Most machine learning (ML) models either classify data (e.g., does this image contain a cat or a dog) or make predictions (e.g., what will the temperature be next week). All ML models that make predictions rely on regression algorithms to analyze provided data, identify relationships between relevant variables, and forecast future outcomes.
This article takes you through the most commonly used regression algorithms in machine learning. Jump in to see the different types of algorithms ML models use to make data-driven predictions.

New to the concept of ML? Our comparison of supervised and unsupervised learning provides a great starting point if you want to learn how we "teach" machines to perform tasks.
What Is Regression?
Regression is a statistical method for modeling the relationship between a dependent variable (target) and one or more independent variables (predictors). The goal of regression is to understand how changes in one predictor affect the target variable.
Think of regression as finding the relationship between two things so you can predict one based on the other. For instance, consider predicting your grocery spending based on the number of items you purchase. If you look at past grocery bills and count the items you bought, you'll notice that more items usually mean a higher bill.
Regression lets you draw a line through your data points (i.e., pairs of values representing the number of items bought and the corresponding grocery bill) to see this pattern. Once you have this line, you can use it to predict future bills based on the number of items you plan to buy.
Similarly, organizations use regression to figure out correlations between variables, which enables them to:
- Predict values based on historical data (e.g., predict the price of an apartment based on the number of rooms and location).
- Forecast future trends (e.g., project sales numbers based on historical data and economic indicators).
- Identify risk levels (e.g., determine disease risk factors based on patient data).
- Make data-driven decisions (e.g., determine which investment to buy based on available market data).
A regression task always involves predicting a continuous numerical value. The primary objective is to model the relationship between a continuous dependent variable and one or more independent variables.
For example, in predicting house prices, the target variable is the house price, which is a continuous numerical value. The predictors could include the size of the house, the number of bedrooms, and the location. Regression finds a mathematical function that best describes how changes in predictors impact the house price.
Let's cement your understanding of regression with a quick knowledge check. Which of the following is a regression task:
- Predicting a person's age.
- Predicting a person's nationality.
- Predicting whether a stock price will increase tomorrow.
- Predicting whether an email is spam or a legitimate message.
Answer: Predicting a person's age is the only regression task here because age is a continuous numerical value. All other options are classification tasks: nationality is a categorical variable, predicting stock price has a binary outcome (increase or not), and spam checks determine whether an email belongs in a specific category (i.e., genuine or spam).
How Is Regression Used in Machine Learning?
Regression is a fundamental machine learning technique that enables ML models to perform the following tasks:
- Predict continuous values. Regression analysis enables ML models to predict continuous numerical values, such as predicting sales revenue based on advertising spend.
- Identify relationships between variables. ML models often use regression to identify which features have the most significant impact on the target variable. For example, regression algorithms can reveal how much temperature, humidity, and wind speed each contributes to predicting energy consumption.
- Make long-term forecasts. Regression enables ML systems to perform time series forecasting (i.e., predictions of events through a sequence of time). Common examples include predicting long-term stock prices and product demand.
- Detect anomalies. Regression helps identify outliers or anomalies by identifying data points that do not fit the expected pattern. For example, companies often use regression to flag transactions that differ significantly from the norm, which helps with fraud detection.
Many ML adopters feed their models with noisy data since preprocessing data is not cost-effective or time-efficient. Regression's ability to effectively handle noisy or fluctuating input makes this technique highly valuable in machine learning.
Regression also assists in feature selection by revealing which variables have the most significant impact on the predicted outcome. This capability is helpful in high-dimensional data sets where identifying relevant features can enhance model performance and reduce computational complexity.
While some use the terms interchangeably, artificial intelligence and machine learning are not synonymous. Learn what sets these two technologies apart in our AI vs. machine learning article.
Top 7 Regression Algorithms in Machine Learning
Various regression algorithms play a role in machine learning, from simple linear models to more complex ones like polynomial, ridge, or lasso models. Let's examine the seven most commonly used machine learning regression algorithms.

Linear Regression
Linear regression models the relationship between a dependent variable and one or more independent variables. The primary objective is to establish a linear relationship between the input variables and the variable to be predicted.
