
In-memory databases (or in-memory stores) primarily rely on memory data storage rather than HDD or SSD. The database management system aims to accomplish fast query times by exchanging disk access for memory access, resulting in a quicker response time.
This article provides a comprehensive overview of in-memory databases.
What Is In-Memory Database?
An in-memory database is a database type that uses volatile memory (most often RAM or Intel Optane) as the primary data storage. Memory stores, by design, enable minimal response time and high latency. By eliminating the time needed to query data from disk, in-memory databases implement real-time responses to queries.
However, memory volatility makes these databases sensitive to crashes and downtime. Once shut down, all data on it is lost. Various logging mechanisms and hybrid modeling techniques address this issue to maintain database persistence.
How Does an In-Memory Database Work?
The data and instructions for an in-memory database reside in the main memory, usually RAM. This approach reduces the I/O requests to the disk and improves overall database speed. Storing data in memory enables direct access to information and dramatically reduces the time needed to query data.
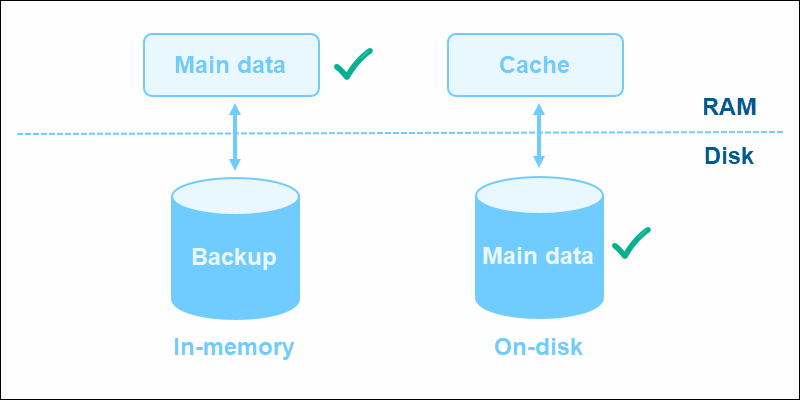
In-memory databases use specialized data structures to store data in the main memory. The data is immediately usable, avoiding processes such as translating, caching, or compressing information to a disk. The data types are designed with scalability in mind.
All in-memory databases support ACID transactions, with additional workarounds to provide durability and avoid data loss in case of a crash.
Advantages and Disadvantages of In-Memory Databases
An in-memory database has both benefits and drawbacks. Analyzing both the pros and cons of in-memory databases helps determine in which cases to use it.
Below is a brief list of the advantages and disadvantages of using an in-memory database.
Advantages
Some advantages an in-memory database can bring are:
- Processing speed. The most obvious advantage when using an in-memory database is the speed of read and write operations. Since the database is not disk-based, additional optimization techniques, such as parallel processing, are possible.
- Real-time insight. Embedded analytics offers immediate business insights, reports, and alerts, allowing data-based business decisions to occur faster and more often.
- Simultaneous OLAP and OLTP support. In-memory databases eliminate transfer delays between transactions and analytics. The database supports structured and unstructured data, which caters to modern big data businesses.
- Reliability. In-memory databases handle workload spikes by design. Retrieving information takes nanoseconds instead of milliseconds, which makes a big difference in sudden traffic increases.
Disadvantages
The disadvantages that come from implementing an in-memory database are:
- Risk of data loss. Since in-memory databases use volatile memory, the storage is temporary. The database risks losing all data and requires extra safety measures.
- High cost. RAM is more expensive than storage disks. Due to the database relying on memory data storage, the overall costs associated to in-memory databases are higher than those of a traditional on-disk database.
- Architecture complexity. The database resides on RAM, which automatically makes less RAM available for other operations. A solution is to implement grid computing, which increases architecture complexity.
In-Memory Database Examples
In-memory databases find many applications and use cases. The database is an excellent choice for the following two general use cases:
- A program or application uses read operations more often than write.
- Real-time data is of utmost importance or a huge benefit to the business.
Note: If you're looking for an in-memory database with high performances that's open source, Redis is a good choice.
Check out our installation guides for the following OSes:
Below are some examples of where in-memory stores find applications:
- IoT and edge computing. IoT sensors stream massive amounts of data. An in-memory database can store and perform calculations using real-time data before sending it to an on-disk database.
- Ecommerce applications. Shopping carts, search results, session management, and quick page loads are all possible with an in-memory database. Fast results provide the user with a better overall experience, regardless of traffic surges.
- Gaming industry. The gaming industry uses in-memory databases for updating leaderboards in real time, which is especially important for building engagement.
- Real-time security and fraud detection. In-memory databases help perform complex processing and analytics in real time, making them a perfect choice for fraud detection.
Note: Try phoenixNAP's Bare Metal Cloud Memory instances, which specialize in large memory workloads. The servers come with 768GB of RAM and easily scale out.
How to Implement In-Memory Database?
Implementing an in-memory database requires additional workarounds to provide database durability. Some example mechanisms to enforce durability are:
- Persisting data to disk at intervals through snapshots. If snapshots are set up at regular time intervals as scheduled jobs, the mechanism brings partial durability.
- Using non-volatile memory, such as flash memory or NVRAM.
- Logging all transactions to journal files with automatic recovery.
- Database replication to other in-memory databases on different sites or in combination with on-disk storage.
Ideally, combining the methods provides a highly available and durable database.
Conclusion
After reading this article, you should better understand in-memory databases, their importance, and their application for real-life use cases.
Next, learn about distributed databases, which work as an ideal solution for in-memory databases.



