
Cloud outages happen when online services suddenly stop working or become very slow. This can affect websites, apps, cloud storage, and business systems that people use every day. Outages may last a few minutes or several hours, depending on the cause.
In this article, we explain why cloud outages happen, what problems they can create, and how businesses can reduce the risk of downtime.

What Is a Cloud Outage?
A cloud outage is a temporary loss of access to cloud-based services, systems, or resources. During an outage, users may be unable to open websites, use apps, access stored data, connect to virtual servers, or complete online tasks normally. In some cases, the service stops working completely. In others, it may still run but become very slow, unstable, or only partly available.
An Uptime Institute 2025 outage analysis found that more than two-thirds of significant outages cost over $100,000, showing how expensive downtime can be for modern businesses.
Cloud Outage Consequences
When cloud services go down, the impact is often greater than many people expect. Businesses depend on the cloud for websites, apps, storage, communication, and daily operations. Even a short outage creates problems for both companies and customers.

Lost Revenue
Many businesses earn money through online sales, subscriptions, or digital services. If customers cannot access a website, app, or payment system during an outage, sales may stop completely. The longer the outage lasts, the more revenue a company can lose.
Lower Productivity
Employees often rely on cloud tools for email, file sharing, project management, and remote work. When these systems are unavailable, teams are unable to complete tasks or communicate efficiently. This slows projects and wastes valuable work time.
Customer Frustration
Users expect online services to always be available. If a platform suddenly stops working, customers become frustrated and lose confidence in the service. Repeated outages can push users to choose a competitor instead.
Reputation Damage
A serious outage harms a company’s public image. Customers may view downtime as a sign of poor reliability or weak planning. Negative reviews, complaints, and social media reactions can continue even after the service is restored.
Data Access Problems
Cloud outages may prevent users from reaching important files, databases, or applications. This delays decisions, interrupts customer support, and creates operational confusion. In critical industries, limited data access can become a major risk.
Extra Recovery Costs
After an outage, businesses often spend time and money fixing issues, restoring systems, and helping affected customers. They may need overtime staff, technical support, refunds, or emergency resources. These unexpected costs can add up quickly.
Cutting cloud costs with phoenixNAP’s Bare Metal Cloud has never been easier. Use dedicated servers with predictable pricing and no virtualization overhead to gain high performance and full resource access while avoiding the rising costs of shared cloud instances.
What Causes Cloud Outages?
Below are some of the most common causes of cloud outages:
- Hardware failures. Servers, storage drives, routers, and other equipment can break or stop working. Even with backups in place, hardware problems can still cause downtime.
- Network problems. Cloud services depend on stable network connections. Routing errors, damaged cables, congestion, or connection failures make services slow or unreachable.
- Power outages. Data centers need constant electricity to run. If backup generators or power systems fail during an outage, cloud services may go offline.
- Software bugs. Updates, patches, or coding errors can create unexpected problems. A faulty software change can crash systems or interrupt services.
- Human error. Mistakes during maintenance, setup changes, or security updates can accidentally cause outages. Simple errors sometimes affect many users.
- Cyberattacks. Attacks such as DDoS floods, ransomware, or unauthorized access attempts can overload or disrupt cloud systems.
- Capacity overload. A sudden spike in traffic or demand strains servers and networks. If resources cannot scale fast enough, performance drops or services may fail.
- Natural disasters. Floods, fires, earthquakes, and severe storms can damage data centers or network infrastructure, leading to service interruptions.
Even one failure can lead to an outage if proper safeguards are not in place because cloud systems depend on many connected parts.

Cloud Outage Examples
Recent cloud outages show that even the largest technology providers can face unexpected downtime. These real-world examples highlight how outages happen, how long they can last, and the impact they can have on businesses and users worldwide.
1. Google Cloud (June 2025)
On June 12, 2025, Google Cloud experienced a major multi-service outage that affected APIs, authentication, and several core products. Many businesses using Google services and third-party apps saw errors or downtime. Services were largely restored in about 7 hours. The outage was linked to issues within core identity and service management systems that disrupted multiple dependent products.
