
Both wget and curl are command-line tools for transferring data across networks, especially over HTTP, HTTPS, and FTP. While they serve similar purposes, they differ significantly in features, syntax, use cases, and flexibility.
Understanding the distinctions between these tools is critical for choosing the right one for scripting, automation, or troubleshooting network issues.
This tutorial will compare wget and curl in detail, including their capabilities, limitations, and best use cases.

What Is wget?
wget is a non-interactive command-line utility that downloads files from the internet. It is designed to work reliably over unstable or slow network connections. The tool operates in scripts and automated tasks because it does not require user interaction.
wget is useful for downloading large files, recursively retrieving web content, and resuming interrupted downloads. It automatically handles redirects, retries, and compression when supported by the server.
The wget syntax is:
wget [option] [url]wget is able to run with no options as long as the URL is provided. The command performs a basic resource download using default settings. Adding options allows users to modify and control the download process behavior.
What Is curl?
curl is a command-line tool that transfers data to or from a server using various supported protocols. It is highly flexible and supports HTTP, HTTPS, FTP, FTPS, SFTP, SCP, LDAP, SMB, SMTP, and more. Unlike wget, curl handles both data download and upload.
Developers often use curl to test APIs, simulate requests, and perform more advanced operations such as sending custom headers, using different HTTP methods, and submitting forms. It is a versatile tool ideal for debugging and integrating into scripts where precise control over network requests is a must.
The curl syntax follows this pattern:
curl [option] [url]curl retrieves the content from a URL and displays it in the terminal. Adding options allows users to customize the request, specify output files, include headers, authenticate, or change the request method.
wget vs. curl
Both commands transfer data from or to remote servers, but their design and use cases differ. wget handles straightforward file downloads, especially large or recursive downloads where reliability matters. curl offers more flexibility and often crafts custom HTTP requests, interacts with APIs, or uploads data.
wget handles automated scripts that require downloading entire sites or large files with minimal setup. On the other hand, curl is the go-to tool for developers who need full control over request headers, methods, and data formatting.
Installation
Before using wget or curl, ensure the tools are installed on your system. While many Linux environments include them by default, minimal or stripped-down systems sometimes leave them out. Verify the installation early to avoid errors during downloads or script execution.
wget Installation
wget usually comes preinstalled. If it's missing, take the following steps:
1. Update the system package repository using sudo:
sudo apt update
2. Install wget with:
sudo apt install wget
The command installs the core binary and usually pulls in required dependencies automatically.
However, there are possible errors.
If wget returns an error like:
Unable to establish SSL connection.It likely means the runtime OpenSSL library is missing or broken. wget relies on the library to handle secure HTTPS downloads.
Install the missing library with:
sudo apt install libssl3t64This package provides the necessary runtime support for SSL/TLS protocols. It is required for wget to access https:// URLs.
Note: This is only needed if the SSL library was not pulled in automatically during the wget install or if it was manually removed.
If you're compiling wget that links against OpenSSL, like from a source code, install the development package:
sudo apt install libssl-devThis package includes header files (.h) and symbolic links needed for compilation. It is not required for normal wget use. It is also usually part of the default installation.
Note: Installing libssl-dev is only necessary when building software, not for basic usage or runtime support.
3. Use the which command to verify the binary is available:
which wget
The output shows the path to wget. If the output is empty, wget is not in your system's PATH. Either fix the PATH or ensure the correct binary installation.
curl Installation
Like wget, curl is usually preinstalled on modern Linux systems. However, if it's missing, install it using the following steps:
1. Update the system package information:
sudo apt update2. Install curl:
sudo apt install curl
This command installs the main binary along with any required dependencies.
If curl returns an error like:
curl: (60) SSL certificate problem: unable to get local issuer certificateThis means the system is missing certificate authority (CA) certificates used to validate SSL connections.
To install CA certificates, run:
sudo apt install ca-certificatesThis package provides the root certificates required to verify SSL connections. Without it, curl fails when attempting to access HTTPS URLs. In newer distributions, the CA is installed together with curl.
Note: This issue is more common in stripped-down systems or containers where SSL validation is not preconfigured.
