Federated learning is an innovative machine learning paradigm that trains AI models on decentralized data. The paradigm is gaining popularity across various industries and becoming an essential tool for balancing data privacy, security, and performance.
This article explains the concept and mechanics of federated learning, its definition, types, benefits, available frameworks, applications, and challenges.

What Is Federated Learning?
Federated learning is a decentralized approach to training AI models. Instead of collecting data in one central location, it allows multiple devices or servers to train a shared model. However, their data remains on a local site.
This technique addresses privacy concerns as no raw data is transferred and enhances security since it complies with data protection regulations. Each device trains the model on its data and shares only model updates, which are then aggregated to improve the global model.
Federated learning is useful for applications that require privacy, such as healthcare, finance, and mobile AI services. It significantly reduces the need for large data transfers, making it efficient for edge computing and real-time AI applications.
How Does Federated Learning Work?
The process of federated learning involves a base (global) model and multiple devices that train the model based on their information. Each device trains the model with local data but keeps the raw information on-device.
The steps outlined in the section below explain how federated learning works and provide an idea of the federated learning workflow.
Federated Learning Steps
Federated learning follows a structured process that involves multiple iterations of training and aggregation to refine the model over time. The steps are explained in the sections below.
Step 1: Global Model Initialization
The process begins by creating a global model on a central server. The model parameters are either randomly generated or loaded from a pre-trained version.
The initialization ensures that all participants start with the same baseline model.
Step 2: Distributing the Model to Clients
The server selects a group of participating clients (such as smartphones, IoT devices, or organizations) and sends them the model.
Not all available clients are chosen in every round because too many at once can slow down training without significantly improving results.
Step 3: Local Training on Client Devices
Each selected client trains the model using its local dataset. Instead of fully training the model, clients perform a limited number of training steps.
This approach allows for incremental learning and keeps computation efficient.
Step 4: Sending Model Updates to the Server
Once the local training is completed, clients send their updated model parameters to the central server. Since each client has trained on different data, the updates reflect unique learning from each local dataset.
Clients either send full model parameters or just gradient updates.
Step 5: Aggregating Updates
The server collects and combines all the updates into a new global model. One common aggregation method is Federated Averaging (FedAvg), where updates are averaged based on the number of training examples each client uses.
Aggregation ensures that larger datasets contribute more to the final model while maintaining balance across all participants.
Step 6: Repeating the Process
The updated global model is sent back to a new set of clients, and the process repeats. With each round, the model learns from more data but remains decentralized. The cycle continues until the model reaches an optimal performance level.
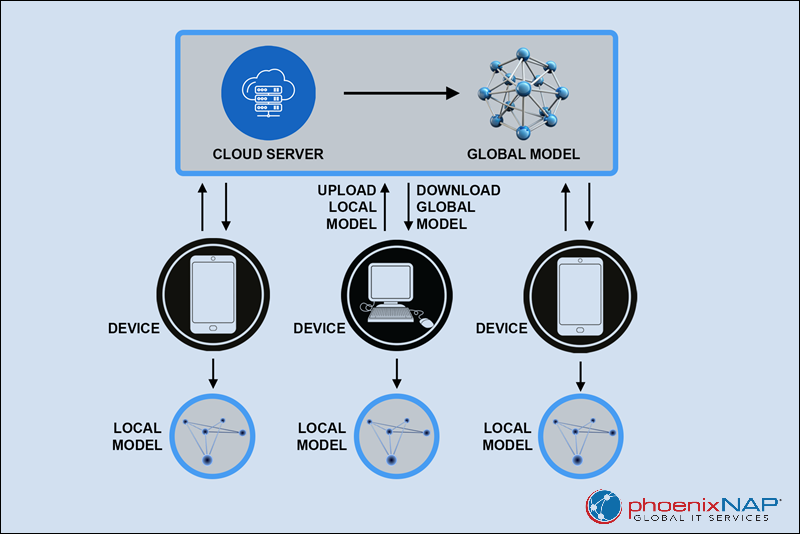
By repeating the steps outlined above, federated learning enables collaborative model training without direct access to sensitive user data, which significantly improves privacy and security.
