
Kubernetes is one of the most popular orchestration solutions for hosting containers in a production environment. The platform allows users to automate the deployment of numerous instances of an application while scaling up and down according to demand.
However, due to the volatile nature of Kubernetes pods, storage volumes needed to be resolved with an entirely new approach.
This article explains what Kubernetes persistent volumes are and why they are so significant.

What are Kubernetes Persistent Volumes
Kubernetes persistent volumes are user-provisioned storage volumes assigned to a Kubernetes cluster. Persistent volumes’ life-cycle is independent from any pod using it. Thus, persistent volumes are perfect for use cases in which you need to retain data regardless of the unpredictable life process of Kubernetes pods.
Without persistent volumes, maintaining services as common as a database would be impossible. Whenever a pod gets replaced, the data gained during the life-cycle of that pod would be lost. However, thanks to persistent volumes, data is contained in a consistent state.
Note: To fully understand the value of Kubernetes persistent volumes, it is a good idea to get to know the basic concepts of Kubernetes architecture.
Types of Kubernetes Volumes
To understand what persistent volumes are, we first need to explain how volume types differ. There are different types of volumes you can use in a Kubernetes pod:
- Node-local memory (
emptyDirandhostPath) - Cloud volumes (e.g.,
awsElasticBlockStore,gcePersistentDisk, andazureDiskVolume) - File-sharing volumes, such as Network File System (
nfs) - Distributed-file systems (e.g.,
cephfs,rbd, andglusterfs) - Special volume types such as
PersistentVolumeClaim,secret, andgitRepo
Both emptyDir and hostPath are attached to the pod, stored either in RAM or in persistent storage on a drive. As they depend on the pod, their content is available as long as the pod is running. If it goes down, the data is lost.
With cloud volumes, nfs, and PersistentVolumeClaim, the volume is independent and placed outside of the pod. Although they are essentially all designed to preserve data, cloud volumes are significantly more difficult to handle. To connect the pod to the provider, the user must know many storage details.
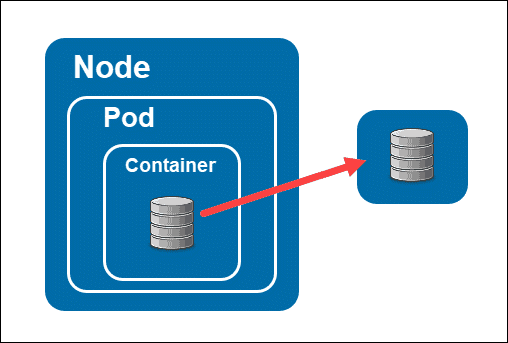
Network file systems and persistent volumes are much more practical. In fact, these two volume types work on the same principles.
NFS lets you connect to a volume through a yaml file. Without the pod, the content of the volume is unmounted but remains available. However, even for NFS setups you need to send a Persistent Volume Claim (PVC) request.
Hence, Persistent Volume Claims are the core solution for persistent volumes in Kubernetes.
What are Persistent Volume Claims
Persistent Volume Claims are objects that connect to back-end storage volumes through a series of abstractions. They request the storage resources that your deployment needs.
The main advantage is that PVCs are much more user-friendly, allowing developers to use them without having to know too many details of the cloud environment they are connecting to. The administrator lists the full claim details in the PVC, but the pod itself only requires a link to access it.
Therefore, a pod using a persistent volume also includes a number of abstract layers between it and the storage.
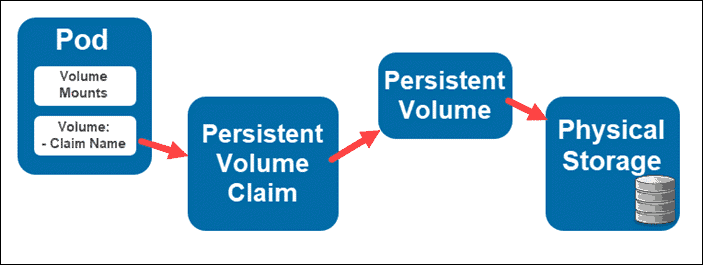
Using Persistent Volumes
To bind a pod with a persistent volume, it needs to include volume mounts and a persistent volume claim (PVC). These claims allow users to mount a persistent volume into a pod without having to know the details of the cloud environment.
Note: You cannot bind two claims to the same persistent volume inside one pod. However, you can use the same claim in two different pod instances and connect them to the same persistent volume.
In the persistent volume claim, users specify how large they want the storage to be, the selector, directing to the appropriate PV, and the storage class. The storage class refers to the type of provisioning, whether it is static or dynamic.
Static Provisioning is a feature in which administrators make use of existing storage devices and make them available for cluster users. The cluster administrator creates several persistent volumes that are available for consumption and exist in the Kubernetes API.
Dynamic Provisioning occurs when none of the static persistent volumes match the PVC. In this case, the provisioning is based on storage classes, created and configured by administrators.
The Lifecycle of Persistent Volumes
Once you delete the PVC, you release the PV of its claim. Depending on the reclaim policy set, the volume will either be retained, recycled, or deleted.
- If you set the reclaim policy to retain, the volume in the storage remains even once released from the claim.
- Alternatively, you can recycle the volume, which deletes the content inside of it and makes it available for other PVCs.
- Having the reclaim policy configured to delete once it is disconnected from the PVC means that the volume and storage are removed completely.
How to Create a Persistent Volume
1. To create a persistent volume, you start by creating a .yaml file in the editor of your choice. In this example we name the file example-pv.yaml and edit it with the nano editor:
nano example-pv.yaml2. Add the following content to the file:
apiVersion: v1
kind: PersistentVolume
metadata:
name: [pv_name]
spec:
capacity:
storage: 10Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
mountPath: [path of where the volume is accessible from within the container]
volumeID: [your_volume_id]3. Replace the specifications of name, storage, mountpath, and volumeID with your respected values.
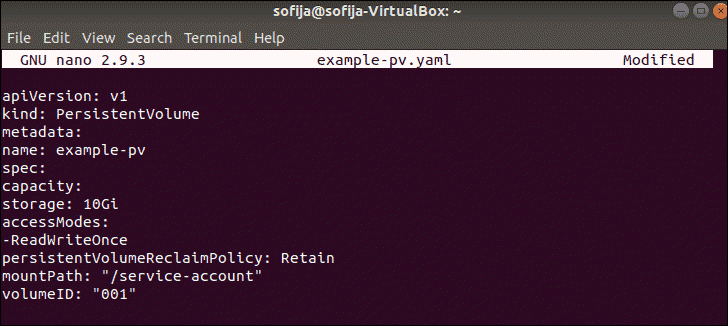
4. Save and exit the file.
5. Then, deploy the persistent volume by using the following command with the name of the .yaml file you created in the previous step:
kubectl create -f example-pv.yamlNote: Once you have deployed a persistent volume, you can view it by running the kubectl command: kubectl get pv.
How to Create a Persistent Volume Claim
As with the PV, you create a PVC with a .yaml file consisting of the following content:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: [pvc_name]
spec:
storageClassName: manual
selector:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
With the content added, save and exit the file.
Note: To see the persistent volume claim use the kubectl command: kubectl get pvc.
Once you have set up and configured the persistent volume and the persistent volume claim, you can specify the PVC in the required pod.
Conclusion
This article explained what persistent volumes are and why you would use them instead of traditional container volumes. Whether you choose one or the other depends on the needs of your development operation.
Also, it showed examples of how to deploy persistent volumes and create corresponding volume claims.
Next, we recommend looking into optimizing containers for Kubernetes clusters to ensure faster and more efficient development.