If you're compiling software that uses libcurl, install the development package:
sudo apt install libcurl4-openssl-dev
This package includes the headers and symbolic links needed to build against curl with OpenSSL support.
3. Verify curl installation with:
which curl
If the command returns a valid path, curl is on the system. If there is no output, verify the installation or inspect the PATH configuration.
Flexibility
Both wget and curl are powerful tools, but they differ in how flexibly they handle various data transfer tasks. The key differences are in how they process inputs, handle outputs, and interact with other tools or scripts.
curl has a modular architecture and is programmable. It is ideal for:
- Making REST API calls. Supports full HTTP customization, making it ideal for testing or automating API endpoints without using a separate client.
- Customizing headers. Sends authentication tokens or mimics browser requests when working with APIs or web apps.
- Sending JSON or form data. Submits form submissions or interacts with services that accept structured input.
- Handling cookies and authentication in detail. Supports multiple schemes like Basic, Bearer, and client certificates, making it suitable for secured endpoints.
- Controlling HTTP methods (GET, POST, PUT, DELETE). Interacts with REST APIs that use verbs to define operations beyond just fetching data, in which case, handling different HTTP methods is a must.
curl also supports piping data between commands, reading from standard input (stdin), and writing to standard output (stdout), which makes it easier to integrate into scripts and automated workflows.
However, wget is less versatile by design. It focuses on downloading files efficiently and reliably. It supports recursive downloads, retrying failed connections, and working in the background. However, it lacks the fine-grained control curl offers for request customization.
While wget supports POST requests and headers to some extent, it is limited compared to curl. It does not work for API testing or multipart uploads.
Protocols
curl supports more protocols than wget, making it better suited for complex data transfer tasks, scripting, or working with legacy and specialized systems. However, its support depends on the compilation options and linked libraries.
On the other hand, wget focuses on reliable downloading via HTTP, HTTPS, and FTP.
The following table shows which protocols each tool supports:
| Protocol | Description | Supported by |
|---|---|---|
| HTTP / HTTPS | Standard web protocols for accessing websites and APIs. | Both |
| FTP / FTPS | File Transfer Protocol; FTPS adds SSL/TLS encryption. | Both (FTPS limited in wget) |
| SCP / SFTP | Secure file transfer over SSH. | curl |
| LDAP / LDAPS | Directory service protocols with optional encryption. | curl |
| SMB | Network file sharing protocol (not Samba itself). | curl |
| TELNET | Unencrypted protocol for remote host access. | curl |
| DICT | Protocol for dictionary lookups. | curl |
| GOPHER | Legacy protocol for document distribution. | curl |
| MQTT | Messaging protocol used in IoT systems. | curl |
| IMAP / POP3 / SMTP | Email protocols used to send and retrieve messages. | curl |
| SNMP | Network monitoring protocol. | None |
Proxies
A proxy server is an intermediary between a client and the Internet. They control access, improve performance, or anonymize traffic. Enterprise networks use proxies to reach external resources.
Both wget and curl support proxy use, but they differ in how they handle configuration and the level of control they offer. The following aspects highlight the key differences:
- Configuration method. Both tools support proxy settings via standard environment variables such as
http_proxy,https_proxy,ftp_proxy, andno_proxy.
However,curlalso allows direct configuration in the command line using flags like--proxy,--proxy-user, and--noproxy.wgetlacks a command-line proxy override, relying instead on environment variables or.wgetrc. - Supported proxy types.
wgetsupports HTTP and FTP proxies.curlsupports those, plus SOCKS4 and SOCKS5, which are useful for tunneling and anonymity. - Authentication support.
wgetsupports basic proxy authentication, usually by embedding credentials in the proxy environment variable.curlsupports both basic and NTLM authentication, and credentials can be passed cleanly via the--proxy-useroption. - Granularity of control.
curloffers per-request proxy control, making it better suited for scripting and multi-target automation.wgetis more limited and applies proxy settings globally.
Authentication
Authentication is the process of verifying a user's identity before granting access to protected resources. In the context of data transfers, it ensures only authorized users or systems are able to retrieve, send, or modify files and data.
