DeepSeek-R1 is a powerful open-source AI model designed and optimized for complex reasoning, coding, mathematics, and problem-solving. It is built on a Mixture of Experts (MoE) architecture and dynamically allocates resources to different sub-models called experts. This approach maintains high performance and enhances its efficiency.
DeepSeek-R1 is ideal for researchers and enterprises that are looking to strike a balance between resource optimization and scalability.
This guide shows how to install DeepSeek-R1 locally using Ollama and provides optimization strategies. We will also show how to set up a web interface using Open WebUI.

Prerequisites
- Linux, macOS, or Windows (WSL2 recommended).
- At least 16GB RAM for smaller models (1.5B-7B). For larger models, at least 32GB RAM.
- At least 50GB of free space for smaller models and up to 1TB for larger versions.
- (Optional) NVIDIA GPU with CUDA support for accelerated results.
What Is DeepSeek-R1?
DeepSeek-R1 is a language model that applies advanced reasoning. Unlike traditional language models, its MoE-based architecture activates only the required "expert" per task. This approach reduces latency and unnecessary load while remaining accurate.
The LLM offers both distilled and undistilled models. Distillation is a process that produces smaller models that mimic the behavior of large models. Their small size also reduces hardware requirements while key behaviors are still present.
Different model sizes offer flexibility, and it allows users to choose the ideal option for their workload and environment:
- Larger models perform better at complex tasks but require significant computational power (CPU or GPU) and memory (RAM or VRAM).
- Smaller models are lightweight and are suitable for basic tasks on consumer hardware.
DeepSeek-R1 currently supports multiple model sizes, ranging from 1.5B to 671B (billion) parameters.
Why Use DeepSeek-R1?
The main reasons to use DeepSeek-R1 include:
- Efficiency. MoE architecture minimizes resource usage. It is ideal for high-throughput tasks.
- Open-source. DeepSeek-R1 is freely available for customization and commercial use.
- Versatility. The model excels in coding, math, and problem-solving tasks,
- Scalability. It is available for small-scale hardware and enterprise-grade servers.
DeepSeek-R1's architecture is its main feature and what sets it apart from traditional transformer models, such as GPT-4, LLLaMA, and similar.
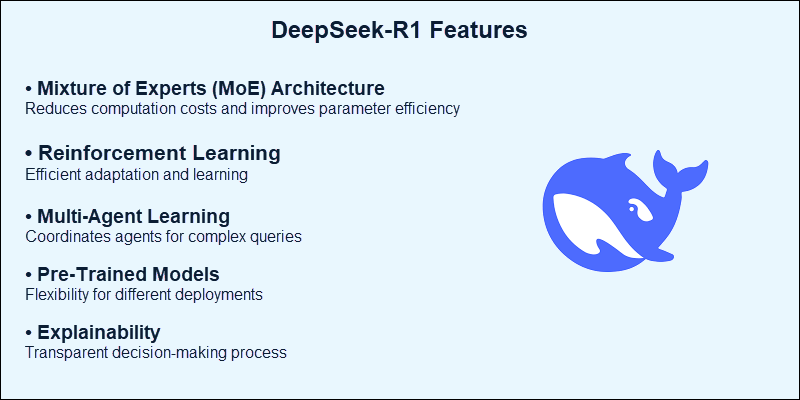
Traditional LLMs use monolithic transformers, which means all parameters are active for every query. Even simple tasks become inefficient because they require high computational power and memory consumption.
The MoE architecture challenges this approach by using:
- Experts. Sub-networks trained for different specialized tasks.
- Dynamic selection. Instead of activating the whole model for each query, it selects the most appropriate expert for the task.
- Parameter reduction. By applying parameter reduction, DeepSeek-R1 leads to faster processing and reduced resource usage.
The architecture aims to improve query performance and resource consumption while remaining accurate.
How to Install DeepSeek-R1 Locally
The steps below show how to install DeepSeek-R1 on your local machine. The process includes Ollama setup, pulling the model, and running it locally. There are also performance optimization tips that can help provide smoother operations.
The required hardware depends on the model you plan to use. The table below shows the disk space, VRAM (GPU), and RAM (CPU) requirements for each model:
| Model | Model Size | Size on Disk | VRAM (GPU) | RAM (CPU) | Use Case |
|---|---|---|---|---|---|
| DeepSeek-R1-Distill-Qwen-1.5B | 1.5b | 1.1GB | ~3.5GB | ~7GB | Personal projects and lightweight tasks. |
| DeepSeek-R1-Distill-Qwen-7B | 7b | 4.7GB | ~16GB | ~32GB | Small-scale AI development. |
| DeepSeek-R1-Distill-Llama-8B | 8b | 4.9GB | ~18GB | ~36GB | Moderate coding and research. |
| DeepSeek-R1-Distill-Qwen-14B | 14b | 9GB | ~32GB | ~64GB | Advanced problem-solving. |
| DeepSeek-R1-Distill-Qwen-32B | 32b | 20GB | ~74 GB | ~148GB | Enterprise-grade AI workloads. |
| DeepSeek-R1-Distill-Llama-70B | 70b | 43GB | ~161GB | ~322GB | Large-scale AI applications. |
| DeepSeek-R1 | 671b | 404GB | ~1342GB | ~2684GB | Multi-GPU clusters and HPC AI workloads. |
The 671b is the only undistilled DeepSeek-R1 model. Other models are distilled for better performance on simpler hardware.
