
Git is the most popular version control system (VCS) in the world. It records changes made to your code in a repository and allows you to roll back to a previous state in case of a mistake or a bug.
In this article, you will learn what Git is, its most important features, and what it is used for.

What Is Git?
Git is a free, open-source VCS used for tracking source code changes. It allows multiple developers to work together on non-linear development. Git is free, open-source, speedy, and scalable, making it the world's most popular VCS.
There are two types of version control systems:
- Centralized. All team members connect to a central server to get the latest code copy and share their contribution with others.
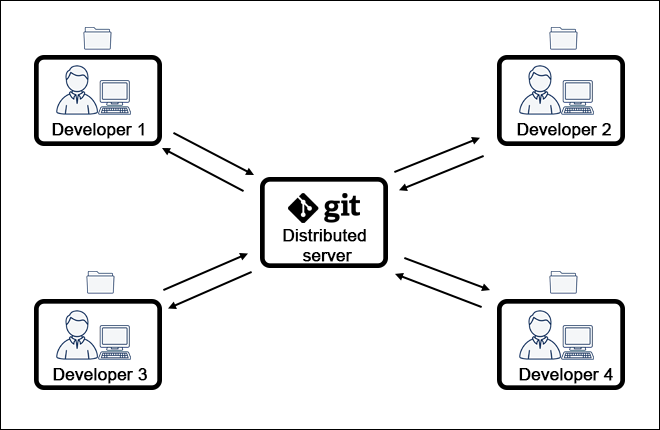
- Distributed. In a distributed VCS, every team member has a copy of the project and its history on their machine, allowing them to save snapshots of the project locally.
The issue with a centralized VCS is the single point of failure. If the server goes down, team members can't collaborate or save snapshots of their project.
Note: Learn more about the Git repository and how to create and manage a Git repo.
Git is a distributed VCS that resolves the single point of failure issue because it allows members to synchronize their work even if the central server is offline.
The following diagram shows how multiple people collaborate in a single project using Git:
What Is Git Used For?
Git's primary use is source code management in software development, however it can track changes in any file set. The project history stored in Git shows who has made changes, what was done, when, and why.
Being a distributed VCS, Git enables every team member to have a copy of the project and its history on their machine, allowing them to save project snapshots locally.
It also allows developers to work with several remote repositories and collaborate with other people simultaneously within the same project. Consequently, users can set up multiple workflow types that aren't possible in a centralized system, e.g., a hierarchical model.
Note: Our Git commands cheat sheet will help you get started using Git.
How Does Git Work?
How it handles data is what differentiates Git from other version control systems.
While other VCSs store information as a list of file-based changes, Git stores its data in a series of snapshots of a miniature filesystem. Every time you commit a change or save your project state, Git takes a snapshot of all your files at that moment and stores a reference to that snapshot.
If there were no file changes, for the sake of efficiency, Git doesn't store the file again. Instead, it only creates a link to the previous file version, which is already stored.
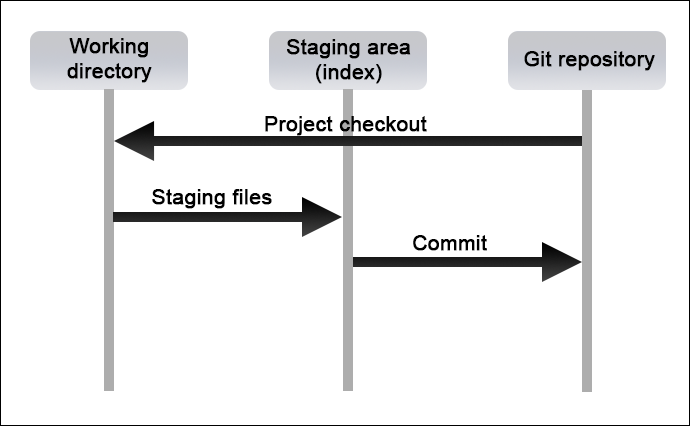
A Git project resides in three sections:
- The Working Directory. The single checkout of one version of the project.
- The Staging Area. An index that stores information about what the next commit will contain.
- The Git Repository. The place where Git stores the metadata and object database for a project.
The following diagram represents the basic Git project workflow:
Note: Read our step-by-step tutorials on unstaging files in Git and reverting the last commit.