Tools like wget and curl interact with systems that require authentication, such as private APIs, FTP servers, or password-protected downloads. Since they are command-line-based, these tools allow users to script or automate access to such resources.
Both tools support authentication, but curl offers broader support and greater control. wget focuses on basic authentication and URL-embedded credentials.
The following list shows how curl and wget work with authentication systems:
- Basic authentication. This is the most common type of login both tools support. It involves sending a username and password to access a server. With
curl, use the-u username:passwordoption to accomplish this. Withwget, you are able to include the login info in the web address (URL) or store it in a settings file called.wgetrc. - Token-based and header authentication. Supported only by
curl. Some websites or APIs ask for a special key (called a token) instead of a password. Whilecurladds these tokens using the-Hoption,wgetdoes not support modifying headers dynamically. - Advanced protocols like NTLM. Supported by
curlusing the--ntlmflag. NTLM is a more complex login system that some Windows-based servers use.wgetdoes not support NTLM or similar advanced login types. - Credential separation and scripting. Easier with
curl. The command supports passing login info without putting it directly in the web address, which is safer and easier to manage in scripts.
File Upload
File upload refers to transferring a file from the local system to a remote server. It helps with API interactions, testing web forms, or sending data to FTP/SFTP servers.
While both wget and curl support downloading, only curl supports uploading files. wget lacks upload functionality because its developers designed it primarily for non-interactive downloads and did not include upstream data transfer support.
The following capabilities highlight how curl handles file uploads:
- HTTP and HTTPS uploads. Supports sending files to websites or services over the web using POST or PUT requests. This is useful when submitting files through online forms, testing APIs, or sending data to automated systems (like webhooks).
- FTP and SFTP. Allows file uploads to FTP and SFTP servers. Use the
-Tflag to specify the local file and the remote destination. - Header customization. Supports setting custom headers during upload, such as content type or authorization tokens, which modern APIs often require.
For example, if you want to upload a file to a specific location using curl, you need to send it to a server that accepts uploads. In this example, we will create a sample file and upload it to a public testing service that accepts HTTP POST requests, such as httpbin.
To accomplish that, take the following steps:
1. Use echo to create a test text file called example.txt:
echo "This is a test upload." > example.txtThe command has no output, but you are able to verify the file exists with ls:
ls -l example.txt
2. Upload the file using curl. This command sends the file to the test server as if you were uploading it through a form on a website. Run the following:
curl -X POST -F "file=@example.txt" https://httpbin.org/post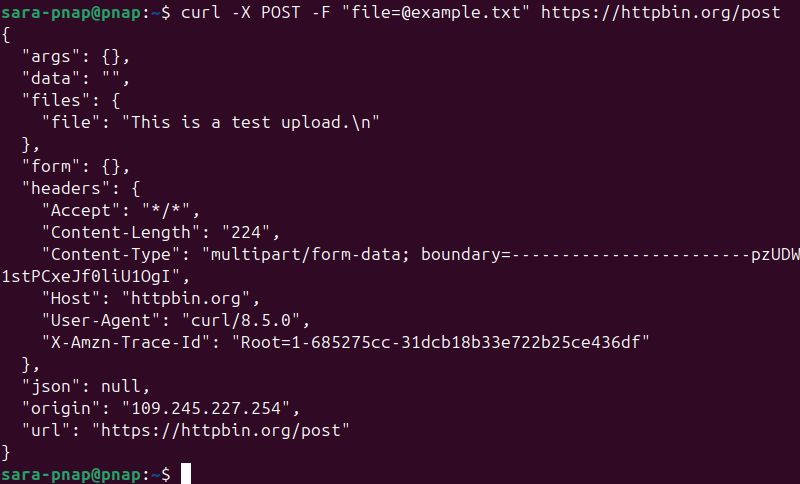
Make sure the URL includes /post. If you use just https://httpbin.org, the upload fails with a Method Not Allowed error.
3. If the command is successful, the server returns a JSON response confirming the file receipt. JavaScript Object Notation (JSON) is a structured format used to send and receive data between systems.
Look for the files field to verify the contents of the uploaded file.