For instance, suppose you want to make predictions about taxi fares. The further the distance between your house and the destination, the more expensive the fare you can expect to pay. Linear regression helps linearly correlate the taxi fare with the distance (i.e., the longer the distance, the bigger the fare).
Linear regression is one of the most popular regression techniques in machine learning due to its simplicity and high interpretability. Here's the basic formula for this type of regression:
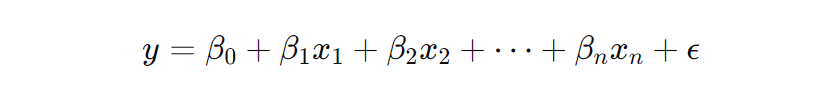
In this formula, y represents the predicted value, and every x is a predictor. The β variables represent coefficients, which are weights assigned to each predictor (β0 is the intercept term, i.e., the bias term). The variable ϵ represents the error term that accounts for the variance in y not explained by the linear relationship with the predictors.
Here are the most common uses of linear regression in machine learning:
- Forecasting sales numbers based on advertising spend, seasonality, and other factors.
- Estimating the relationship between risk factors and health outcomes.
- Analyzing the impact of various factors on employee salaries.
- Predicting stock prices based on historical data and current market indicators.
Here is a Python-based example that demonstrates how linear regression can predict a continuous value (taxi fare) based on a single feature (distance):
pip install numpy pandas scikit-learn matplotlib
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# Example data set: Distance (in miles) and Fare (in dollars)
data = {
'Distance': [1.1, 2.3, 3.1, 4.5, 5.7, 6.8, 7.2, 8.4, 9.5, 10.1],
'Fare': [5.5, 7.0, 8.2, 9.8, 11.5, 13.3, 14.0, 15.9, 17.0, 18.1]
}
# Create a DataFrame
df = pd.DataFrame(data)
# Split the data into features (X) and target (y)
X = df[['Distance']]
y = df['Fare']
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Create a linear regression model
model = LinearRegression()
# Train the model
model.fit(X_train, y_train)
# Make predictions on the test set
y_pred = model.predict(X_test)
# Calculate the mean squared error
mse = mean_squared_error(y_test, y_pred)
print(f"Mean Squared Error: {mse}")
# Plot the results
plt.scatter(X, y, color='blue', label='Actual Data')
plt.plot(X, model.predict(X), color='red', linewidth=2, label='Regression Line')
plt.xlabel('Distance (miles)')
plt.ylabel('Fare (dollars)')
plt.title('Distance vs. Fare')
plt.legend()
plt.show()
# Display the coefficients
print(f"Intercept: {model.intercept_}")
print(f"Coefficient: {model.coef_[0]}")
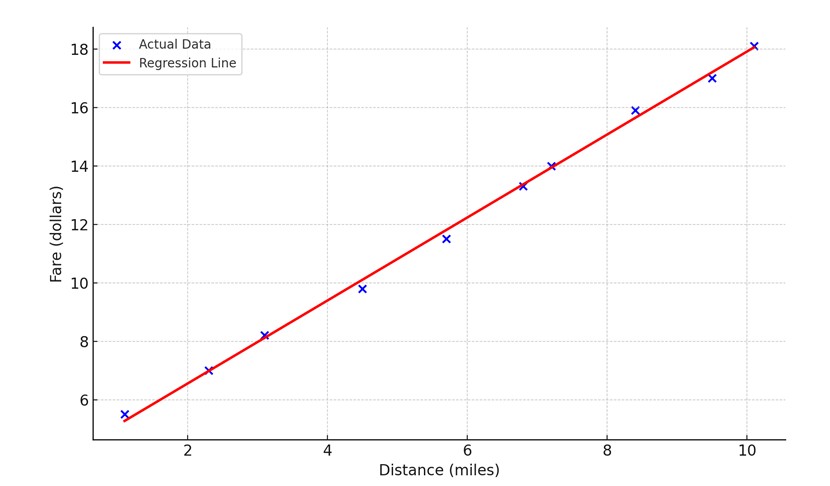
The image below presents a visual output of this algorithm. The blue dots represent the actual data points, and the red line represents the regression line fitted by the model.