Types of Federated Learning
There are two primary categories of federated learning:
- Centralized vs. decentralized
- Horizontal vs. vertical
The division is based on the network architecture and the data distribution among participants. However, in terms of the scale and stability of participants, there is another layer of classification, Cross-silo vs. cross-device.
This classification distinguishes between the scale and stability of participants. The sections below explain each type of federated learning.
Centralized vs. Decentralized Federated Learning
The division into centralized and decentralized federated learning is based on network architecture. It depends on whether a central server coordinates training or the participants communicate directly.
Centralized Federated Learning
Centralized federated learning uses a central server to coordinate the training process. Each client trains a local model on its data and then sends the updated parameters to the central server. The server aggregates these updates to create a global model and redistributes it to the clients.
The key features of centralized federated learning are:
- Coordination. A central server organizes the training, aggregation, and distribution.
- Aggregation. All model updates combine at a single point.
- Control. The server manages the training process, which simplifies oversight.
Decentralized Federated Learning
Decentralized federated learning removes the need for a central server. Instead, participants exchange model updates directly with one another. This approach minimizes the risk of a single point of failure and improves overall privacy through distributed aggregation.
The key features of decentralized federated learning include:
- No central authority. Clients communicate directly without relying on a central server.
- Robustness. The system remains resilient even if one node fails.
- Enhanced privacy. Distributed aggregation reduces the risk of data exposure.
Horizontal vs. Vertical Federated Learning
On the other hand, the division into horizontal and vertical federated learning depends on data distribution, that is, whether the participants have the same features with different samples or different features for the same samples.
Horizontal Federated Learning (HFL)
Horizontal federated learning applies when multiple participants hold datasets with similar features but different sample sets. Each participant has data with an identical structure but on distinct individuals or events. The similar features enable a joint model to learn from diverse but structurally consistent data sources.
The participants benefit from horizontal federated learning by training a shared model without exchanging raw data. For instance, several banks may use HFL to build a fraud detection model while keeping their transaction records private. The HFL method works best when all parties hold data with the same features.
Vertical Federated Learning (VFL)
Vertical federated learning suits cases where participants have data on the same set of entities but with different features. Each participant has unique attributes related to the same individuals or events. This structure allows the combination of complementary information to create a richer, more complete model.
VFL helps organizations join forces and maintain data privacy. An example use case involves a retail company and a bank that share customer insights. The retail company provides purchasing data, while the bank offers financial data. Both parties share only intermediate computations, which build a comprehensive model without exposing raw data.
Cross-Silo vs. Cross-Device Federated Learning
The division into cross-silo and cross-device federated learning distinguishes between the scale and stability of participants.
Cross-Silo Federated Learning
Cross-silo federated learning works with a limited number of trusted participants, often organizations or institutions. These silos offer stable computational resources and reliable network connections. The controlled environment enables each participant to contribute large data volumes to a common model.
The key features include:
- Few participants. The collaborators are a small number of reliable entities.
- Stable environment. Each silo provides robust computational and networking capabilities.
- Large data holdings. Participants typically contribute significant datasets.
Cross-Device Federated Learning
Cross-device federated learning involves many devices, such as smartphones, IoT gadgets, or edge devices. Each device contributes a small dataset and may face unstable network conditions. Despite these challenges, the aggregation of many small contributions forms a reliable global model.
The key features are:
- Many participants. Numerous devices join the training process.
- Variable reliability. Devices have limited resources and intermittent connectivity.
- Small data volumes. Each device contributes a modest amount of data.
Benefits of Federated Learning
Federated learning offers multiple benefits, especially in terms of privacy and efficiency. It minimizes the risk of data breaches by keeping personal data on local devices. This decentralized approach also supports compliance with data protection laws.
The advantages of federated learning include:
- Enhanced privacy. Data remains on the device, reducing exposure.
- Reduced communication costs. Only model updates are exchanged.
- Real-time personalization. Models can update quickly with local data.
- Scalability. Many devices can participate simultaneously. These benefits make federated learning a valuable tool for industries handling sensitive information.
Federated Learning Frameworks
Implementing federated learning requires specialized frameworks designed for secure, distributed model training. These frameworks provide tools for managing decentralized data, handling privacy concerns, and optimizing training efficiency.
