
Duplicate rows commonly occur in MySQL databases with large numbers of entries due to errors in data processing, synchronization, and table import. If not removed, duplicates can create integrity and accuracy issues.
This guide will show you how to remove duplicate rows in MySQL.

Prerequisites
- MySQL installed.
- A MySQL root user account.
- Command-line access.
Find Duplicate Rows in MySQL
MySQL features multiple methods for discovering duplicate rows in a database. The most practical method uses the COUNT function, which counts how many times a single entry appears within a column. Once the COUNT function completes the task, the HAVING statement displays the entries that are the same across the columns.
For example, the following command counts entries in three columns (day, month, year) belonging to the table named dates. The HAVING statement then checks if any entries feature the same day, month, and year by inspecting their counts:
SELECT
day, COUNT(day),
month, COUNT(month),
year, COUNT(year)
FROM
dates
GROUP BY
day,
month,
year
HAVING
COUNT(day) > 1
AND COUNT(month) > 1
AND COUNT(year) > 1;The system prints any duplicate values in a table:
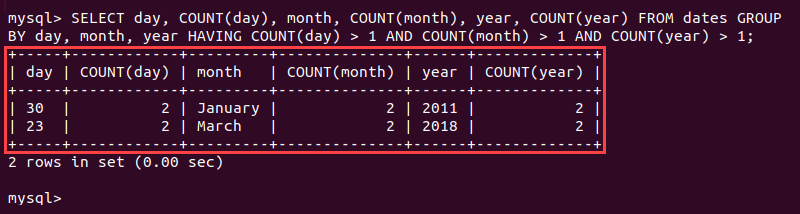
The example above illustrates a case with multiple columns for comparison. For tables that feature columns with unique identifiers, such as an email address on a contact list or a single date column, use the SELECT statement on that column only.
Note: Learn about other ways to find duplicate rows in MySQL.
Delete Duplicate Rows in MySQL
After confirming that a database contains duplicate entries, delete them using the options mentioned below. The options include using the ROW_NUMBER() function, the JOINS statement, the GROUP BY clause, and the DISTINCT keyword.
Before you begin, start the MySQL prompt and open the database in question with the command below:
USE [database];For example, to use the testdata database, type the following:
USE testdata;Option 1: Remove Duplicate Rows Using the ROW_NUMBER() Function
Important: This method is only available for MySQL version 8.02 and later. Check MySQL version before attempting this method.
The ROW_NUMBER() function returns the sequential number for each row within the previously defined partition. Like the COUNT() function, it can find duplicates in the table. Below is the syntax for this action:
SELECT *, ROW_NUMBER() OVER
(PARTITION BY [column1],[column2],[column3] ORDER BY [column])
AS [row-number-column]
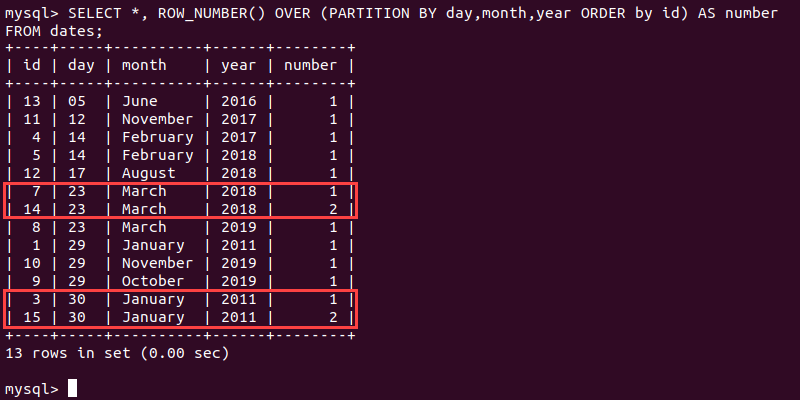
FROM [table];For example, the following command uses the ROW_NUMBER() function on the table called dates and partitions the data according to the day, month, and year:
SELECT *, ROW_NUMBER() OVER
(PARTITION BY day, month, year ORDER BY id)
AS number
FROM dates;The ROW_NUMBER() function creates a new temporary column (called number in the example below) that shows the number of duplicates in the table.
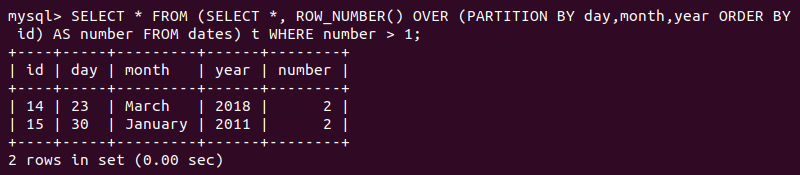
To see only the entries with the row number larger than one, type the following:
SELECT * FROM
(SELECT *, ROW_NUMBER() OVER
(PARTITION BY [column1],[column2],[column3] ORDER BY [column])
AS [row-number-column]
FROM [table]) t
WHERE [row-number-column] > 1;The output below shows the two duplicate entries in the example table.