Scikit-Learn, which we used in the code above, is an open-source machine learning library for Python. Scikit-Learn is one of the most popular deep learning frameworks often used to speed up ML training.
Ridge Regression
Ridge regression is a type of linear regression that includes a regularization term to prevent overfitting. Overfitting is a common machine learning problem that occurs when a model gives accurate predictions for training data but loses accuracy when analyzing previously unseen data.
Ridge regression adds a penalty to the size of the coefficients, which discourages large β values that can lead to overfitting. This penalty, also known as L2 regularization, stabilizes the model by introducing a small amount of bias to reduce the variance of the model significantly.
Here's the basic formula for this type of regression:
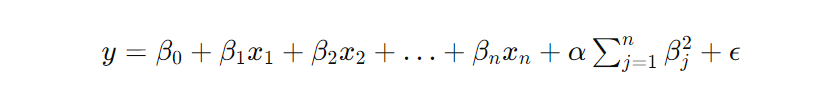
α represents the regularization term, a hyperparameter that controls the strength of the regularization. The regularization term adds a penalty for large coefficient values, which shrinks coefficients and prevents overfitting.
If we set α to 0, the ridge regression turns into a regular linear regression. However, if we set α to a large number, all the weights (i.e., coefficients) get close to zero.
Here are the most common uses of ridge regression in machine learning:
- Predicting real estate prices in scenarios when there are many correlated features.
- Forecasting demand in supply chain management.
- Analyzing genetic data with many correlated variables.
- Predicting customer behavior in marketing analytics.
Here is a simple example of a ridge regression written in Python code:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import Ridge
from sklearn.datasets import make_regression
# Generate a data set
X, y = make_regression(n_samples=100, n_features=1, noise=20, random_state=42)
# Create and train the ridge regression model with a higher alpha value
model = Ridge(alpha=10.0)
model.fit(X, y)
# Predictions
y_pred = model.predict(X)
# Plot the data and the regression line
plt.scatter(X, y, color='blue', label='Data points')
plt.plot(X, y_pred, color='red', label='Ridge regression line')
plt.xlabel('X')
plt.ylabel('y')
plt.title('Ridge Regression with α=10.0')
plt.legend()
plt.show()
This code generates a data set using the make_regression function from Scikit-Learn, creates a ridge regression model with a higher alpha (α) value of 10.0, fits it to the data, and then plots the data points along with the ridge regression line.
The image below presents a visual output of this code. The blue points represent the generated data, while the red line is the ridge regression line fitted to the data.
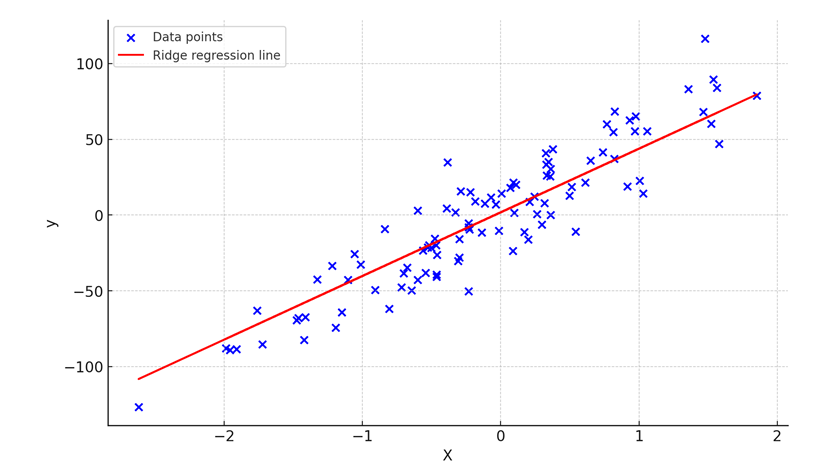
Lasso Regression
Lasso regression (short for Least Absolute Shrinkage and Selection Operator) is a type of linear regression that incorporates a regularization term to improve prediction accuracy.
