
The Tensor Processing Unit (TPU) and Graphics Processing Unit (GPU) are two widely used accelerators for machine learning (ML) and high-performance computing (HPC). While both serve the purpose of workload optimization, the units differ in design, use cases, and compatibility with other hardware.
This article provides a detailed comparison between TPUs and GPUs, focusing on their architecture, performance, and practical implications for AI applications.

What Is TPU?
The Tensor Processing Unit (TPU) is a custom-built integrated circuit developed by Google. It is designed for accelerating machine learning workloads, particularly those created using TensorFlow. Unlike general-purpose processors, the TPU is optimized for mathematical operations used in neural networks.
Note: The term tensor represents the data structures (multidimensional arrays, i.e., scalars, vectors, and matrices) utilized in machine learning.
The following sections explain the mechanism behind TPUs, their use cases, and their advantages and disadvantages in real-world deployments.
How Does TPU Work?
TPUs use a matrix processing architecture known as a systolic array. This architecture enables efficient execution of large-scale matrix multiplications, which are core operations in deep learning algorithms.
Each TPU contains multiple processing elements that execute instructions in a lock-step rhythm, i.e., the elements perform the same operation at the same time on different pieces of data. This technique ensures that the data passes through a fixed path with minimal memory access overhead.
Instead of general-purpose instruction sets, TPUs use a data path tailored to tensor algebra. This feature allows them to perform many operations in parallel, reducing latency and increasing throughput for specific neural network computation types.
TPU Use Cases
TPUs are typically employed in environments where training and inference of deep learning models are frequent and performance-critical.
Typical TPU applications include:
- Image classification with convolutional neural networks (CNNs).
- Natural language processing with transformers.
- Recommendation systems in large-scale web services.
- Real-time language translation.
Since TPUs are integrated into Google Cloud, enterprises use them to efficiently train massive AI models that would otherwise take days or weeks on standard hardware.
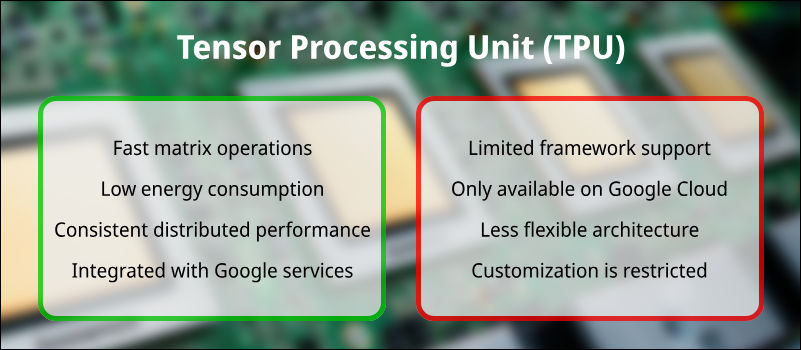
TPU Advantages
TPUs offer performance aligned with AI workloads, especially TensorFlow-based. Their primary advantages include:
- High throughput for matrix-heavy operations such as convolutions and dense layers.
- Lower energy consumption per operation compared to GPUs and CPUs.
- Consistent performance across large-scale distributed AI training tasks.
- Built-in support within Google's managed services ecosystem, including Vertex AI.
TPU Disadvantages
Despite their many strengths, TPUs have limitations that affect their versatility, such as:
- Limited framework compatibility. TPUs work best with TensorFlow and lack full support for PyTorch.
- Restricted availability. TPUs are currently only accessible via Google Cloud.
- Fixed-function architecture. TPUs are less flexible than GPUs for non-AI tasks or irregular computational patterns.
- Insufficient low-level customization capabilities. Hardware and software abstraction layers introduce overhead and limit the ability to fine-tune the system for specific applications.
What Is GPU?
A Graphics Processing Unit (GPU) is a parallel processor originally built for rendering images and graphics. Over time, the GPU architecture proved to be well-suited for scientific computing, data analytics, and machine learning due to its parallelism and programmable nature.
GPUs are now fundamental for AI development. They are widely supported across platforms, frameworks, and deployment environments.
How Does GPU Work?
A GPU contains thousands of small cores that execute operations in parallel. Unlike TPUs, GPUs are general-purpose accelerators that can handle a wide variety of computational tasks. They rely on software platforms like CUDA (for NVIDIA GPUs) and OpenCL to run parallel programs across these cores efficiently.
The specific architecture makes GPUs especially good at handling large datasets, running multiple training jobs simultaneously, and executing diverse AI architectures without requiring specialized hardware.
In GPUs, core design drives performance. CUDA Cores excel at general-purpose tasks, while Tensor Cores are built for deep learning. See how they compare in our article on Tensor Cores vs. CUDA Cores.
GPU Use Cases
GPUs are used extensively in fields beyond AI, including computer graphics, video rendering, and scientific simulations.
In AI and data science, their primary use cases include:
- Training deep learning models using TensorFlow, PyTorch, or JAX.
- Real-time inference in applications like autonomous vehicles and virtual assistants.
- HPC simulations in physics and biology.
- Data visualization and processing in analytics pipelines.