2. Cloudflare (November 2025)
On November 18, 2025, Cloudflare suffered a global outage that disrupted access to many websites and apps relying on its network. Platforms such as ChatGPT, X, and Spotify were affected. Core traffic was mostly restored within a few hours. The cause was reported as an internal network control plane failure that affected routing and traffic management.
3. Amazon Web Services (October 2025)
AWS experienced a large outage centered in US-East-1 on October 20, 2025. Load balancer and networking issues caused failures across many dependent services and websites. Some reports described impacts lasting up to 15 hours.
4. Microsoft Azure (October 2025)
On October 29, 2025, Azure had a major outage tied to a configuration and DNS issue affecting Azure Front Door. Microsoft 365, Xbox, and many customer services were disrupted. Recovery took several hours, with gradual restoration overnight. A faulty network configuration update triggered DNS resolution problems and traffic routing failures.
5. Cloudflare (June 2025)
Cloudflare also had a significant outage on June 12, 2025, affecting multiple internal and customer-facing services. Because Cloudflare supports security and traffic routing for many companies, the outage had a wide reach. Restoration began the same day. The company said the issue was caused by failures in critical internal services supporting authentication and management systems.
6. Microsoft Azure (January 2025)
Azure experienced a long outage on January 8, 2025, caused by a networking configuration issue in East US 2. Customers reported connectivity failures, timeouts, and deployment problems. Some impacts lasted roughly two days in affected areas.
7. Slack (February 2025)
Slack suffered a widespread outage on February 26, 2025. Users had trouble sending messages, loading channels, and signing in. Since many companies depend on Slack for daily communication, productivity was disrupted. The outage was linked to backend infrastructure and database connectivity issues.
8. Zoom (April 2025)
Zoom experienced a notable outage in April 2025 that affected meetings and sign-ins. Businesses, schools, and remote workers were temporarily unable to connect. Services returned after several hours. Reports pointed to authentication platform problems and service routing issues.
9. Google Workspace (September 2025)
Google Workspace users reported issues on September 18, 2025, affecting email and productivity tools. This created delays for businesses that rely on Gmail, Docs, and collaboration apps. Recovery happened the same day. The outage was likely tied to service authentication and backend platform disruptions affecting multiple apps.
10. Microsoft Azure (September 2025)
Azure had another outage on September 10, 2025, according to 2025 incident summaries. Multiple services were affected, showing how even large cloud providers can experience repeated disruptions. Recovery was completed after several hours. Early reports pointed to regional network and platform management issues.
How to Manage Cloud Outages
Cloud outages cannot always be prevented but they can be managed with the right plan and fast action. Businesses that prepare in advance reduce downtime, protect customers, and recover more quickly.
The steps below help organizations respond effectively to cloud outages:
- Detect the problem quickly. Use monitoring tools and alerts to spot outages as soon as they begin. Early detection helps teams respond before the issue becomes worse.
- Confirm the scope. Find out what is affected, such as websites, apps, regions, or internal systems. Knowing the scope helps prioritize the response.
- Activate the response plan. Follow a clear incident response process with assigned roles and responsibilities. This keeps teams organized during a stressful event.
- Communicate internally. Inform IT teams, leadership, and employees about the outage and current status. Clear internal updates reduce confusion and speed decisions.
- Update customers promptly. Let customers know there is a problem, what services are affected, and when the next update will come. Honest communication helps maintain trust.
- Use backup systems. Switch to failover servers, secondary regions, or backup connections if available. Backup systems can keep critical services running.
- Fix the root cause. Identify what caused the outage, whether it was hardware, software, networking, or human error. Solve the core issue before fully restoring services.
- Restore services carefully. Bring systems back online in stages and test performance as you go. This helps prevent new problems during recovery.
- Review the incident. After recovery, analyze what happened, how the response worked, and what could improve. Post-incident reviews help prevent repeat outages.
- Strengthen future readiness. Update backup plans, monitoring, security, and training based on lessons learned. Every outage should lead to better resilience.
A clear response plan, strong backups, and fast communication greatly reduce the impact of a cloud outage.

