
Machine learning (ML) enables us to build computer systems that learn from input data and improve with use. Instead of following strict instructions, machine learning systems autonomously identify patterns and relationships in provided data to make decisions or take action.
This adaptability allows ML-trained systems to tackle complex problems and operate in dynamic environments where traditional rule-based systems are ineffective.
This article takes you through everything you must know about machine learning, from its core principles to wide-ranging applications. Read on to learn what machine learning offers and see how businesses use this tech to get a decisive competitive edge.

New to the idea of ML? Our intro to neural networks is a great starting point if you want to learn how computers simulate the way biological neurons work together to process information.
What Is Machine Learning?
Machine learning is a subset of artificial intelligence (AI) focused on creating algorithms capable of learning from and adapting to input data. ML enables us to create computer systems that learn from provided data and iteratively improve performance without requiring explicit programming.
All ML-trained systems perform one of two very broad tasks: they either classify data (e.g., is there another car on the road, or is this email spam or a legitimate message) or make predictions about future outcomes (e.g., will the stock go up, or which YouTube video does the user want to watch next).
Once someone creates and trains an ML algorithm, the end result is a machine learning model. A model is a program that ingests previously unseen input data and produces a certain output. We then embed the model into hardware or deploy it to the cloud to build a real-world product. Once deployed, companies use ML models to:
- Analyze vast amounts of data to uncover hidden insights and trends.
- Detect anomalies or unusual data patterns indicative of potential risk.
- Make continuous predictions (e.g., predicting house prices or potential sales revenue).
- Group similar data points into clusters, as you would do during customer or market segmentation.
- Classify data into different categories or classes.
How well an ML model performs depends primarily on the quality of its training data. When trained on high-quality data sets, ML models effectively capture and learn underlying patterns and relationships within inputs. If you train a model on low-quality or incomplete data, its output will be largely inaccurate and unreliable.
According to the 2023 AI and Machine Learning Research Report, 72% of surveyed companies claim that ML is part of their IT and business strategies. Organizations primarily use machine learning to improve existing processes (67%), predict business performance (60%), and reduce risk (53%).
How Does Machine Learning Work?
Once deployed to a real-world setting, a machine learning model receives input data from its environment (from edge servers, sensors, online databases, etc.). This input data must be similar to the data the model was trained on and can be in various forms (text, numbers, images, audio files, video, etc.).
Most ML data sets require some preprocessing to remove noise and handle missing values. More advanced use cases also require admins to extract relevant features before providing the model with input. This process, called feature extraction, identifies the most useful information in the data set.
Let's say you're trying to predict whether someone will buy a product based on their purchase history. In this example, relevant features might include:
- The total amount of money spent.
- The frequency of purchases.
- Types of products bought in the past.
These features provide the model with insights into the customer's purchasing behavior and history, enabling the system to make more accurate predictions.
Upon receiving input data, the model applies the knowledge gained during training to make decisions. This process, known as inference, enables a model to make predictions or decisions on previously unseen data based on what it learned from training and past experience.
A machine learning model can use different algorithms to analyze input data and arrive at conclusions. There are various types of algorithms, each designed for different types of tasks and data:
- Logistic regression, decision trees, and support vector machines (SVMs) are the most common choices for classification problems.
- Linear regression and random forests are go-to algorithms for regression problems (i.e., predicting variables).
Note: Refer to our article to learn more about regression algorithms: the definition, the types, and when to use them.
ML models are often integrated into larger software systems or workflows. Many models must interact with other system components, such as databases, APIs, or user interfaces, to fulfill their intended purpose.
Types of Machine Learning
There are three different types of machine learning: supervised learning, unsupervised learning, and reinforcement learning. Each type has its own strengths, weaknesses, and suitable use cases. The choice between the three depends on the purpose of the ML model and available training data.
Supervised Machine Learning
Supervised learning is a type of ML in which the algorithm learns exclusively from labeled data. These training data sets consist of input-output pairs in which each input is associated with a known output label. For example, in spam email detection training, the input might be the contents of an email, and the output label would indicate whether that specific email is spam or not.
During training, the algorithm learns to approximate the mapping between inputs and outputs by adjusting its internal parameters. This process involves minimizing a loss function, which measures the difference between the predicted outputs and the actual labels in the training data.
Supervised learning is suitable for the following tasks:
- Binary classification. The model divides data into two categories.
- Multiclass classification. The model selects from multiple types of answers.
- Ensembling. The model combines the predictions of multiple ML models to produce a more accurate prediction.
- Regression modeling. The model predicts values based on relationships within data.
Supervised learning is the go-to choice for solving predictive tasks, and when you have high-quality labeled data sets. This type of machine learning is widely used in various domains, including natural language processing (NLP), computer vision, finance, healthcare, and many others.
While gathering labeled data is often challenging and expensive, supervised learning is the most effective method for training deep neural networks.
Learn how organizations leverage artificial intelligence to optimize and speed up business operations by reading our guide to artificial intelligence (AI) in business.