Since both open-source and commercial tools widely support GPUs, they are the go-to choice for most researchers and developers.
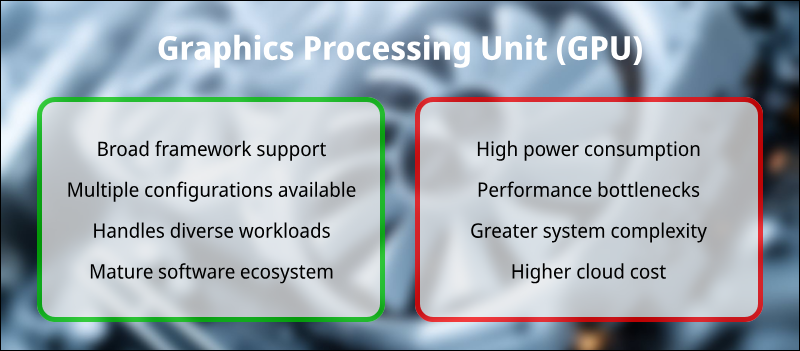
GPU Advantages
GPUs provide flexibility, accessibility, and high computational power. Their key advantages are:
- Broad support across frameworks and programming environments.
- Availability in a range of configurations for consumers and data centers.
- Capability to handle diverse workloads beyond AI, including 3D rendering and simulations.
- Mature software ecosystems, especially with NVIDIA's CUDA platform.
GPU Disadvantages
The limitations of GPUs, particularly when compared to task-specific hardware like TPUs, include:
- Higher power consumption under AI-specific workloads.
- Potential performance bottlenecks in matrix-dense operations.
- Added complexity when working with large-scale distributed training systems.
- Generally a higher cost-to-performance ratio in cloud environments compared to TPUs (for TensorFlow-specific tasks).
TPU vs. GPU: Comparison
While both TPUs and GPUs are frequently chosen for AI projects, their designs and ideal use cases are different. The table below contains a breakdown of how the units compare on performance, scalability, and other key factors:
| TPU | GPU | |
|---|---|---|
| Performance | Better for large matrix operations. | Strong for varied parallel workloads. |
| Scalability | Well-integrated with Google Cloud infrastructure. | Scales across cloud, edge, and local setups. |
| Availability | Google Cloud only. | Available from multiple vendors and platforms. |
| Software | Best with TensorFlow. | Supports TensorFlow, PyTorch, CUDA, and OpenCL. |
| Hardware | Custom ASICs with fixed capabilities. | General-purpose hardware with more flexibility. |
| Artificial intelligence | Optimized for deep learning models. | Supports diverse AI architectures. |
| Pricing | May lead to a lower total project cost, but Google decides on pricing. | Diverse offering, potentially lower initial investment. |
Performance
TPUs often outperform GPUs in deep learning workloads that rely on matrix multiplication. Their hardware is specialized for these tasks, allowing more efficient processing.
GPUs provide strong performance when running diverse models or working with non-tensor operations.
Scalability
TPUs scale effectively within the Google Cloud environment using managed AI services.
GPUs can scale across multiple environments, e.g., on-premises clusters, public cloud platforms, and edge devices. This feature provides more deployment flexibility.
Availability
TPUs are currently only available through Google Cloud. This restriction denies access to organizations that choose not to participate in Google's ecosystem.
GPUs are available from vendors like NVIDIA, AMD, and Intel. All major cloud providers and local hardware suppliers support them.
Software
TPUs primarily support TensorFlow, which limits their use in projects that require other frameworks.
GPUs offer broad compatibility with AI tools and libraries, including TensorFlow, PyTorch, and custom CUDA-based applications.
Hardware
TPUs use a fixed-function ASIC design, offering better power efficiency for specific tasks. However, this feature introduces less flexibility.
GPUs use a programmable architecture, supporting a wider range of algorithms and use cases, both inside and outside of AI.
Artificial Intelligence
TPUs provide fast, energy-efficient training and inference for TensorFlow-based AI models.
GPUs support a wide range of AI workloads, including real-time inference, large-scale training, and multi-modal learning systems.
Pricing
TPUs are a Google Cloud exclusive, which ties users to Google's pricing. However, their efficiency for specific workloads can lead to a lower total project cost, especially for large-scale tasks well-suited to the architecture.
GPUs offer more control and flexibility. They are available for rent from various cloud providers or for purchase as one's own hardware.
TPU vs. GPU: How to Choose
Choose TPUs:
- If the project uses TensorFlow only and runs on Google Cloud.
- When power efficiency and high performance in AI workloads are critical.
- For training massive models with Google's infrastructure and tools.
Choose GPUs:
- If the model requires PyTorch or needs local deployment capabilities.
- When flexibility, accessibility, and a wide software ecosystem are more important.
- For running mixed workloads, including AI, rendering, and simulation.
Conclusion
After reading this comparison article, you are better prepared to make a choice between TPUs and GPUs for your development project. The guide presented both accelerators, their advantages and disadvantages, and offered advice on how to choose between them.
Next, learn how to set up machine learning environments on our Bare Metal Cloud GPU instances, or discover the differences between an LPU and GPU.