
Duplicate values create redundancies and can impact MySQL's performance. Database administrators often identify and remove duplicate values to maintain database reliability.
Ensuring a database is free of duplicates can optimize query performance and maintain data integrity. There are several ways to determine whether a MySQL database contains duplicate values.
This guide will show you how to find duplicate values in a MySQL database.

Prerequisites
- An existing MySQL installation.
- Root access (or a user with administrator privileges) for MySQL.
- Access to the command line/terminal.
How Do I Find Duplicates in MySQL
Finding duplicate values is crucial for efficient database management as it ensures data consistency and integrity. The following steps show a practical example of identifying duplicate entries in MySQL.
Step 1: Create a Sample Table (Optional)
To practice discovering duplicates in MySQL, create a table with test data that contains duplicate entries. The step is optional, but it ensures that testing does not affect existing data.
1. Open the terminal and connect to the database server:
mysql -u [username] -p
Replace [username] with the actual username.
Note: If the command is unrecognized, see how to fix the "MySQL Command Not Found" error.
2. Switch to the desired database:
USE [database_name];
Alternatively, create a database first, then switch to it.
Note: To check if a database exists, see how to list all databases in MySQL.
3. Use the following SQL query to create a sample table:
CREATE TABLE sample_table (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50),
email VARCHAR(100)
);
The statement creates a table with three columns that contain different data types.
4. Insert data into the table:
INSERT INTO sample_table (name, email) VALUES
('John', 'john@example.com'),
('Mary', 'john@example.com'),
('John', 'john@email.com'),
('John', 'john@example.com');
The command adds data to the new table, including several duplicate entry combinations.
Step 2: Find the Duplicates in MySQL
To identify duplicates in MySQL, use queries that locate entries that appear multiple times. Depending on the use case and data complexity, there are several ways to find duplicates via queries.
Option 1: GROUP BY and HAVING
The first option is to use the GROUP BY and HAVING clauses. This method groups data by the specified columns and counts entries in each group, showing only those with a count greater than one.
To find duplicate entries based on a single column, see the example code below:
SELECT email, COUNT(email)
FROM sample_table
GROUP BY email
HAVING COUNT(*) > 1;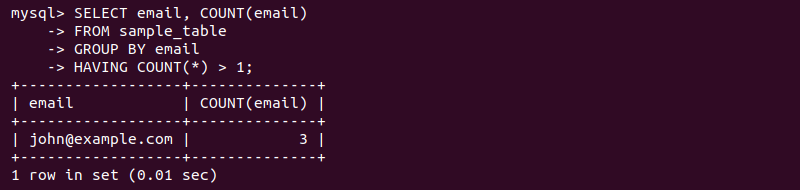
The code selects the email column and counts all instances where the same email appears more than once. The output displays the email address and the count of its occurrences.
To count duplicate entries based on multiple columns, see the following example:
SELECT email, name, COUNT(*)
FROM sample_table
GROUP BY name, email
HAVING COUNT(*) > 1;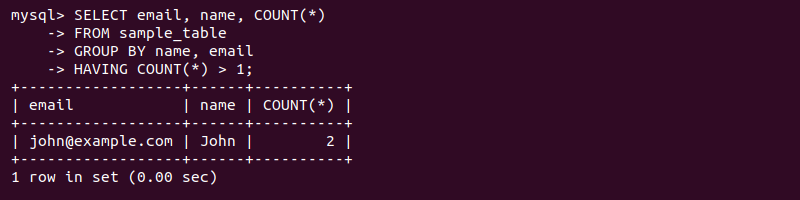
The query counts all instances where both the email and name columns match. The output shows the name, email address, and the count of duplicates.
Option 2: Self-join
Another method to find duplicate records is to use an INNER JOIN to join the table with itself based on specific columns. The self-join method compares all rows from the first copy with all rows from the second copy. See the example below:
SELECT a.id, a.name, a.email
FROM sample_table a
INNER JOIN sample_table b ON a.name = b.name AND a.email = b.email
WHERE a.id != b.id;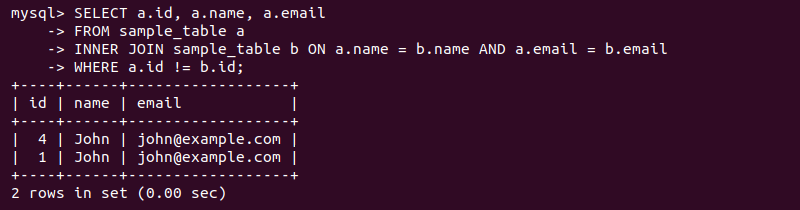
The query consists of the following:
sample_table aandsample_table b. Aliases for the same table. Enables treating the same table as two separate entities in the query.JOIN sample_table b ON a.name = b.name AND a.email = b.email. Joins the two tables, matching all rows with the samenameandemail.WHERE a.id != b.id. Shows rows with uniqueidvalues.
The query lists all rows with duplicate entries, including their details.
Note: See our in-depth guide on MySQL JOINs.
Option 3: Subquery
The subquery method identifies duplicate entries and joins the result with the original table. The method enables fetching the full column instead of just the duplicated value. For example:
SELECT sample_table.*
FROM sample_table
JOIN (
SELECT email
FROM sample_table
GROUP BY email
HAVING COUNT(email) > 1
) copy ON sample_table.email = copy.email
ORDER BY sample_table.email;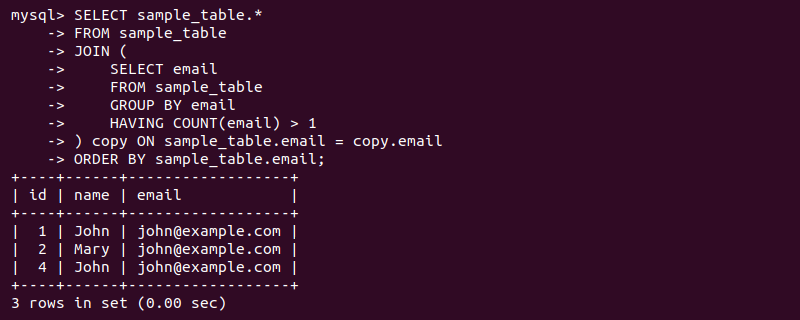
Although the query time is not optimal due to a subquery with another SELECT statement, the method shows the complete row for each duplicate entry.
Conclusion
This guide showed how to check for duplicate entries in a MySQL table. Use a method that best suits your use case, and adjust the examples to match the MySQL data in your database.
After finding duplicate values, see how to remove MySQL duplicate rows.