The table below shows the top five federated learning frameworks, along with their key features:
| Framework | Key features | Use case |
|---|---|---|
| TensorFlow Federated (TFF) | Built on TensorFlow, supports custom federated algorithms, integrates with existing ML workflows. | Research and experimentation. |
| PySyft | Focuses on privacy-preserving AI, supports secure multi-party computation and differential privacy. | Privacy-focused federated learning. |
| FedML | Lightweight, cross-platform, supports edge devices, cloud, and IoT applications. | Large-scale deployment and edge computing. |
| Flower | Flexible, framework-agnostic, easy integration with PyTorch, TensorFlow, and JAX. | General federated learning applications. |
| NVIDIA FLARE | Optimized for healthcare and enterprise AI, supports multi-institution collaboration. | Federated learning in healthcare and finance. |
Each framework plays a crucial role in advancing federated learning, making decentralized AI more accessible and effective across different industries.
Applications of Federated Learning
Federated learning is transforming industries through decentralized, privacy-preserving AI. Through AI training decentralization, federated learning enables industries to harness machine learning while safeguarding data privacy and operational security.
Some of the key applications of federated learning include:
- Mobile AI. Federated learning powers on-device AI in smartphones. It improves predictive text, voice assistants, and facial recognition but keeps user data private. Training the models locally reduces bandwidth usage, enhances personalization, and mitigates security risks.
- Healthcare. Hospitals and research institutions use federated learning to develop AI models without sharing patient data. Doing so ensures compliance with regulations like HIPAA and GDPR. This approach enhances diagnostic accuracy and enables collaboration across diverse datasets.
- Autonomous vehicles. Self-driving cars require real-time decision-making, which can be hindered by cloud-based AI training. Federated learning allows vehicles to refine navigation models locally, share insights on road conditions, and reduce latency.
- Smart manufacturing. Predictive maintenance in factories benefits from federated learning by training AI models on local data. It prevents downtime while keeping proprietary information secure. This approach also ensures compliance with cross-border data laws and optimizes energy efficiency in industrial settings.
- Robotics. Federated learning enhances multi-robot collaboration. It allows robots to train on local experiences and exchange model updates efficiently. The technology benefits swarm robotics and warehouse automation, where communication bandwidth is limited.
Challenges and Limitations of Federated Learning
While federated learning offers significant advantages in privacy and decentralized training, it also comes with challenges.
The list presents some challenges and limitations of federated learning:
- Ethical considerations and data access. Federated learning allows organizations to train models on sensitive data that would otherwise be inaccessible due to privacy regulations. Although expanded data access leads to more accurate and inclusive models, it raises ethical concerns about data security, informed consent, and potential biases in the resulting models.
- Device variability and synchronization. It is a challenge to coordinate training across a diverse network of devices. Clients may have different hardware capabilities, network conditions, and dataset sizes. Dropouts can disrupt learning, while slower devices delay the entire process.
- Decentralized training and model aggregation. Federated learning trains models locally on individual devices. These devices send updates to a central server. Aggregation techniques like FedAvg are essential for combining these updates effectively. The challenge is to ensure that updates from varied and non-uniform datasets contribute to a robust and generalized global model.
- Evolving security and privacy. As federated learning advances, so do the methods to enhance its security. Techniques such as secure multi-party computation and homomorphic encryption help address privacy concerns. These solutions protect data integrity during model training without exposing raw data.
- Non-identical data distributions (non-IID data). One of the fundamental challenges in federated learning is non-IID data, where datasets across different client devices do not follow the same distribution. Unlike centralized learning, federated learning must handle skewed, biased, or incomplete data from various sources. This variability complicates training and requires specialized optimization techniques.
Despite these challenges, federated learning is rapidly evolving, with ongoing research pushing the boundaries of decentralized AI. As new advancements emerge, solutions to these obstacles will continue to improve, making federated learning more practical across industries.
Conclusion
Federated learning represents a shift toward decentralized machine learning. It improves privacy, reduces communication costs, and supports real-time personalization. Despite its challenges, it offers significant potential in sectors with sensitive data.
Next, check out our article on private AI or learn about AI in business, its challenges, and regulations.