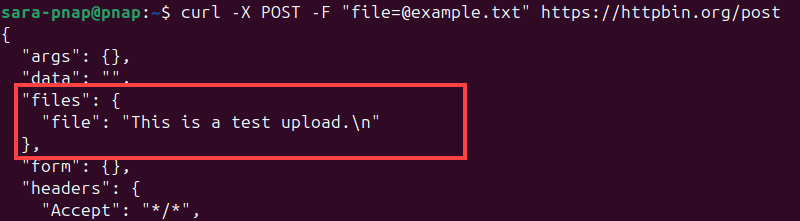
In our example, the files field contains the message "This is a test upload.\n", which is the content of the uploaded file.
On the other hand, to upload a file using a raw PUT request instead of a multipart form, use the -T option. For example:
curl -T example.txt https://httpbin.org/put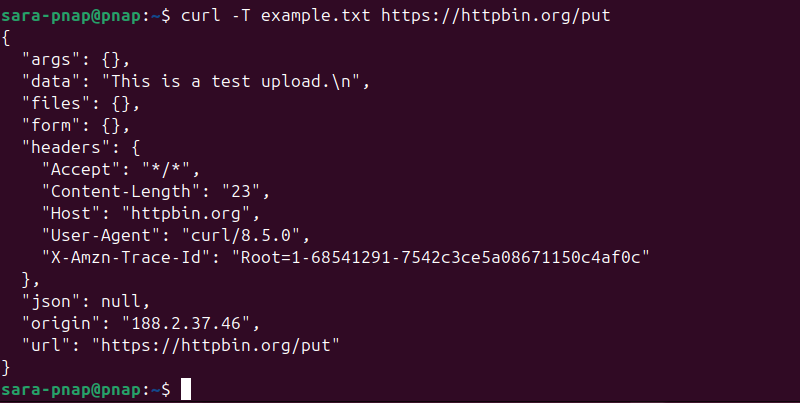
This sends the file example.txt directly as the request body to https://httpbin.org/put, which is useful for APIs expecting raw file data over PUT.
Recursive Download
Recursive download is the process of downloading a website or directory along with all linked files and subdirectories automatically. It is useful for mirroring entire sites, downloading complex file structures, or accessing content offline.
Note: Recursive downloads respect the site's robots.txt by default, which is a file that defines rules for web crawlers. Some websites restrict or block automated downloads to prevent abuse. Always check the terms of service and robots.txt before mirroring content (copying a website locally for offline access).
While curl does not support recursive downloads, wget supports recursive downloading natively. It follows links on web pages, and retrieves linked resources such as images, scripts, and stylesheets.
The general syntax for recursive downloads using wget is:
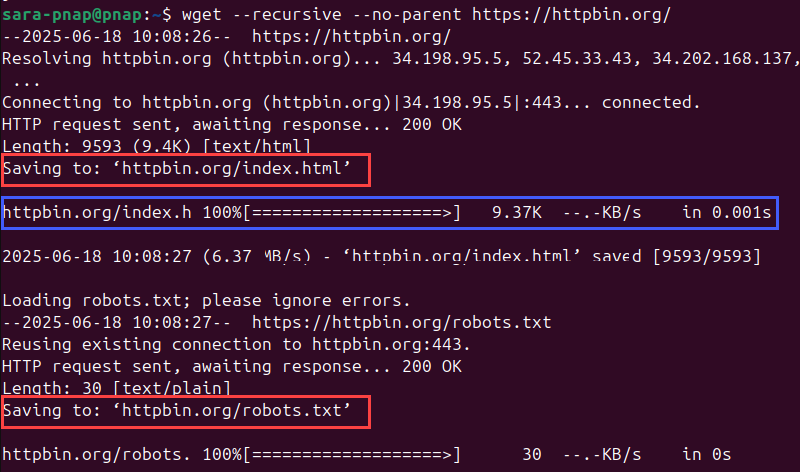
wget --recursive [options] [url]For example, to download the httpbin site and all of its contents, run:
wget --recursive --no-parent https://httpbin.org/The options used are:
--no-parent. Preventswgetfrom going up to parent directories outside the specified URL.--recursive. Enables recursive download of linked pages and resources.
