
A deep neural network (DNN) enables machines to learn complex patterns and representations from data with unprecedented accuracy. When adequately trained, DNNs allow machine learning (ML) models to reliably interpret images, mimic realistic human-like speech, and even generate pieces of art.
This article provides an in-depth guide to deep neural networks. Jump in to learn how DNNs work and see why this tech is driving advancements in computer vision, natural language processing (NLP), and speech synthesis.

Our intro to deep learning provides an excellent starting point if you are new to neural networks.
What Is a Deep Neural Network?
A deep neural network is a type of artificial neural network (ANN) with multiple layers between its input and output layers. Each layer consists of multiple nodes that perform computations on input data. Another common name for a DNN is a deep net.
The "deep" in deep nets refers to the presence of multiple hidden layers that enable the network to learn complex representations from input data. These hidden layers enable DNNs to solve complex ML tasks more "shallow" artificial networks cannot handle.
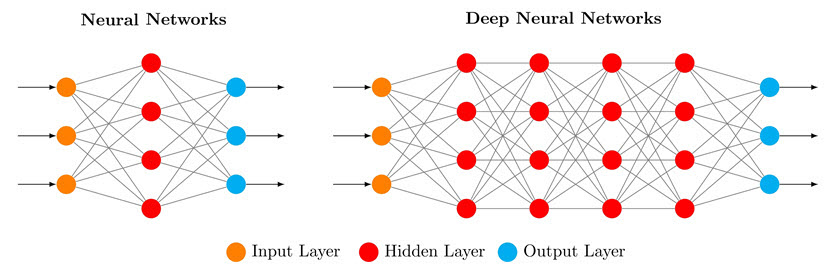
Hidden layers in a DNN are dense (fully connected) layers. Each neuron in a dense layer is connected to every neuron in the previous and subsequent layers, which makes DNNs highly suitable for learning complex relationships in data.
Hidden layers within a deep neural network are not simple copies of each other. Instead, a DNN has a complex layer structure with a variety of different layer types, such as:
- Convolutional layers that apply a series of learnable filters to input data.
- Long short-term memory (LSTM) layers that capture dependencies in sequential data.
- Gated recurrent unit (GRU) layers that use gating to control the flow of network info.
- Attention layers that focus on specific parts of the input sequence when making predictions.
- Normalization layers that stabilize and accelerate the training of the deep neural network.
The more hidden layers a deep net has, the better it becomes at learning from and processing input data. While a network requires only two layers to be considered "deep," DNNs commonly have 100+ hidden layers between their input and output nodes.
Neural Nets: A Historical Overview
As a concept, neural networks are over 70 years old. Researchers Warren McCulloch and Walter Pitts laid the conceptual groundwork for these networks during the late 1940s.
McCulloch and Pitts proposed that simple computational units, mimicking the behavior of neurons in the human brain, could be connected to form complex networks capable of computation. The lack of sufficient hardware prevented researchers from going far from theoretical work, but these early ideas laid the foundation for today's neural networks.
During the 1960s and 1970s, interest in neural networks continued with the development of the Perceptron. The Perceptron was an ANN with a single hidden layer that classified input data into two categories. This invention was one of the first instances of a trainable network and demonstrated the potential of neural networks for pattern recognition tasks.
Further breakthroughs occurred in the 1980s and 1990s when Paul Werbos and David Rumelhart developed backpropagation (short for "backward propagation of errors"). Backpropagation provided an efficient way for training multi-layer networks by adjusting neuron connections based on output errors.
During the 2000s, researchers continued experimenting with neural networks, but other ML techniques overshadowed these projects. Computational resources were still insufficient for the effective use of deep nets, and we lacked the large-scale data sets needed for model training.
The 2010s marked a turning point for deep learning and neural networks. Advancements in hardware, particularly the availability of powerful graphics processing units (GPUs), enabled more efficient training of deep nets. The explosion of big data also provided the data sets necessary for training deep neural networks.
Learn about GPU computing and see how GPUs can act as "coprocessors" to CPUs to drastically accelerate workloads.
How Deep Neural Networks Work
Deep nets are composed of multiple layers of interconnected nodes called neurons or units. There are three types of layers in a DNN:
- Input layer. The input layer receives raw data. Each node in this layer represents a feature or attribute of the input data. For example, to interpret 28x28 pixel images, the input layer requires 784 nodes, each representing pixel intensity (ranging from 0 to 255).
- Hidden layers. DNNs have two or more hidden layers sandwiched between input and output layers. Each hidden layer comprises multiple neurons, which are connected to neurons in both adjacent layers. However, neurons within the same layer are not connected to each other.
- Output layer. The output layer produces the network's final predictions. The number of neurons in the output layer depends on what tasks the network is performing.