For models above 7b, consider using the following:
- Dedicated GPUs. NVIDIA models with at least 24-40GB VRAM will ensure smoother performance.
- Storage. Use NVMe SSDs to prevent slow loading times.
- CPU. Choose CPUs with a higher core count (such as Intel Xeon) to handle large inference loads.
Note: Although the model can run without a dedicated GPU, it is not recommended due to significant performance reduction.
Step 1: Install Ollama
Ollama is a lightweight framework that simplifies installing and using different LLMs locally. To install it on Linux, open the terminal and run:
curl -fsSL https://ollama.com/install.sh | sh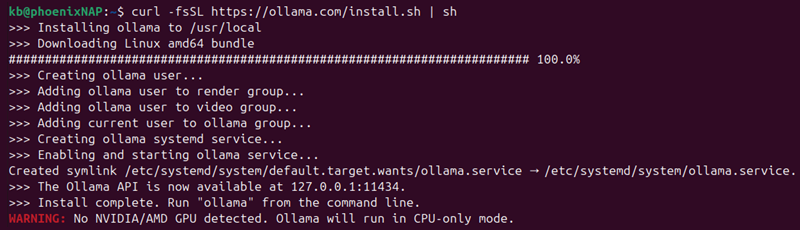
The command downloads and immediately runs the installation script.
Note: The curl command is not available by default on Ubuntu. Install it with: sudo apt install curl.
Alternatively, download the Ollama installer for macOS and extract the files to a desired location. Windows users can download and run the Ollama .exe file.
Step 2: Pull the DeepSeek-R1 Model
After installing Ollama, download the DeepSeek-R1 model locally. The syntax is:
ollama pull deepseek-r1:[size]
Replace [size] with the actual parameter size and secure enough disk space.
Note: A GPU setup is highly recommended to speed up processing. Learn more about GPU computing and why it's the future of machine learning and AI.
Step 3: Run the Model
Start the model locally with:
ollama run deepseek-r1:[size]
The prompt changes to a chat ready for interactions.
Step 4: Optimize Performance
To maximize performance, consider the following optimization tips:
- Detailed logging. Add the
--verboseargument to show response and evaluation timings. For example:
ollama run --verbose deepseek-r1:[size]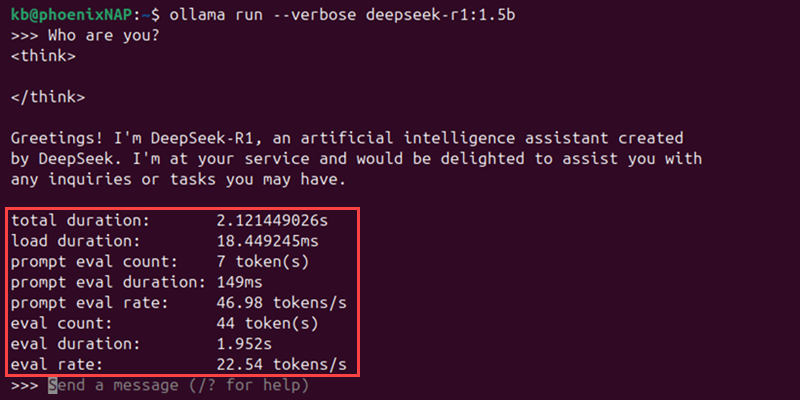
- GPU acceleration. If using an NVIDIA GPU, add the
--gpu allflag:
ollama run --gpu all deepseek-r1:[size]This requires NVIDIA drivers to work.
Note: To install NVIDIA drivers, follow one of our guides:
- CPU acceleration. Adjust the thread count with the following environment variable:
export OLLAMA_NUM_THREADS=[threads]Replace [threads] with the desired number of CPU threads.
- Reduce memory footprint. Use memory optimization flags:
export OLLAMA_MEMORY_OPTIMIZATION=1Enable the flag if using multiple models.
How to Set Up Web Interface for DeepSeek-R1
Integrating a web interface with DeepSeek-R1 provides an intuitive and accessible way to interact with the model. The interface enables sending messages, viewing responses, and customizing interactions through the web browser.