Remove every entry except the ones marked with 1 to delete duplicate rows. Use the DELETE query with the ROW_NUMBER() function as the filter:
DELETE FROM [table] WHERE [column] IN
(SELECT [column] FROM
(SELECT *, ROW_NUMBER() OVER
(PARTITION BY [column1], [column2], [column3] ORDER BY [column])
AS [row-number-column]
FROM [table]) t
WHERE [row-number-column] > 1);Using the data from the examples above, the command would be:
DELETE FROM dates WHERE id IN
(SELECT id FROM
(SELECT *, ROW_NUMBER() OVER
(PARTITION BY day, month, year ORDER BY id)
AS number FROM dates) t
WHERE number > 1);After executing the command, verify there are no duplicate rows by running:
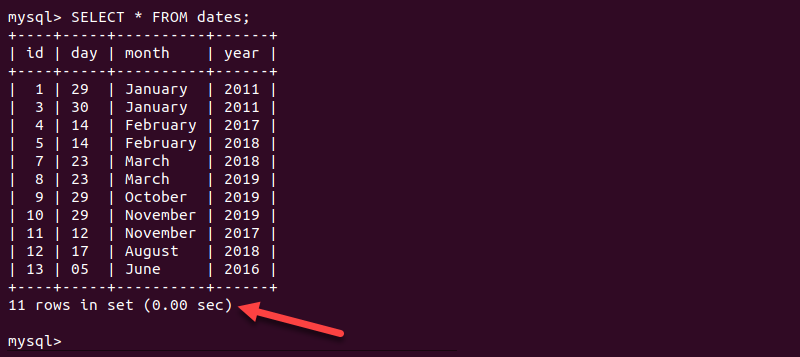
SELECT * FROM [table];For instance:
SELECT * FROM dates;The output shows the table contains two fewer rows than before.
Option 2: Remove Duplicate Rows Using the GROUP BY Clause
Delete duplicate rows by creating an intermediate table using the GROUP BY clause. To do this, transfer only the unique rows to the newly created table and delete the original table (which contains the remaining duplicates).
Follow the steps below to remove duplicates with the GROUP BY clause:
1. Enter the following command to create a new table based on the old table:
CREATE TABLE [new-table] LIKE [old-table];For example, type the following to create a table named dates_copy, which uses the data from the dates table:
CREATE TABLE dates_copy LIKE dates;2. Move the data to the new table with the command below:
INSERT INTO [new-table]
SELECT * FROM [old-table]
GROUP BY [columns];If a column shows the This is incompatible with sql_mode=only_full_group_by error, use the ANY_VALUE() function to pass the column's value into the command. This function is helpful for GROUP BY queries when the ONLY_FULL_GROUP_BY SQL mode is enabled.
In the dates table example, the command would be:
INSERT INTO dates_copy
SELECT ANY_VALUE(id), day, month, year FROM dates
GROUP BY day, month, year;3. Remove the old table with the DROP statement:
DROP TABLE [old-table];4. Rename the new table using the old table's name:
ALTER TABLE [new-table] RENAME TO [old-table];Note: Consider using SQL query optimization tools to find the best way to execute a query and improve performance.
Option 3: Remove Duplicate Rows Using the DISTINCT Keyword
Another way to delete duplicates using the intermediate table technique is to include the DISTINCT keyword. Proceed with the steps below to use DISTINCT to remove duplicate rows from a table:
1. Create an intermediate table that has the same structure as the source table and transfer the unique rows found in the source:
CREATE TABLE [new-table] SELECT DISTINCT [columns] FROM [old-table];For instance, the command to create a copy of the structure of the sample table dates is:
CREATE TABLE copy_of_dates SELECT DISTINCT id, day, month, year FROM dates;
2. Delete the source table with the DROP statement:
DROP TABLE [old-table];3. Rename the new table using the old table's name:
ALTER TABLE [new-table] RENAME TO [old-table];Option 4: Delete Duplicate Rows Using the MySQL INNER JOIN Keyword
The INNER JOIN keyword in MySQL selects the entries with matching values in two tables. Use it to remove duplicates from a table by designing a command that:
- Creates two logical instances of the same table with aliases t1 and t2.
- Compares values in the two logical tables.
- Transfers only the unique values to the new table.
Below is the basic syntax for the command:
DELETE t1 FROM [table] t1
INNER JOIN [table] t2
WHERE
[conditions]For example, to delete duplicate rows in the dates MySQL table, type the following command:
DELETE t1 FROM dates t1
INNER JOIN dates t2
WHERE
t1.id < t2.id AND
t1.day = t2.day AND
t1.month = t2.month AND
t1.year = t2.year;The first row of the condition that compares the id column keeps only the lowest id value for each group of duplicate entries.
Conclusion
After reading this tutorial, you should be able to remove duplicate rows in a MySQL table and improve your database performance. The article presented four options for deleting duplicates in MySQL and provided examples for each.
Before deleting rows and tables in MySQL, it is recommended that you create backups. Read How to Back Up and Restore a MySQL Database to learn more.