Similar to ridge regression, lasso regression introduces a penalty on the β values, utilizing L1 regularization instead of L2. The algorithm penalizes the absolute size of the coefficients, which shrinks some of them to zero. That way, lasso regression prevents overfitting and becomes better at selecting relevant features.
Here is the formula for this type of regression:
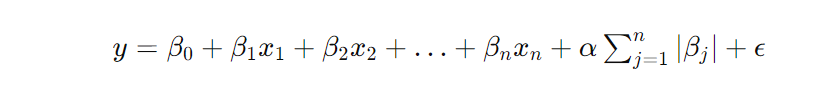
Like in ridge regression, α controls the strength of regularization. This variable penalizes the sum of the absolute values of the coefficients, encouraging some of them to be closer to or precisely zero.
Lasso regression has a wide range of use cases in machine learning, including the following:
- Identifying key predictors in economic or social science models.
- Selecting features in high-dimensional data sets.
- Predicting consumer behavior based on demographic and purchasing data.
- Forecasting demand in retail and inventory management.
Here is a Python-based example of a simple Lasso regression:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import Lasso
from sklearn.datasets import make_regression
# Generate a sample data set
X, y = make_regression(n_samples=100, n_features=1, noise=10, random_state=42)
# Create and train the Lasso regression model
model = Lasso(alpha=0.1)
model.fit(X, y)
# Predictions
y_pred = model.predict(X)
# Plot the data and the regression line
plt.scatter(X, y, color='blue', label='Data points')
plt.plot(X, y_pred, color='red', label='Lasso regression line')
plt.xlabel('X')
plt.ylabel('y')
plt.title('Lasso Regression')
plt.legend()
plt.show()
This code generates a sample data set using make_regression. The function creates a Lasso regression model with a regularization parameter of 0.1 and plots the data points along with the Lasso regression line. This example demonstrates how Lasso regression can be used for prediction while performing feature selection by shrinking less relevant features to zero.
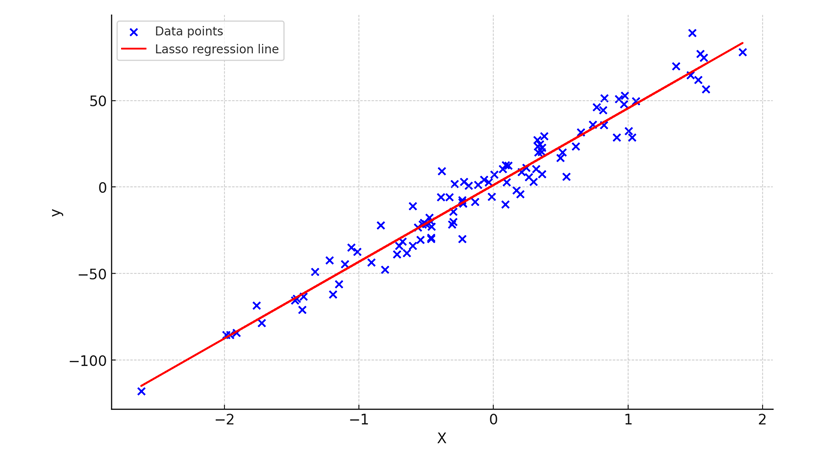
Polynomial Regression
Polynomial regression is a form of regression analysis in which the relationship between the independent variable x and the dependent variable y is modeled as an n-th degree polynomial in x.
Polynomial regression extends linear regression by adding polynomial terms (e.g., x2, x3) to the model, allowing for a more flexible fit to the data. This flexibility enables polynomial regression to capture non-linear relationships between variables, making it useful when the relationship between the variables is not strictly linear.
Here is the main formula for polynomial regression algorithms:
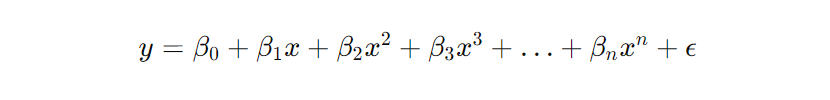
Polynomial regression works by fitting a curve that minimizes the sum of squared errors between the predicted and actual values, allowing for a flexible fit to capture complex data relationships. This regression algorithm can produce a curved line that fits the model on non-linear data.