This section shows how to install and launch Open WebUI with DeepSeek-R1.
Step 1: Install Prerequisites
There are several prerequisites depending on the preferred installation method. The following methods are available:
- Docker. Recommended for most users, and it is officially supported.
- Python 3.11. Best for low-resource environments and manual setups.
- Kubernetes. Suitable for deployments that require orchestration and scaling.
This guide will use Docker to demonstrate the setup.
Note: To install Docker on a Linux system, follow one of our guides:
Step 2: Run Open WebUI Image
Run the Open WebUI image. The docker run command differs depending on whether Ollama is already installed or not:
- If Ollama is installed on the machine, use:
sudo docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main- If Ollama is not installed, pull and run Ollama alongside Open WebUI:
sudo docker run -d -p 3000:8080 -v ollama:/root/.ollama -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:ollamaAdd the --gpus=all flag to run in GPU mode. Without the flag, the commands run the container in CPU mode.
To confirm whether the container started, use the following Docker command:
sudo docker ps
The command shows the running container information.
Step 3: Access Open WebUI
To access Open WebUI, do the following:
1. Open a web browser and access localhost on port 3000:
localhost:3000
The Open WebUI landing page appears.
2. Click Get Started to begin the registration process.
3. Fill out the details to create an admin account (name, email, password).
These details remain on the local server. Click Create Admin Account when ready.
4. The page shows a chat interface, indicating the account was created successfully.
The interface also includes voice or file input and text-to-speech output.
Step 4: Install DeepSeek-R1 Model
To install a DeepSeek-R1 model:
1. Open the Select a Model interface in the navbar.
2. Search for the appropriate DeepSeek-R1 model size and click Pull to download the model.
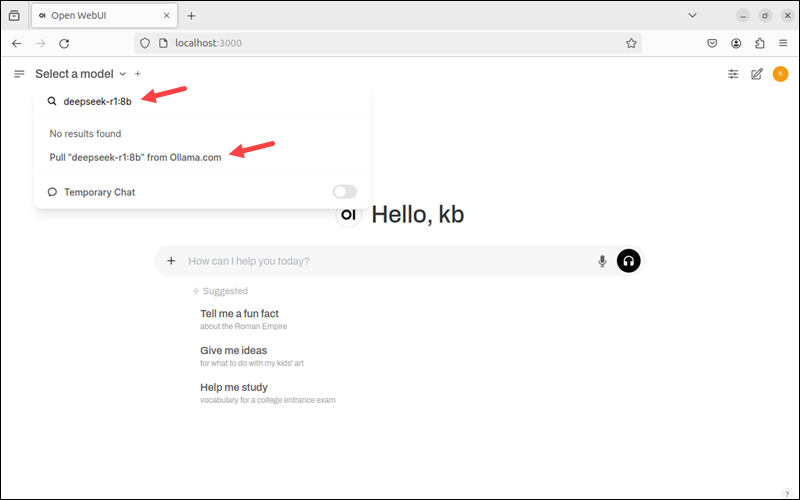
3. Wait for the download to complete. If it gets interrupted, restart the process, and it will continue where it left off.
4. The model appears on the list. Click the model name to select it and start using it.
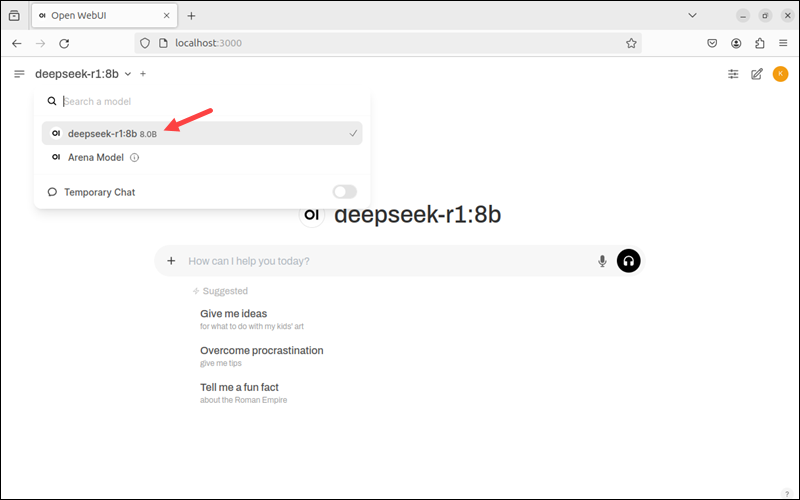
Install additional models and switch between them to test the differences.
Conclusion
This guide showed how to set up and test DeepSeek-R1 locally. The powerful AI model is easy to set up using Ollama. We also showed how to set up an interactive UI using Open WebUI.
Next, see our picks for the best GPUs for deep learning.