the service bypass the service proxy and connect directly to the external resource. In the example below, the pnap-service is mapped to the admin.phoenixnap.com external resource.
apiVersion: v1
kind: Service
metadata:
name: pnap-service
spec:
type: ExternalName
externalName: admin.phoenixnap.com
ports:
- port: 80The pnap-service is accessed the same way as other services. The crucial difference is that the redirection now occurs at the DNS level.
Focus on Individual Services
Split the deployment into multiple services and avoid bundling too much functionality in a single container. It is much easier to scale apps horizontally and reuse containers if they focus on doing one function.
Use Helm Charts to Simplify Complex Deployments
Helm, a package manager for Kubernetes apps, streamlines the installation process and quickly deploys resources throughout the cluster. Deploy Helm Charts to eliminate the need to create and edit multiple complex configuration files.
For example, the following command creates the necessary Deployments, Services, PersistentVolumeClaims, and Secrets needed to run the Kafka Manager on a cluster:
helm install --name my-messenger stable/kafka-managerIf you are just starting with Helm, visit our guides on How to Install Helm on Ubuntu, Mac, and Windows and How to Add or Update Helm Repo. If you want to find out more, or compare Helm with other tools, check our Helm vs. Kustomize article.
Utilize Node and Pod Affinity to Avoid Creating More Labels
Instead of creating node labels, use existing pod labels to specify the nodes on which a pod can be scheduled. The affinity feature defines both node affinity and inter-pod affinity.
There are two options the user can choose to specify affinity:
- requiredDuringSchedulingIgnoredDuringExecution establishes mandatory constraints that must be met for a pod to be scheduled to a node.
- preferredDuringSchedulingIgnoredDuringExecution defines preferences that a scheduler prioritizes but does not guarantee.
If the node labels change at runtime, and the affinity rules are no longer met, the pod is not removed from the node. The nodeSelector parameter limits pods to specific nodes by using labels.
In the following example, the Grafana pod will be scheduled only on nodes with the ssd label:
apiVersion: v1
kind: Pod
metadata:
name: grafana-ssd
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: ssd
operator: In
values:
- "true"The pod affinity/anti-affinity feature expands the types of constraints a user can express. This feature allows rules to be set so that individual pods get scheduled based on the labels of other pods.
Combine Node Taints and Tolerations
Taints and Tolerations ensure pods get scheduled onto the appropriate nodes. Taints prevent pod scheduling on a node, define node preferences, and remove existing pods, while Tolerations enable pod scheduling only on nodes with existing and matching Taints.
Using Taints and Tolerations simultaneously allows the creation of complex rules and provides better control over pod scheduling.
Note: Learn what to look out for when migrating a legacy application to containers in our article How to Containerize Legacy Applications.
Group Resources with Namespaces
Partition large clusters into smaller, easily identifiable groups. Namespaces allow you to create separate test, QA, production, or development environments and allocate adequate resources within a unique namespace.
Create a namespace in a YAML file and use kubectl to post it to the Kubernetes API server. You can subsequently use the namespace to administer the deployment of additional resources.
Note: If multiple users have access to the same cluster, limit users to act within specific namespace confines. Separating users is a great way to delimit resources and avoid potential naming or versioning conflicts.
Optimize Large Clusters
As of version 1.31, Kubernetes supports up to 5000 nodes in a cluster. While having a large cluster is often a necessity, maintaining such deployments requires additional effort and considerations.
Below are some essential considerations to bear in mind when operating a large cluster:
- Always ensure there are enough resources available before creating a cluster. Thousands of nodes can quickly dry up a resource quota.
- Check the provider's policy before scaling up. Some resource providers may impose a rate limit for new instance creation.
- Ensure fault tolerance by providing at least one control plane instance per failure zone.
- Create a separate etcd instance for storing Event objects.
- Memory limits for addons are usually set with smaller clusters in mind. Addons on larger clusters can have memory limit problems unless managed on a case-by-case basis.
Conclusion
After reading this article, apply some of the outlined practices and test their impact on the cohesion and functionality of your Kubernetes cluster. Remember that each Kubernetes cluster has a specific design and requirements, so not all suggested practices will apply to all use cases.
Next, read about Best Kubernetes Tools for streamlining command-line management, refining deployment processes, and improving security.