Polynomial regression algorithms are commonly used in the following use cases:
- Predicting sales trends in retail based on historical data.
- Analyzing the impact of advertising expenditure on revenue.
- Forecasting population growth based on historical census data.
- Predicting temperature variations over time.
Here is a simple example of polynomial regression:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
# Generate some data
np.random.seed(0)
X = np.random.rand(50) * 10
y = np.sin(X) + np.random.normal(size=X.shape)
# Transform the data to include polynomial features
poly = PolynomialFeatures(degree=3)
X_poly = poly.fit_transform(X.reshape(-1, 1))
# Create and train the polynomial regression model
model = LinearRegression()
model.fit(X_poly, y)
# Predictions
y_pred = model.predict(X_poly)
# Sort data points for better plotting
sort_idx = np.argsort(X)
X_sorted = X[sort_idx]
y_pred_sorted = y_pred[sort_idx]
# Plot the data and the polynomial regression curve
plt.scatter(X, y, color='blue', label='Data points')
plt.plot(X_sorted, y_pred_sorted, color='red', label='Polynomial regression curve')
plt.xlabel('X')
plt.ylabel('y')
plt.title('Polynomial Regression (Degree 3)')
plt.legend()
plt.show()
This code generates a data set with random noise, transforms data to include polynomial features up to the 3rd degree using PolynomialFeatures from Scikit-Learn, fits a linear regression model to the transformed data, and plots the data points along with the polynomial regression curve.
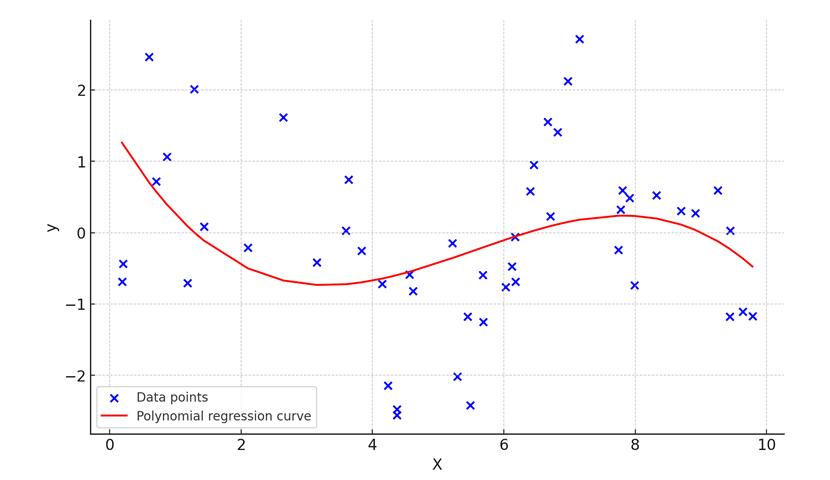
Below is the visual graph generated by the code. The red curve represents the polynomial regression line, while the blue dots are the data points. This curve shows how polynomial regression can fit a more complex, non-linear relationship between variables.
Support Vector Regression (SVR)
Support Vector Regression (SVR) is a regression algorithm that extends Support Vector Machines (SVM) to the regression domain. SVM is a machine learning algorithm commonly used for classification tasks.
Unlike traditional regression algorithms that aim to minimize the error between the predicted and actual values, SVR tries to fit the best line within a predefined margin around the predicted values. This margin is controlled by a hyperparameter ϵ, which specifies the acceptable error tolerance.