Unsupervised Machine Learning
Unsupervised learning is a type of ML in which the algorithm learns from unlabeled data, meaning the input data lacks corresponding output labels. The goal of unsupervised learning is to allow the ML model to learn from data without explicit guidance.
Unlike supervised learning, where the algorithm learns to map predefined inputs to outputs, unsupervised learning seeks to find hidden patterns or insights within the intrinsic properties of the data. This type of machine learning excels at two types of tasks:
- Clustering. The goal is to group similar data points into clusters, where data points within the same cluster are more similar to each other than to those in other clusters. Common clustering algorithms include k-means clustering, hierarchical clustering, and DBSCAN.
- Dimensionality reduction. The goal here is to reduce the number of features in the data while preserving as much relevant information as possible. Principal Component Analysis (PCA) and t-distributed Stochastic Neighbor Embedding (t-SNE) are the most popular dimensionality reduction algorithms.
Evaluating the performance of unsupervised learning algorithms is more challenging compared to supervised learning. There are no labels to compare the accuracy against, so adopters assess the quality of the learned representations with evaluation metrics. Two go-to metrics are silhouette scores for clustering and the explained variance ratio for dimensionality reduction.
Unsupervised learning has a wide range of applications across various domains. The four most common use cases are customer segmentation, anomaly detection, pattern recognition, and data visualization.
Some adopters opt for the so-called semisupervised approach in which the algorithm learns from a combination of labeled and unlabeled data. This strategy offers a middle ground between the efficiency of supervised learning and the exploratory nature of unsupervised ML.
Reinforcement Learning
Reinforcement learning is a type of ML where the model learns by interacting with an environment and gathering immediate feedback. There are three main components in reinforcement learning:
- The agent. The decision-maker who interacts with the environment.
- The environment. The external system or problem that the agent interacts with.
- Action policies. The policies that dictate what actions the agent can take in the environment.
The agent selects actions based on a current policy, observes the resulting state of the environment, and updates the policy based on observed outcomes. This process continues iteratively as the agent learns from experience and refines its decision-making strategy.
The agent receives feedback from the environment in the form of rewards or punishments based on its actions. The agent's goal is to learn how to maximize the cumulative reward over time and positively interact with the environment.
All reinforcement learning algorithms must balance exploration (i.e., trying new actions to discover potentially better strategies) and exploitation (i.e., using known strategies to maximize immediate rewards). This balance is crucial for the agent to learn efficiently and adapt to the environment.
Reinforcement learning has a wide range of use cases, including game playing, robotics control and navigation, autonomous vehicles, recommendation systems, and resource management.
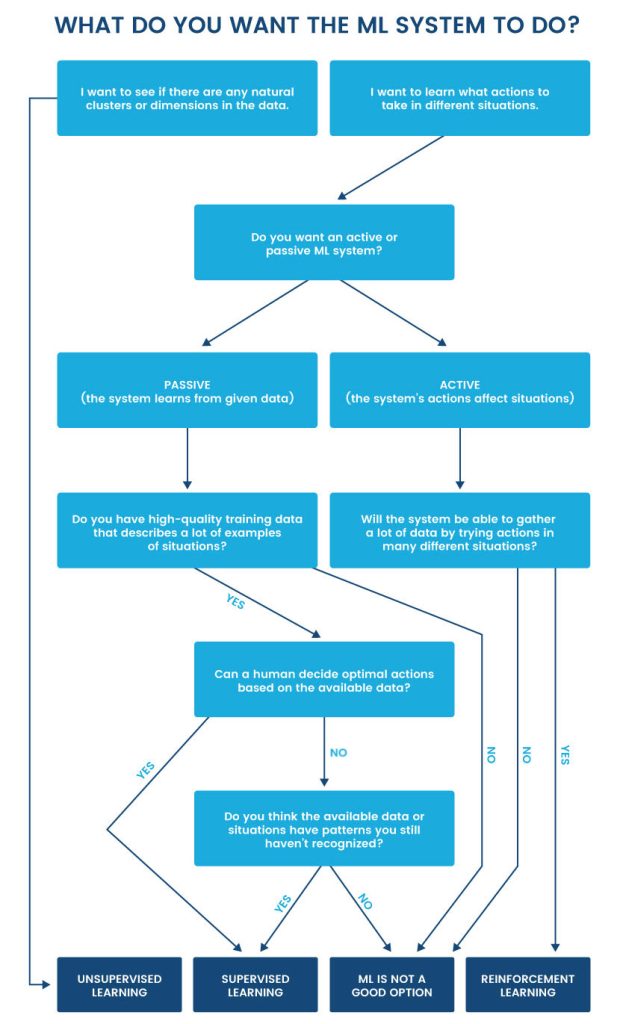
Learn more about supervised and unsupervised machine learning and how they differ.
Benefits of Machine Learning
Machine learning offers a wide range of business benefits that speed up work and improve operational efficiency. Here are some of the main benefits of training and using ML models:
- Task automation. ML algorithms are excellent at automating repetitive tasks. Many organizations use ML to automate tasks such as data entry, document classification, email filtering, reporting, and data cleaning.