Before storing data in Git, everything is checksummed and then referred to using that checksum. This prevents any file changes or data corruption from going under the radar. The mechanism used for checksumming is the SHA-1 hash.
Git stores files in three main states:
- Modified. A file has been changed but not yet committed to the database.
- Staged. A modified file in its current version is marked to go into the next commit snapshot.
- Committed. The data is safely stored in your local database.
The VCS also prevents data loss because almost all actions in Git only add data to the repository, making them basically undoable.
Note: Learn more in-depth about how Git works and about Git functions such as staging, making commits, reverting, forking, branching, etc.
Git Main Features
Several features put Git ahead of other version control systems.
1. Performance
Performance is Git's trump card when comparing it to other version control systems. Committing changes, branching, merging, and comparing previous versions are all highly performant operations in Git.
Advanced algorithms and a distributed architecture are the basis of Git's high performance. The algorithms utilize deep knowledge about common attributes of real source code file trees, their modifications over time, and their access patterns.
Git doesn't rely on the filenames when determining the storage type and file tree version history because source code files are frequently renamed, split, or rearranged. Instead, Git focuses on the file content.
The Git repository object format uses delta encoding (storing content differences) and compression, explicitly storing directory contents and version metadata objects.
2. Compatibility
Git is compatible with all the available operating systems, as well as other VCS remote repositories, which it can access directly.
Its ability to access other VCS repositories means that users can easily switch to using Git without moving their files from those repositories to the Git repository.
Note: Need to install Git on your machine? Take a look at one of our installation guides:
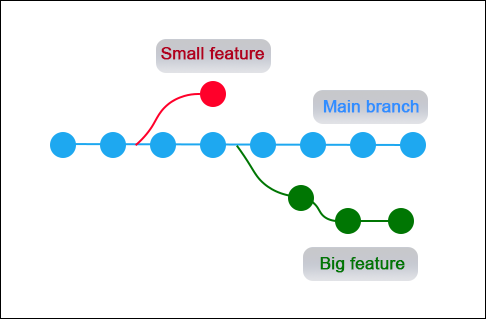
3. Branching
Branches in Git are development lines parallel with the main project files. By using branches, developers can make changes to the project without affecting the original version.
Note: Check out our article to learn how to create a new branch in Git.
The original version stays on the master branch and can later merge with new features after testing them on other branches.
Branching and merging are simple processes in Git, unlike in other VCSs where they can be complex and slow.
4. Security
Security and code integrity are a priority when committing changes in Git. This VCS stores records of all the commits done by each teammate on the developer's local copy.
When someone performs a push operation, Git creates a log file and sends it to the central repository. Thus, if an issue occurs, it can be easily tracked and resolved.
Another great security feature is the SHA1 cryptographic algorithm, used to secure and identify all the objects in the repository. The algorithm protects the code and the change history from accidental or intentional changes while ensuring a fully traceable history.
5. Speed
Fetching data from a local repository is approximately 100 times faster than fetching from a remote repository. Git stores all project data in the local repository, resulting in incredible speeds when fetching data.
Git is also highly scalable and faster than other version control systems, allowing it to handle large projects efficiently.
6. Flexibility
Another great feature of Git is its overall flexibility.
Users can easily track changes as developers can leave a commit message after making modifications. A commit message enables another developer to seamlessly continue working where the previous one left off.
Git also includes features like Backup and Restore, which help users maintain the source code backup. Additionally, it requires only one command to deploy the source code on the server.
7. Widespread Use
Since it possesses nearly everything developers need for the most effective work results, Git has become the most widespread version control system. Due to its prevalence on the market, numerous tools and services are optimized specifically for Git.
Although many tutorials, dedicated websites, and books cover Git, it is often criticized for being difficult to learn. Still, Git has become a mandatory skill for most developers, representing the basis for using other VCSs.
Another reason for Git being so widespread is that it is open-source, meaning it is entirely free to use.
Why Is Git Important?
A version control system facilitates development when there are many points on the timeline and allows users to manage their development paths.
Without a VCS, developers would have to constantly store project copies in various folders, which is slow and unscalable, especially if a team is working on the same project. No VCS would also mean having to exchange and merge the file changes manually.
Conclusion
You now know the basic features of Git, how it works, and why it is important.
If you are working on a collaborative project with several development paths, having a VCS is mandatory, and Git is the best one on the market.