Here is the SVR formula:
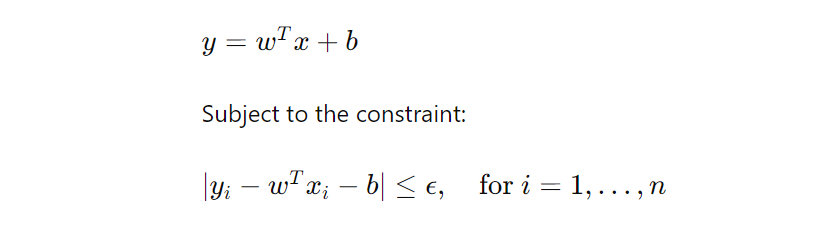
Here, y represents the dependent variable we want to predict, x is the input vector of independent variables, w is the weight vector, b is the bias term, and ϵ is the margin of tolerance. The objective is to find the optimal hyperplane that minimizes the errors within the margin while maximizing the number of instances (i.e., support vectors) within it.
SVR has a wide range of uses in machine learning. Here are the most common applications:
- Predicting stock prices based on historical market data.
- Forecasting energy consumption in smart grid applications.
- Modeling biological responses in pharmaceutical research.
- Analyzing customer churn rates.
Here is a simple Python-based example of an SVR:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.svm import SVR
# Generate sample data
X = np.sort(5 * np.random.rand(100, 1), axis=0)
y = np.sin(X).ravel()
# Add noise to targets
y[::5] += 3 * (0.5 - np.random.rand(20))
# Create and train the SVR model
model = SVR(kernel='rbf', C=100, epsilon=0.1)
model.fit(X, y)
# Predictions
y_pred = model.predict(X)
# Plot the data and the SVR predictions
plt.scatter(X, y, color='blue', label='Data points')
plt.plot(X, y_pred, color='red', label='SVR predictions')
plt.xlabel('X')
plt.ylabel('y')
plt.title('Support Vector Regression (SVR)')
plt.legend()
plt.show()
This code creates an SVR model with a radial basis function (RBF) kernel, fits it to the data, and then plots the data points along with the SVR predictions. SVR is used here to predict a non-linear relationship between X and y while accommodating noisy data.
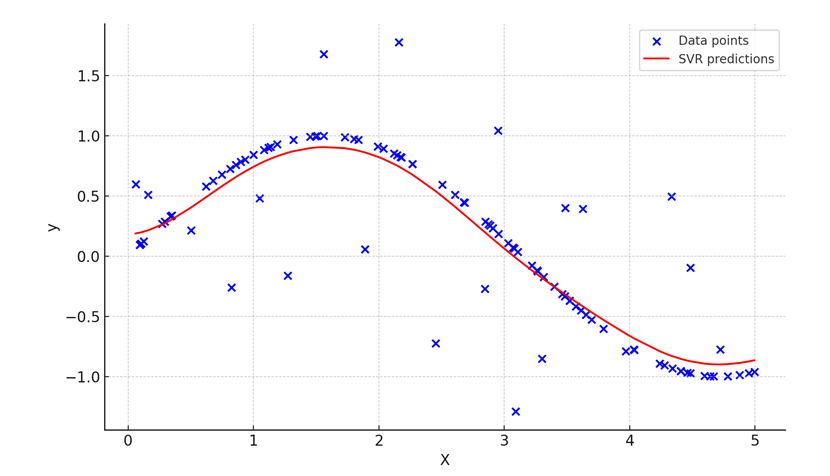
Here is the visual graph generated by the code. The graph shows how SVR models capture the non-linear relationship between variables.
Decision Tree Regression
Decision tree regression is a supervised learning method that recursively partitions data into subsets based on the values of the input features.
Each partition forms a node in a tree-like structure, where the splits are chosen to minimize the variance of the target variable within each partition. A decision tree consists of three parts:
- Root node. Represents the starting point of the tree.
- Interior nodes. Represent decisions based on feature values.
- Leaf nodes. Represent the predicted value or outcome.
Each data point traverses from the root node to a leaf node by satisfying a series of True or False conditions based on the feature values at each interior node. The predicted value for a data point is determined by averaging the target values of all instances that end up in the same leaf node.