- In-depth data analysis. ML algorithms can analyze large volumes of data to identify trends and insights that may not be apparent to humans. This in-depth analysis enables businesses to make data-driven decisions with greater accuracy and confidence.
- Better productivity. In addition to automating routine tasks, ML can also augment human decision-making by providing insights and recommendations that streamline work processes.
- Increased employee satisfaction. Delegating repetitive tasks to ML-powered systems frees up the workforce from low-value and time-consuming duties.
- Enhanced customer experience. ML-powered applications can personalize customer interactions, anticipate user needs, and deliver tailored recommendations. These capabilities lead to a more engaging and satisfying customer experience with 24/7 availability.
- Cost reductions. ML offers numerous cost-saving opportunities. Organizations can automate routine tasks, reduce operational inefficiencies, and lower the likelihood of costly errors.
- Better risk management. ML algorithms reliably detect risks such as equipment defects, behavior anomalies, and compliance violations. Many businesses use machine learning to mitigate risks, prevent fraud, and ensure regulatory compliance.
Want a tighter grip on your IT expenses? Our guide to IT cost reduction presents 12 tried-and-tested strategies for boosting IT cost-effectiveness.
Challenges of Machine Learning
Adopting ML poses several challenges that can be potential deal-breakers depending on your business needs and available resources. Here are the most notable drawbacks of machine learning:
- Training data availability. ML models require large volumes of high-quality data for successful training. Issues like missing values, incomplete records, and data silos can hinder a company's ability to train an ML model effectively.
- Skills gap. There is currently a shortage of skilled data scientists, engineers, and AI specialists with expertise in developing ML solutions. Businesses often struggle to recruit and retain top talent with the necessary skills to manage ML projects.
- Overfitting issues. Overfitting occurs when a model performs well on training data but generalizes poorly to unseen data. Adopters must put the model through extensive training and testing to ensure it performs reliably in real-world scenarios.
- Model interpretability. Advanced ML models tend to be complex and opaque, making it difficult to interpret the algorithm's decisions. Teams often encounter challenges related to the model's transparency, which poses a significant obstacle in heavily regulated industries.
- Infrastructure demands. ML projects require significant computational resources and a highly scalable infrastructure. Many adopters face challenges in provisioning and managing the infrastructure for large-scale ML projects.
- Integration with existing systems. This process is particularly challenging when dealing with legacy apps that lack compatibility with ML frameworks. Businesses often must invest in middleware, code rewrites, and custom integrations to ensure seamless performance.
High performance computing (HPC) servers are among the most suitable infrastructure types for machine learning. HPC clusters easily handle compute-intensive ML workloads thanks to parallel processing, high scalability, and specialized hardware accelerators.
Machine Learning Applications & Examples
Machine learning use cases are diverse and span across various industries, from healthcare and finance to e-commerce and entertainment. Here are some of the most common ML applications:
- Image recognition and classification. ML-trained systems are excellent at analyzing visual data and identifying objects and patterns in images. Examples include facial recognition systems and medical imaging apps for analyzing X-rays, MRIs, and CT scans.
- Natural language processing. NLP apps leverage machine learning techniques to understand, interpret, and generate human language. Common uses of ML in this domain are chatbots, virtual assistants (Siri, Alexa, Google Assistant), and sentiment analysis tools.
- Recommendation systems. Many recommendation systems employ ML algorithms to analyze user preferences. Product recommendation engines used by platforms like Amazon or Netflix and music recommendation systems like Spotify and Pandora all rely on machine learning.
- Predictive analytics. Organizations often use machine learning techniques to analyze historical data and predict future events or outcomes. Usual examples include using ML to forecast sales or product demand, optimize supply chain management, and predict customer churn rates.
- Robotics. Autonomous vehicles and robotics use machine learning to perceive their surroundings, make decisions, and navigate the environment. Self-driving cars, autonomous drones, industrial robots, and cobots (collaborative robots) are common use cases.
- Predictive maintenance. Companies often use ML techniques to create predictive maintenance systems. These systems monitor equipment health, detect anomalies, and help schedule maintenance tasks.
- Cybersecurity use cases. ML-powered systems are excellent at detecting anomalies or behaviors that fall outside of the usual norm. Many intrusion detection systems (IDSes) and cybersecurity tools use ML to identify suspicious activity and potential network security breaches.
While highly useful, ML models are limited to performing relatively simple tasks. More complex use cases require the development of deep learning models, which you can quickly train with one of these deep learning frameworks.
Use ML to Streamline Operations and Get a Competitive Edge
As available data volumes grow, computing power increases, and ML specialists gain more experience, machine learning will continue to challenge conventional business practices. Companies unwilling to adapt are bound to be left behind, so use what you learned here to assess what areas of your business would benefit the most from machine learning models.
Find out how ML differs from AI in our comparison article AI vs. machine learning.



