External tables help manage data stored outside of Hive. Database administrators can import data from external files into Hive without changing where the data is stored, enabling access to data from various sources within Hive.
This tutorial shows how to create, query, and drop an external table in Hive.

Prerequisites
- Access to the command line/terminal with a sudo user.
- Apache Hadoop installed and running.
- Apache Hive installed and running.
- Access to the file system where the data is stored (HDFS).
Note: This tutorial uses Ubuntu. However, Hive works the same on all operating systems with Hadoop set up.
Create an External Table in Hive
The syntax to create an external table in Hive is:
CREATE EXTERNAL TABLE [table_name] (
[column_name_1] [column_datatype_1],
[column_name_2] [column_datatype_2]
...
[column_name_n] [column_datatype_n]
)
ROW FORMAT [format_type]
FIELDS TERMINATED BY '[delimiter]'
STORED AS [file_format]
LOCATION '[hdfs_path]';The query contains the following:
CREATE EXTERNAL TABLE [table_name]. Creates an external table named[table_name]. AddIF NOT EXISTSbefore the table name to perform a check if a table with an identical name already exists in the database.[column_name] [column_datatype]. The column name and datatype for each column.ROW FORMAT [format_type]. The data format per table row. Rows use native or custom SerDe (Serializer/Deserializer) formats. The default isdelimitedif no format is provided.FIELDS TERMINATED BY '[delimiter]'. The table row delimiter. Defaults to the CTRL+A (\001) character if unspecified.STORED AS [file_format]. Defines the storage format. The default value isTEXTFILE.LOCATION '[hdfs_path]'. The HDFS path to the external data.
Use the above syntax as a reference when creating an external table in Hive. Replace all placeholders with the actual values.
To try the query using a hands-on example, follow the steps below.
Note: The syntax for creating a table in Hive that is not external is different. It does not include the EXTERNAL keyword or the file storage information.
Step 1: Create External Data (Optional)
Before creating an external table, prepare or create external data that the external table will reference. This step is optional but required if you do not have external data.
To create sample data, do the following:
1. Create a file with CSV data. For example, if using the nano text editor, run the following command in the terminal:
sudo nano [file_name].csvThe command opens the file for editing.
2. Add data to the file in CSV format. For example:
id,name,department
1,John,Engineering
2,James,Marketing
3,Jacob,Sales
The sample data contains simple employee information, including their names and departments.
3. Save the file and close nano. The file's location is required for the following step.
Step 2: Import File to HDFS
To use the file in Hive, import it into HDFS. Follow the steps below:
1. Start all Hadoop services (HDFS and Yarn). Run the following script:
start-all.sh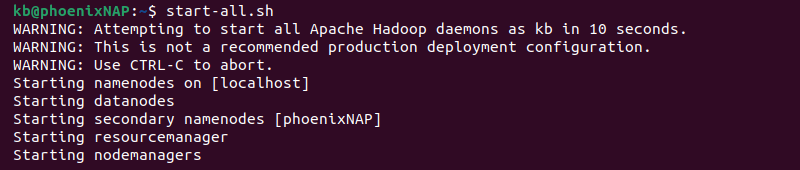
The script automatically starts all Hadoop daemons.
2. Create a HDFS directory. For example, if working with employee data, create an employees directory:
hdfs dfs -mkdir /user/hive/warehouse/employeesThe directory is the HDFS external file location.
Note: HDFS is a critical component of Hadoop architecture. It serves as the main storage system for Hadoop applications.
2. Import the external file into HDFS:
hdfs dfs -put [source] /user/hive/warehouse/employeesProvide the file's source path and file name. The destination is the directory path from the previous step.
3. Verify the file is in the HDFS directory:
hdfs dfs -ls /user/hive/warehouse/employees
The command shows all the files in the directory, including the CSV file.
Step 3: Create an External Table
After adding the CSV data file to HDFS, continue by connecting to Hive and apply the syntax above to create an external table.
1. Start the Hive CLI:
hive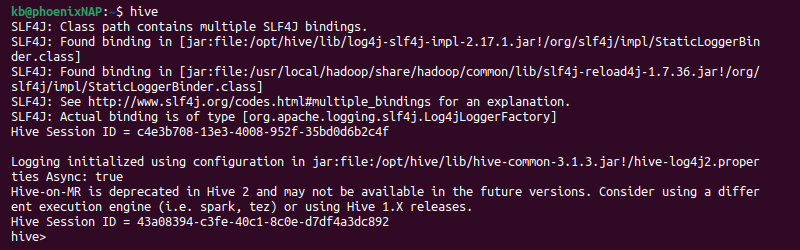
The shell session switches to Hive.
2. Use the syntax above to create an external table that matches the external file's data. If using the example CSV file, the query looks like the following:
CREATE EXTERNAL TABLE employees (
id INT,
name STRING,
department STRING
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE
LOCATION '/user/hive/warehouse/employees/';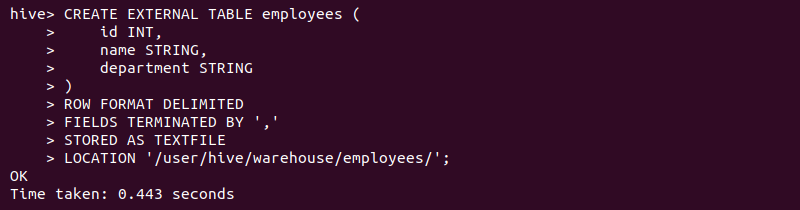
The query maps to the CSV file and applies its data as if it were an internal Hive table.
Note: The query also adds the first row from the CSV file, typically the column labels. Remove the first row manually, drop the existing table, and re-create the external table.
How to Query a Hive External Table
The querying process is similar to a managed (internal) Hive table. Describe the table to see basic schema information:
DESC [table_name];
Run queries on the table just like with any Hive table. Common queries include:
- Select all data:
SELECT * FROM [table_name];
- Select specific columns:
SELECT [column_name_1], [column_name_2] FROM [table_name];
- Filter data based on a value:
SELECT * FROM [table_name] WHERE [column_name] = '[value]';
Replace all placeholders in the commands to match your table data.
How to Drop a Hive External Table
To drop an external table in Hive, use the regular DROP TABLE syntax:
DROP TABLE [table_name];
The output confirms the operation was successful. Querying the table is no longer possible. However, the CSV data file remains and can be retrieved by creating a new external table.
Hive Internal Tables vs. External Tables
Hive categorizes tables into internal (managed) and external tables. Choosing the right type is crucial for efficient data management. The table below provides an in-depth comparison between internal and external tables in Hive.
| Feature | Internal (Managed) Tables | External Tables |
|---|---|---|
| Definition | Hive manages the data and metadata. | Data is external. Metadata is managed by Hive. |
| Data Location | Default Hive location in HDFS (/user/hive/warehouse). | Specified external location. |
| Data Lifecycle | Changes in Hive affect the data (e.g., move, delete, rename). | Changes in Hive do not affect the data and vice versa. |
| Drop Table | Deletes the schema and data. | Deletes the schema; data remains in an external location. |
| Data Integrity | Hive guarantees data integrity and consistency. | Hive does not monitor changes; data integrity is handled externally. |
| Use Cases | Best for data managed in Hive or temporary data. | Best for shared data and external datasets. |
Conclusion
This guide provided a practical example of creating an external table in Hive. It also explained how to query data from an external table and the key differences between an internal and an external Hive table.
Next, see our in-depth comparison between Hadoop vs. Spark.