Decision tree regression does not have a single go-to formula. Instead, it builds a tree structure where each internal node represents a decision based on a feature value, and each leaf node represents the predicted value. Here's a simplified representation of how a decision tree makes predictions:
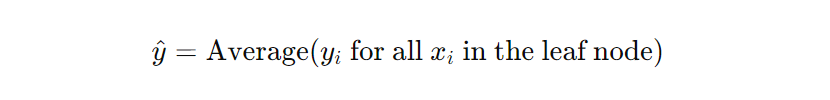
Decision tree regression works by recursively splitting the data into subsets based on the values of the features:
- The features are chosen to minimize the variance of the target variable within each subset.
- The splits are chosen based on metrics like mean squared error or variance reduction.
Splits occur until a stopping criterion is met (e.g., reaching a maximum tree depth or a minimum number of samples per leaf). The resulting tree structure allows for interpretable predictions where each split and leaf node provides insights into the relationship between the input features and the target variable.
Below are a few common uses of decision tree regression in machine learning:
- Forecasting demand for products based on sales data and marketing campaigns.
- Analyzing customer behavior and preferences in retail and e-commerce.
- Modeling temperature variations and weather patterns.
- Predicting the outcome of sporting events based on historical data.
Here is a simple example of a decision tree regression written in Python:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.tree import DecisionTreeRegressor
# Generate sample data
np.random.seed(0)
X = np.sort(5 * np.random.rand(80, 1), axis=0)
y = np.sin(X).ravel() + np.random.normal(0, 0.1, X.shape[0])
# Create and train the Decision Tree Regression model
model = DecisionTreeRegressor(max_depth=4)
model.fit(X, y)
# Predictions
X_test = np.arange(0.0, 5.0, 0.01)[:, np.newaxis]
y_pred = model.predict(X_test)
# Plot the data and the decision tree regression predictions
plt.scatter(X, y, color='blue', label='Data points')
plt.plot(X_test, y_pred, color='red', label='Decision Tree Regression')
plt.xlabel('X')
plt.ylabel('y')
plt.title('Decision Tree Regression')
plt.legend()
plt.show()
This code generates a sample data set, creates a decision tree regression model with a maximum depth of 4, and plots the data points along with the decision tree regression predictions. The code predicts a non-linear relationship between X and y while capturing underlying data patterns.
Below is the visual graph generated by the code. The step-like nature of the red line shows how decision trees partition the data into regions.
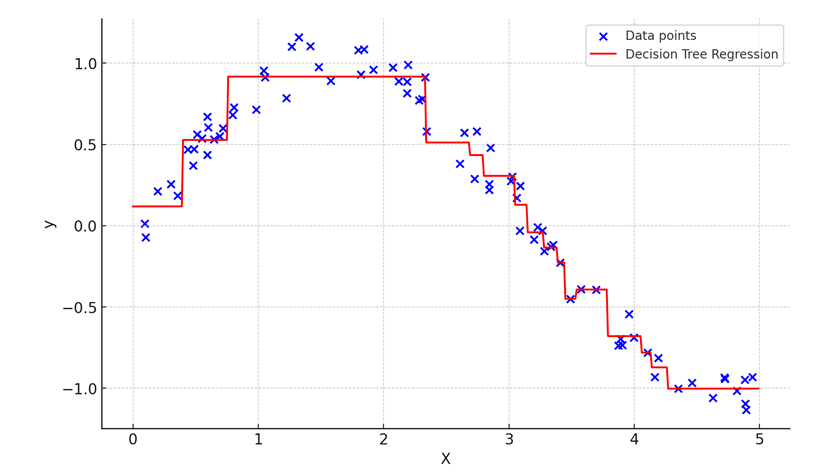
Random Forest Regression
Random forest regression combines multiple decision trees to improve predictive performance. This ensemble approach reduces variance and improves generalization compared to individual decision trees.
A random forest builds a collection of decision trees during training and outputs the average prediction of individual trees. Each tree is trained on a random subset of features, making the model less prone to overfitting and more robust to noise in the data.