If successful, the output shows a directory named httpbin.org containing HTML files and possibly subdirectories:

The following elements confirm the recursive download succeeded:
- Files saved locally (marked in red). Confirm
wgetis creating a local copy of the site structure and saving each file it downloads. - Followed internal links (marked in blue). Indicate
wgetis following links found within the HTML, fetching related assets like stylesheets, images, and scripts.
Cookies
Cookies store session-related information that servers use to identify and interact with clients. When downloading content from websites that require login or session tracking, both wget and curl support handling cookies.
This is especially useful when dealing with web applications that require you to stay logged in across multiple requests or need to pass a session token.
wget uses particular options to either store cookies from a session into a file or reuse them in later requests.
The general syntax is:
wget --save-cookies [file_name] [URL]For example, we'll use the httpbin site to save cookies set by the server into a file called cookies.txt.
Note: The httpbin homepage doesn't set cookies, so saving cookies there creates an empty file. To generate a cookie, use the /cookies/set?session=test123 endpoint, which sets a cookie named session with the value test123. You can replace this value as needed.
To accomplish this, run:
wget --save-cookies cookies.txt https://httpbin.org/cookies/set?session=test123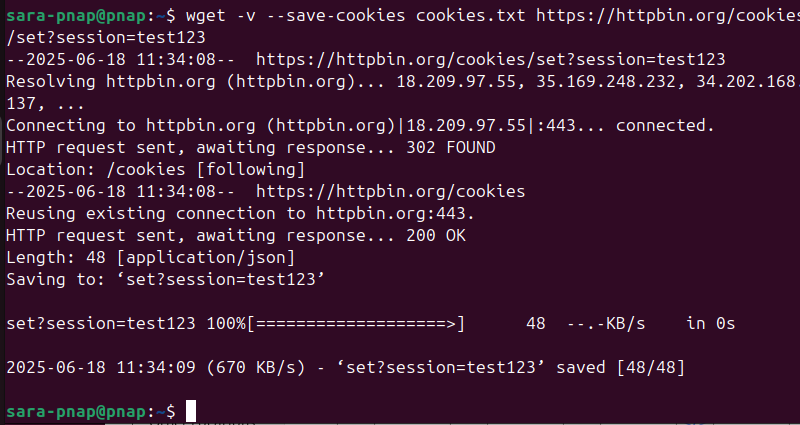
The wget output produces standard download output. However, it does not clearly indicate the cookies' status. Use cat to check the cookies.txt file. If the file contains cookie data (is not empty), the script saved the cookie successfully.
Run the following:
cat cookies.txt
Note: Running wget commands on testing services, like httpbin, designed to simulate HTTP requests and responses, often results in an empty cookies.txt file like in the image above. This behavior is different with curl, which saves cookies even in these scenarios.
To load the cookies, the syntax is pretty much the same: just replace --save-cookies with --load-cookies. For example, to load the saved cookies and make another request using the same session, run:
wget --load-cookies cookies.txt https://httpbin.org/cookiesThe command also provides standard download output without any cookie info. To check the cookies' status, examine the downloaded file as in the previous example.
Moreover, curl uses options to save cookies from a session into a file and reuse them in later requests. For example, to save cookies set by the server into a file called cookies.txt, run:
curl --cookie-jar cookies.txt https://httpbin.org/cookies/set?session=test123
By default, curl outputs the response body only. To verify the changes, check the contents of cookies.txt with:
cat cookies.txt
The output confirms the cookie named session with value test123 was successfully set and saved to cookies.txt.
To load the saved cookies and make another request using the same session, run:
curl --cookie cookies.txt https://httpbin.org/cookies
This command returns the current active cookies for the session. Unlike the original command used to save cookies, this one loads the cookies from cookies.txt and sends them back to the server.
To inspect the HTTP headers sent and received, as well as cookie details, add the verbose flag -v to either command. The flag prints headers such as Set-Cookie and Cookie, which confirms cookies are being set and reused.
For example:
curl -v --cookie-jar cookies.txt https://httpbin.org/cookies/set?session=test123
Note: Learn how to send cookies with cURL.