Cloud Outage Prevention
While no system can guarantee zero downtime, many cloud outages can be prevented or reduced with the right planning and controls. Strong infrastructure, regular testing, and proactive monitoring help businesses lower risk and keep services available. The methods below are some of the most effective ways to prevent cloud outages.
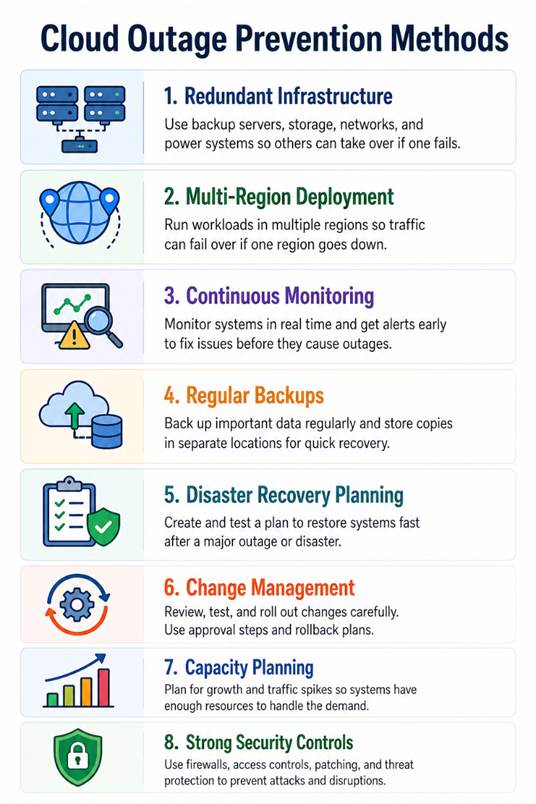
Redundant Infrastructure
Redundancy means having backup systems ready if a critical system fails. This can include extra servers, duplicate storage, spare network devices, and backup power systems. If one component stops working, another can take over, helping services stay online with little or no interruption.
Multi-Region Deployment
Running workloads in more than one geographic region helps reduce the risk of a single-location outage. If one data center or region has a problem, traffic can be redirected to another location. This improves availability and supports faster disaster recovery.
Continuous Monitoring
Cloud monitoring tools track servers, applications, networks, and cloud services in real time. They can detect unusual behavior, slow performance, or failures before users are heavily affected. Fast alerts allow teams to respond early and prevent small issues from becoming major outages.
Regular Backups
Backups protect important data if systems fail, become corrupted, or are attacked. Storing copies in separate locations or cloud regions adds extra protection. Reliable backups help businesses recover quickly without losing critical information.
Disaster Recovery Planning
A disaster recovery plan explains how to restore systems after a serious outage. It includes recovery steps, responsibilities, communication plans, and recovery targets. Testing this plan regularly helps teams act quickly during real incidents.
Change Management
Many outages happen after updates or configuration changes. Change management reduces this risk by reviewing planned changes, testing them first, and rolling them out carefully. Approval processes and rollback plans help prevent mistakes from causing downtime.
Capacity Planning
Cloud systems need enough computing power, storage, and bandwidth to handle demand. Capacity planning uses usage trends and forecasts to prepare for growth or traffic spikes. This helps prevent overloads that can slow down or crash services.
Strong Security Controls
Cyberattacks can cause outages by disrupting systems or locking access to data. Firewalls, access controls, DDoS protection, patching, and threat monitoring help defend cloud environments. Better security lowers the chance of attack-related downtime.
Protect critical data and recover quickly from unexpected outages with phoenixNAP Backup and Restore solutions. Secure backups, flexible recovery options, and reliable infrastructure help keep your business running with minimal downtime.
Staying Vigilant Amid Cloud Outages
Cloud outages are a real risk for any business that depends on online systems, but they do not have to become disasters. Understanding what causes outages, how they affect operations, and how to respond quickly can greatly reduce downtime and damage. With strong prevention strategies, backup systems, and clear recovery plans, businesses can stay more resilient and keep critical services running when problems occur.