Like decision trees, random forest regression does not have a go-to formula. Instead, these regression algorithms aggregate the predictions of multiple decision trees. The final prediction y is typically the average of predictions from all the individual trees in the forest:
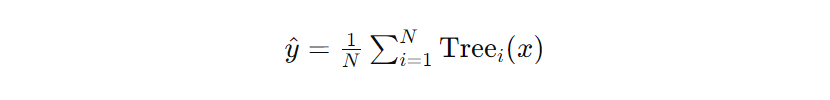
N is the number of trees in the forest, and Treei(x) represents the prediction of the i-th decision tree for input vector x.
Here are a few usual ML use cases for random forest regression:
- Forecasting stock market prices using historical financial data.
- Estimating customer lifetime value (CLV) based on behavioral and demographic data.
- Analyzing healthcare data to predict treatment outcomes.
- Predicting crop yields based on environmental and agricultural factors.
Below is a simple example of a random forest written in Python:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestRegressor
# Generate sample data
np.random.seed(0)
X = np.sort(5 * np.random.rand(100, 1), axis=0)
y = np.sin(X).ravel() + np.random.normal(0, 0.1, X.shape[0])
# Create and train the Random Forest Regression model
model = RandomForestRegressor(n_estimators=100, random_state=42)
model.fit(X, y)
# Predictions
X_test = np.arange(0.0, 5.0, 0.01)[:, np.newaxis]
y_pred = model.predict(X_test)
# Plot the data and the Random Forest Regression predictions
plt.scatter(X, y, color='blue', label='Data points')
plt.plot(X_test, y_pred, color='red', label='Random Forest Regression')
plt.xlabel('X')
plt.ylabel('y')
plt.title('Random Forest Regression')
plt.legend()
plt.show()
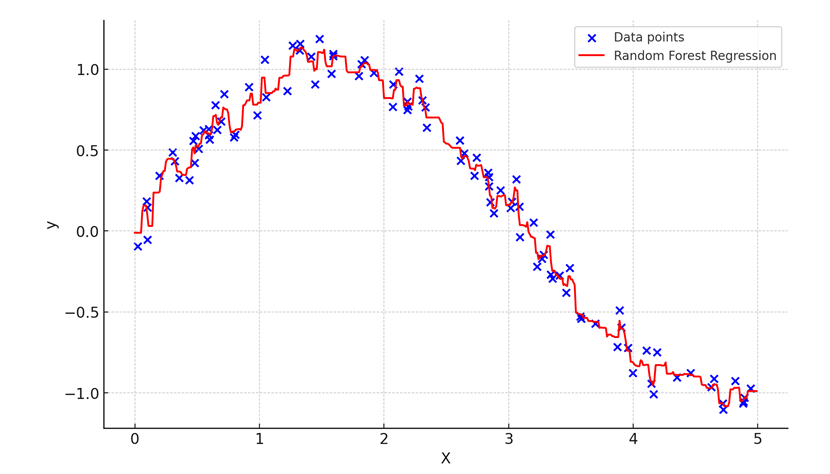
In this example, random forest regression predicts a non-linear relationship between X and y while leveraging the aggregation of multiple decision trees to improve accuracy.
Below is the visual graph generated by the code. The model captures the non-linear relationship between the variables, providing a smoother fit compared to individual decision trees.
When to Use Regression Algorithms
Regression is an invaluable tool in machine learning that is used in a variety of scenarios. Use regression algorithms when the goal of your ML model is to:
- Predict continuous target variables, such as prices, temperature, sales figures, or any other numeric quantity.
- Get a quantitative way to analyze how changes in one or more predictors relate to changes in the target variable.
- Rank the importance of input variables based on their coefficients or other feature selection methods.
- Understand the underlying factors driving predictions in fields that require high levels of interpretability (e.g., economics or business analytics).
- Create a baseline model against which you can compare more complex models.
- Check assumptions about the relationships between variables (e.g., linearity or independence of errors).
Regression is also an excellent starting point for exploring your data. Regression algorithms help identify key variables and understand the strength of relationships between variables. These algorithms also help identify potential outliers or data points that do not conform to expected patterns.
A Core Machine Learning Methodology
Regression is a core methodology of both machine learning and artificial intelligence (AI) in general. Now that you know how regression works and what types of algorithms are out there, you have a firm understanding of how ML models can make accurate data-driven predictions.