Resume Support
Resuming interrupted downloads is essential for reliability, especially for large files or unstable networks.
wget automatically resumes incomplete downloads when rerun with the same command. If a partial file exists, it continues from where it left off, with no extra options needed.
For example, to download the Java .deb package with wget, run:
wget https://download.oracle.com/java/21/latest/jdk-21_linux-x64_bin.deb
If the download stops, run the same command again to resume.
curl requires the -C - option to resume downloads. This flag tells curl to continue from the last byte received or start fresh if the file doesn't exist. To properly resume a partially downloaded file, also specify the -O flag to save the file using its remote name.
For example, to install Java .deb file, run:
curl https://download.oracle.com/java/21/latest/jdk-21_linux-x64_bin.deb
The output shows the Java download was interrupted, and the binary file wasn't saved properly. To fix this, run:
curl -C - -O https://download.oracle.com/java/21/latest/jdk-21_linux-x64_bin.deb
Retry Behavior
Retrying failed downloads is crucial for reliable automation, especially on unstable or slow networks. Unlike resuming, which continues a partially downloaded file, retrying restarts the download from the beginning after a failure.
wget retries failed downloads automatically up to 20 times. To limit the attempts, adjust the retry count with the -t option and optionally set a timeout using --timeout to control how long wget waits before considering a connection failed.
To retry failed downloads with wget, use the syntax below:
wget -t [number] [URL]For example, to retry a Java .deb file download three times with a 5-second timeout per attempt, run:
wget -t 3 --timeout=5 https://download.oracle.com:81/java/21/latest/jdk-21_linux-x64_bin.deb
The output shows the command attempting the download three times. Each attempt times out, and the process stops after the final retry.
curl does not retry failed requests by default. Use the --retry option with the desired number of retries. Optionally, add --retry-delay to set a wait time between attempts.
To enable retries with curl, use:
curl --retry [count] [URL]For example, retry the same Java download five times with:
curl --retry 3 --connect-timeout 5 https://download.oracle.com:81/java/21/latest/jdk-21_linux-x64_bin.deb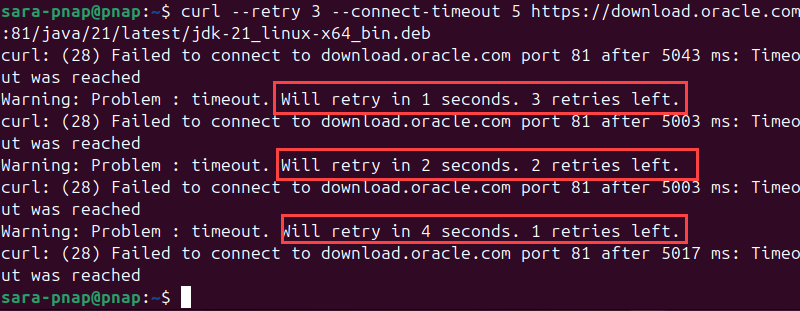
The output shows the command attempts to download the .deb file three times and displays the retry count after each failed connection.
Note: This example also uses port 81 intentionally to create a fake failed connection.
Timeout Controls
Timeout options prevent commands from hanging indefinitely by setting strict limits for connection and data transfer phases. This improves reliability on unstable or slow networks and avoids blocking scripts or automation pipelines.
wget uses a global timeout option, --timeout, which sets the maximum time for all stages combined (DNS resolution, connection, and data transfer). Additionally, wget offers granular timeout options to control individual phases:
--dns-timeout. Represents the maximum wait time for DNS resolution.--connect-timeout. Determines the time to wait for a connection to be established.--read-timeout. Sets the maximum time between data reads.
For example, to limit the entire download process to 10 seconds, run:
wget --timeout=10 https://download.oracle.com/java/21/latest/jdk-21_linux-x64_bin.debIn normal conditions, the output looks the same as a standard successful download, with no visible indication a timeout value was used.
curl separates timeout controls between connection and overall operation. The two types are:
--connect-timeout. Specifies the maximum time to wait for the connection phase.--max-time. Shows the total time allowed for the entire operation, including connection and data transfer.
However, unlike wget, curl does not provide separate timeouts for DNS resolution or read operations. Instead, it focuses on controlling the connection and total execution time, which covers the most common failure points in network transfers.
