
The grep command in Linux is a tool for searching through text based on a pattern. A common use is to count how many times a string appears in one or more files.
The command also allows searching through compressed files without needing to decompress them.
This guide shows how to count using grep to scan files for a string.

Prerequisites
- Access to the command line/terminal.
- An example file to search.
How to Use grep count If String or Word Matches
There are several ways to use grep to count matches. The following flags control how matches are counted:
-c,--count. Counts the number of lines that have a match.-w,--word-regexp. Matches whole words (excludes substrings).-i,--ignore-case. Ignores case.-o,--only-matching. Prints each match on a new line (counts total word occurrences with the wc command).
The following sections demonstrate how to combine these options in various ways.
Count String or Word Matches Examples
The examples below use the following file contents (example.txt):
apple apple apple
banana Apple
apple pie
grapefruit
pineappleLine-Based Counts
To count all lines where the word "apple" appears, use the grep --count or -c flag:
grep -c "apple" example.txt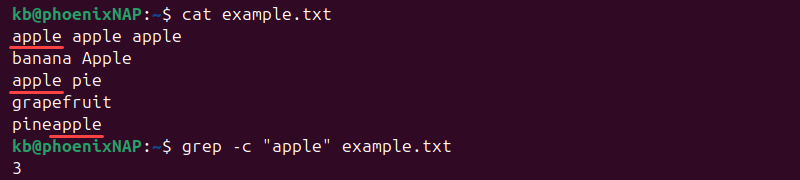
The count is case-sensitive and includes substrings.
To count all lines where the word "apple" appears as a whole word, use:
grep -cw "apple" example.txt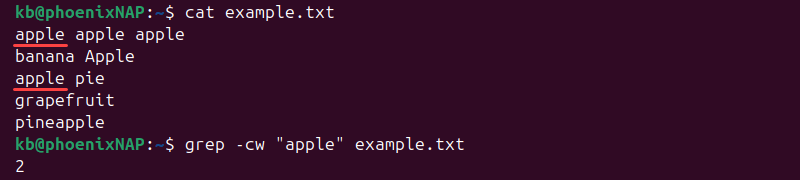
The count excludes substrings, and it is case-sensitive.
For a case-insensitive count, use:
grep -ci "apple" example.txt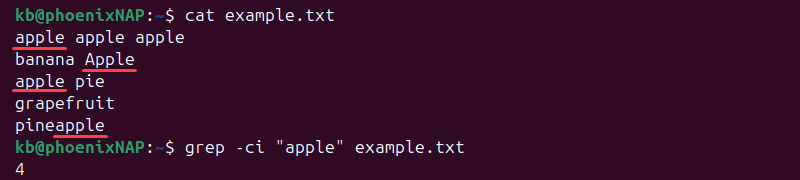
The count includes lines where there are different cases and substrings.
For a case-insensitive, whole-word count, use:
grep -cwi "apple" example.txt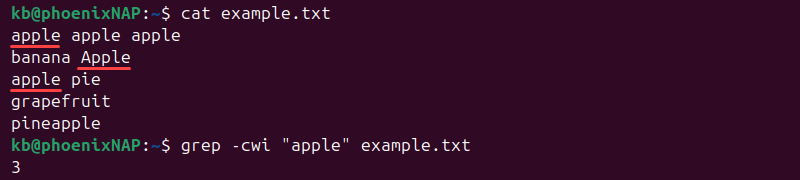
The count excludes substrings and is case-insensitive.
Individual Matches
To count all occurrences of the word "apple", use the -o flag to split the file into lines, and pipe the wc command to count the lines:
grep -o "apple" example.txt | wc -l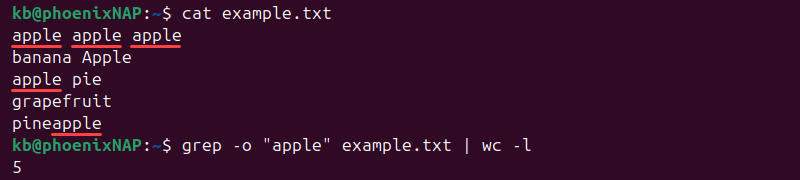
The command counts all case-matching occurrences of the word, including substrings.
Note: Piping grep -c "[string]" would also work.
Count all whole-word occurrences with:
grep -ow "apple" example.txt | wc -l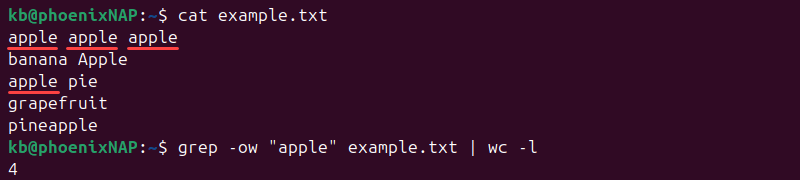
The command ignores substrings.
To count all case-insensitive occurrences, use:
grep -oi "apple" example.txt | wc -l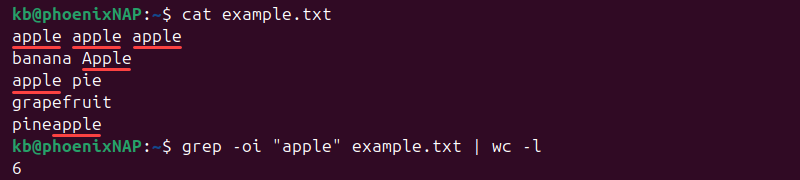
The command includes substrings and case variations.
Use the following to count all whole-word and case-insensitive matches:
grep -owi "apple" example.txt | wc -l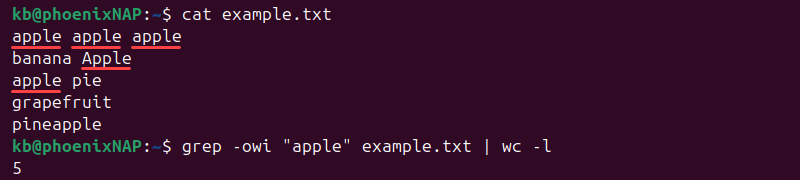
The command counts all instances of the word, regardless of its case. It excludes substrings.
Note: Use grep with regex for advanced searches and file name matching.
How to Use grep count with Multiple Files
To count matches in multiple files at once, list the files or use wildcard matching. For example, to count lines where the word "error" appears in some log files, list the files individually:
grep -c "error" file1.log file2.log file3.log
Note: All flags and combinations mentioned in the previous section also work when searching through multiple files.
Alternatively, use the wildcard method:
grep -c "error" file*.log
The wildcard method is helpful when files have a similar name.
Note: For additional use cases, see how to grep multiple strings.
How to Use grep count with Compressed Files
The zgrep command allows searching through compressed .gz files without having to decompress them first. Apart from working with compressed files, zgrep uses the same flags as grep.
For example, to search a compressed file for the word "apple", use:
zgrep -c "apple" example.txt.gz
The method also allows the use of wildcards to search through multiple compressed files.
Conclusion
This guide explained how to use grep count to count lines where a word appears in a file. We also showed how to count individual instances of a word in one or more files and how to use grep to search compressed files.
For similar guides, see how to use the Linux egrep command.