Once you provide raw data, the input data is fed forward through the network layer by layer. At each layer, neurons apply assigned activation functions and pass the processed output to the next layer.
Here are a few common activation functions:
- Sigmoid. This function squashes the input values between 0 and 1, making it suitable for binary classification problems.
- Tanh (Hyperbolic Tangent). Tanh squashes the input values between -1 and 1, making it suitable for classification and regression tasks.
- ReLU (Rectified Linear Unit). ReLU sets negative input values to zero and leaves positive input values unchanged.
- Softmax. This function converts raw scores into probabilities, ensuring that the output values sum up to 1.
Once the deep net produces an output, it compares its predictions to set targets provided by the DNN admin. An objective or loss function quantifies the difference between the expected and actual output. Then, errors propagate backward through the network, adjusting neuron connections to minimize errors.
Neural Nets and Weightiness
In a deep neural network, each connection between neurons in adjacent layers is associated with a weight. Weights are numerical values that represent the strength of the neuron's connection and determine how much influence the output of one neuron has on the input of another.
Weights are either positive or negative, depending on the strength of influence neurons have on each other:
- Positive weights. When a connection has a positive weight, an increase in the output of the sending neuron leads to an increase in the activation of the receiving neuron. In that case, the sending neuron's activity encourages the activation of the receiving neuron.
- Negative weights. A negative weight means an increase in the output of the sending neuron leads to a decrease in the activation of the receiving neuron. In that case, the sending neuron's activity inhibits the activation of the receiving neuron.
When a DNN is still untrained, the weights are assigned random values. During training, the deep neural network adjusts weights iteratively in response to the difference between the expected and actual output.
Weights play a crucial role in both propagation (i.e., sending data to the next layer of the DNN) and backpropagation (i.e., sending data to the previous layer of the deep net):
- During propagation, each neuron computes the weighted sum of inputs from connected neurons in the previous layer. The neuron then applies an activation function to this weighted sum to produce an output.
- During backpropagation, the error signal propagates backward through the network, and the network adjusts weights to minimize this error signal.
Weight optimization is crucial to training a neural network, as weights determine how well the network learns from training data. Well-optimized weights enable the network to learn meaningful patterns from input data and make accurate predictions.
What Is a Deep Neural Network Used For?
DNNs have become a powerful tool across various domains due to their ability to learn complex patterns from large amounts of data. Here are a few use cases that commonly involve the use of a deep neural network:
- Image recognition. Deep nets excel at object detection and image classification. Organizations train DNNs to accurately identify and classify objects within images, making these networks invaluable in surveillance systems and industrial quality control.
- Natural language processing. DNNs are widely used for sentiment analysis, machine translation, and text summarization. A deep neural network can understand and generate human-like text, making this tech ideal for chatbots, virtual assistants, language translation services, and social media monitoring.
- Speech synthesis. DNNs are excellent at generating human-like speech from text inputs.
- Recommender systems. Many organizations use deep nets to build recommender systems that analyze user preferences and provide recommendations for products and content. These systems are widely used by e-commerce platforms, streaming services, and social media platforms.
- Healthcare use cases. DNNs assist radiologists in detecting abnormalities in medical images, help identify patterns in genomic data, and analyze patient data for early disease detection.
- Finance and trading use cases. DNNs can analyze large volumes of financial data to identify fraudulent transactions, assess risks, predict market trends, and optimize trading strategies.
- Retail use cases. Retailers often use a deep net for inventory management, shelf monitoring, and customer behavior analysis through surveillance cameras.
- Autonomous vehicles. DNNs play a crucial role in autonomous vehicles as deep nets improve object identification, lane detection, and pedestrian recognition.
- Environmental monitoring. DNNs can analyze satellite imagery and sensor data to monitor deforestation, climate patterns, and wildlife conservation efforts.
Want to start using a deep neural network at your company? You can use one of these deep learning frameworks to significantly speed up the training of your new DNN.
Deep Neural Networks Challenges
Deep nets offer significant capabilities, but this tech also comes with several challenges you must know about before you start training a DNN. Let's look at the most common challenges organizations face when using deep neural networks.
Training Data Quality and Quantity
Adopters require large amounts of high-quality labeled data to train a DNN and enable it to generalize well to new inputs and unseen examples. Quality data is expensive and time-consuming to obtain, particularly in domains where labeled data is difficult to acquire.
The data you inject into a deep net's input layer must have high levels of:
- Accuracy. Labeling errors or general inaccuracies in training data often lead to the model learning incorrect patterns and making wrong predictions.
- Representativeness. The training data must cover the full range of variations and scenarios the model is expected to encounter during its use. Gaps in the training data lead to biased, incomplete, or wrong predictions.
- Cleanness. Noisy or outlier data points introduce confusion during training and degrade the model's capabilities.