These options are especially useful when automating scripts that must abort cleanly if a remote host is unresponsive or too slow.
For example, to set a connection timeout of five seconds and a maximum total time of five seconds, run:
curl --connect-timeout 5 --max-time 5 https://download.oracle.com/java/21/latest/jdk-21_linux-x64_bin.debIf the timeout value isn't reached, the output looks like any normal download and doesn't mention the timeout setting. However, these timeout settings force curl to abort early on slow or unreachable servers, preventing scripts from hanging indefinitely.
Download Rate Limiting (Throttling)
Download rate limiting, also called throttling, helps prevent network saturation by capping the download speed. This is useful when downloading large files on shared or low-bandwidth connections.
wget supports throttling with the --limit-rate option. Specify the rate using a number followed by a unit (e.g., k for kilobytes, m for megabytes).
To limit the download rate with wget, use the syntax below:
wget --limit-rate=[amount] [URL]For example, to limit the Java .deb file download to 500KB/s, run:
wget --limit-rate=500k https://download.oracle.com/java/21/latest/jdk-21_linux-x64_bin.debMoreover, curl provides similar functionality using the same --limit-rate option and syntax:
curl --limit-rate [amount] [URL]For instance, to apply the same 500KB/s limit with curl, use:
curl --limit-rate 500k https://download.oracle.com/java/21/latest/jdk-21_linux-x64_bin.debNote: The output for both commands shows the regular download process. If the connection is fast, the lower speed is noticeable in the transfer rate section. Otherwise, there is no visible sign in the output indicating throttling is active.
wget vs. curl: Comparison Table and Overview
wget and curl are powerful command-line tools for transferring data, but they differ significantly in scope and behavior. Understanding these differences helps choose the right tool for automation, scripting, and network troubleshooting.
The table below summarizes key functionalities and how each tool handles them:
| Functionality | wget | curl |
|---|---|---|
| Installation | Preinstalled on many Linux systems. Install with apt, dnf, or a suitable command. | Preinstalled on most Linux systems. Install with apt, dnf, or a suitable command. |
| Flexibility | Focuses on downloading files and site mirroring. | Designed for flexible data transfer (download and upload) with APIs, protocols, and headers. |
| Protocols | Supports HTTP, HTTPS, and FTP. Limited FTPS support. | Supports many protocols, including HTTP(S), FTP(S), SFTP, SCP, LDAP(S), SMB, TELNET, DICT, MQTT, IMAP, POP3, SMTP. |
| Proxies | Supports HTTP and HTTPS proxies via environment variables. | Supports HTTP, HTTPS, and SOCKS proxies with fine-grained control via options. |
| Authentication | Supports basic HTTP and FTP auth with --user and --password. | Supports multiple methods: Basic, Digest, NTLM, Negotiate, Bearer tokens, and client certs. |
| File upload | Does not support file uploads. | Supports uploading via HTTP(S), FTP, SFTP with -T or -F. |
| Recursive download | Fully supports recursive site downloading with --recursive. | Does not support recursion; retrieves single resources only. |
| Cookies | Save with --save-cookies, reuse with --load-cookies. | Save with --cookie-jar, reuse with --cookie. Verbose mode shows Set-Cookie headers. |
| Resume support | Automatically resumes interrupted downloads on rerun. | Requires -C - to resume from the last byte. |
| Retry behavior | Retries failed downloads automatically up to 20 times. Use -t to configure attempts. | Does not retry by default. Use --retry and --retry-delay to enable. |
| Timeout controls | Uses --timeout (global). Also supports --dns-timeout, --connect-timeout, and --read-timeout. | Uses --connect-timeout and --max-time. No per-stage options. |
| Download rate limiting (throttling) | Use --limit-rate to restrict bandwidth (e.g., 500k). | Use --limit-rate with identical syntax. |
Conclusion
This article explained what wget and curl commands are, their syntax, and how they work. It also highlighted many similarities and differences between various command functionalities. Moreover, the text presented a comprehensive table summing up how both commands handle different features.
Next, learn about rsync, a command that efficiently synchronizes files and directories between systems.