Improving the quality and quantity of training data involves careful data collection, annotation, preprocessing, and validation. Data augmentation is also helpful as it increases training data size by generating extra examples via transformations like rotation, scaling, cropping, and adding noise.
Computation and Memory Requirements
Most adopters must invest in expensive GPUs and tensor processing units (TPUs) to create a sufficiently powerful infrastructure for DNN training. These accelerators provide parallel computation essential to performing numerous forward and backward passes through the network to update weights.
DNNs also require significant amounts of memory to store model parameters during training. Memory consumption scales with the following factors:
- Size of the network architecture.
- The batch size (i.e., how many input samples are processed simultaneously during each iteration).
- The size of the input data.
The high demands of training DNNs also lead to considerable energy consumption, especially when you use power-hungry hardware accelerators. Energy-efficient training algorithms, hardware designs, and model optimizations are essential to mitigating the environmental impact of DNNs.
One of the most effective ways to solve the high computation demands of deep nets is to use HPC servers. These servers greatly speed up DNN training with parallelism, distributed computing, ample memory resources, and specialized hardware accelerators.
DNN Training Issues
The two most common challenges of training a deep neural network are overfitting and underfitting. These problems affect the model's ability to generalize well to previously unseen data.
Overfitting occurs when a model learns to memorize the training data's noise and specific patterns instead of capturing underlying relationships between features. As a result, the model performs well on the training files but poorly on unseen data.
Overfitting often arises when the model is too complex relative to the amount of available training data. The usual signs of overfitting are high training accuracy but low validation and erratic or oscillating learning curves. Here are the most effective ways to prevent overfitting in a deep neural network:
- Use regularization methods, dropout, and early stopping to prevent over-reliance on specific features.
- Augment data to artificially increase the size and diversity of the training data set.
- Adjust the depth or width of the deep net to match the problem complexity and the available training data.
Underfitting occurs when a model is too simple to capture the underlying structure of the data. This issue leads to poor performance on both the training and validation/test data sets. Here are a few effective ways to prevent this problem:
- Increase the model's complexity by adding more layers, neurons, or parameters.
- Provide the model with more informative input features.
- Increase the size or diversity of the training data set.
Another common problem in training a DNN is when gradients vanish as they propagate through the network. This issue hinders the convergence of optimization algorithms, making training difficult or slow.
Hyperparameter Tuning
DNN hyperparameters govern the behavior and performance of the deep net. You set these parameters before the training process begins to align the deep neural network with your objectives. These are the essential DNN hyperparameters:
- Learning rate.
- Batch size.
- Number of layers.
- Number of per-layer neurons.
- Regularization strength.
- Dropout rate.
- Activation functions.
- Optimization algorithms.
The choice of hyperparameters significantly influences the model's capabilities. Suboptimal settings lead to slow convergence, poor performance on the training and validation data sets, and difficulty generalizing to unseen data.
Different hyperparameters interact with each other in complex ways, which further complicates the search for an optimal configuration. Most adopters decide to iteratively test different combinations of hyperparameters to evaluate their impact on model performance. This process is time-consuming and requires careful analysis of training metrics.
Adversarial Attacks
Adversarial attacks are malicious attempts to deceive or manipulate a trained deep net with subtle alterations in input data. Malicious actors apply these small changes (often referred to as perturbations) to input data with the goal of causing misclassifications within the model.
There are two types of adversarial attacks:
- Non-targeted attacks in which perturbations cause misclassification without targeting any specific class.
- Targeted attacks in which perturbations cause the model to misclassify the input sample as a specific target class.
Adversarial attacks pose severe security concerns to DNNs, especially in safety-critical domains. For example, these attacks can cause autonomous vehicles to misclassify traffic signs or medical image analysis systems to provide incorrect diagnoses.
Here are a few effective ways to prevent adversarial attacks:
- Augment the training data set with adversarial examples or perturbations.
- Train the model on softened logits to make the DNN more resistant to perturbations.
- Hide or obfuscate model gradients to prevent attackers from gathering info about the deep net.
- Combine predictions from multiple models or adversarially trained models to improve robustness.
Expanding your IT in any way introduces new attack vectors via which a malicious actor could breach your systems. Learn how to manage your attack surface and ensure adding new technologies does not expose you to unnecessary risks.
A Whole New World of Business Opportunities
Deep neural networks (DNNs) are a fantastic resource that enables us to run advanced machine learning (ML) tasks with record-breaking accuracy. They power a wide range of applications, from natural language processing and computer vision to predictive analytics and autonomous systems. Their layered architecture enables the identification of complex patterns and correlations in large datasets that traditional algorithms often miss.
Now that you know how DNNs work and what using them entails, you have all the information you need to evaluate whether your organization would benefit from setting up and training a deep neural network.



