
Ensuring the high availability of an application deployed in a Kubernetes cluster is essential in minimizing downtime and providing business continuity. The biggest challenges for maintaining high availability are cluster maintenance and scaling events, during which a simple human error can cause service disruption.
This article provides an overview of Pod Disruption Budget, a Kubernetes feature that addresses this problem.

What Is Kubernetes Pod Disruption?
Pod disruption refers to the situation in which a Kubernetes pod in a cluster stops working. A disrupted pod either remains in the failed state or completely disappears from the cluster.
When Kubernetes detects a pod disruption, it attempts to reschedule the affected pods onto other available nodes in the cluster.
Voluntary vs. Involuntary Disruption
Kubernetes ensures that scheduled pods are running at all times. There are two reasons why a pod stops working:
- A user terminates a pod (kubectl delete pod). The process of removing a pod is also known as voluntary disruption. The most common scenarios for voluntary pod disruption are node replacement, cluster upgrade, and workload scaling.
- A system error occurs. When a failure in hardware or software causes a pod failure, an involuntary disruption occurs.
What Is Pod Distribution Budget?
Pod Disruption Budget (PDB) is a Kubernetes policy that allows users to declare the minimum or maximum number of unavailable pods for an app in the cluster. The policy applies to voluntary disruptions only, as involuntary disruptions cannot be predicted or controlled.
Note: PDBs do not control all voluntary disruptions. If you delete a pod or a deployment, the loss of the pod will not be prevented by the PDB, even if it exceeds the budget.
How Do Pod Disruption Budgets Work?
Like other Kubernetes policies, Pod Disruption Budgets inform Kubernetes of the desired state of the cluster, which the orchestrator then attempts to enforce. In the case of PDBs, the desired state is the minimum number of pod replicas (or the maximum number of failed pods) that exist in the cluster at any given time.
The following is a typical PDB scenario:
- The user creates a PDB manifest and applies the policy to the cluster.
- When a voluntary disruption event occurs (cluster maintenance, scaling), Kubernetes checks the PDB and considers its constraints.
- Kubernetes reschedules the pods using a strategy that does not clash with the PDB.
Users can monitor the status of PDBs in the cluster using standard Kubernetes monitoring and reporting mechanisms.
Note: Learn more about Kubernetes monitoring tools and Kubernetes monitoring best practices.
Pod Disruption Budget Benefits
Creating and enforcing a PDB policy on your cluster increases its operational resiliency. A typical PDB will:
- Ensure high availability during upgrade and maintenance actions.
- Facilitate the execution of rolling updates, during which Kubernetes gradually replaces pod replicas with the new versions.
- Increase resource utilization efficiency by applying a strategy that prevents unnecessary pod evictions and optimizes the maintenance processes.
- Make the work easier for cluster administrators by increasing their confidence that their actions will not cause service disruption.
How to Set Pod Disruption Budget?
Like any other Kubernetes object, the procedure for creating a PodDisruptionBudget policy involves creating a YAML configuration file and applying it to the cluster.
Follow the steps in the sections below to create a PDB.
Step 1: Create YAML for PDB
The first step in creating a PDB is making a manifest file to define the pod disruption policy. Use a text editor such as Nano to create a YAML file:
nano [filename]Step 2: Configure PDB
Create and save a PDB manifest file by providing the following information:
apiVersion: policy/v1beta1
kind: PodDisruptionBudget
metadata:
name: [pdb-name]
spec:
minAvailable: [number]
selector:
matchLabels:
app: [app-name]A PDB declaration has two mandatory fields:
.spec.selectorspecifies how Kubernetes recognizes the pods to which it needs to apply the PDB..spec.minAvailableor.spec.maxUnavailableallow the user to specify the PDB condition that needs to be enforced.
Below is an example PDB that specifies that at least one pod running the Nginx deployment needs to be available:
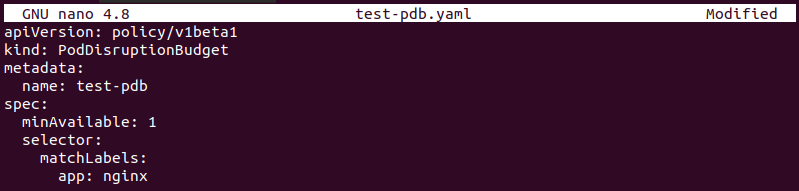
Aside from absolute values, a Pod Disruption Policy can be stated in percentages, too. For example:
spec:
maxUnavailable: 20%The policy above tells Kubernetes that at any given time, a maximum of 20 percent of the pods can be unavailable.
Step 3: Apply PDB to Cluster
Create the PDB by using kubectl apply:
kubectl apply -f [filename]The output confirms the creation of the PDB policy:

Check that the policy is active by viewing the available PDBs in the cluster:
kubectl get pdbThe policy shows up on the list alongside some basic information about it:

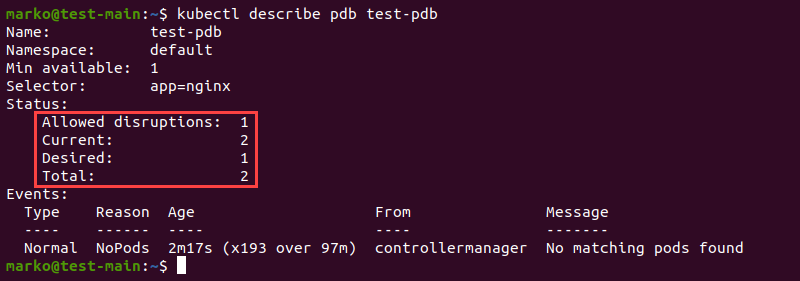
To see the policy details, type:
kubectl describe pdb [pdb-name]The output of the kubectl describe command shows the status of the PDB. The information includes the number of allowed disruptions and the current number of pods.
Important Considerations When Using PDBs
While Pod Disruption Budgets are relatively easy to create and use, there are some considerations to take into account when applying them to your cluster. The sections below list the most important of those considerations.
Monitoring Pod Disruption Status
Cluster administrators need to check the status of PDBs on their cluster regularly. This practice allows them to gain better knowledge about the cluster and understand the behavior of available resources.
Single Replicas and PDB
Enacting a PDB policy in single-pod deployments blocks the execution of the kubectl drain command. If you use single-pod deployments, avoid creating a PDB, or perform pod drains manually.
Horizontal Pod Autoscalers and PDB
Horizontal Pod Autoscalers allow scaling resources in Kubernetes based on system loads and a provided metric. When using HPAs in conjunction with PDBs, the system may fail to calculate the effect of the HPA, which shifts the number of pods dynamically, and an error may occur.
When using HPA and PDB together, define a PDB for blocking the HPA's scale-down process. Consider pausing the pods that the HPA uses to handle traffic increases.
Overlapping Selectors
Use clear and easy-to-understand selector names and ensure that the matchLabels field corresponds to the controller selector. In deployments with multiple PDBs, failure to do this may cause overlapping selectors and block the node draining.
maxUnavailable and PDB
If you set the maxUnavailable value in your Deployment manifest, the value will be enforced during a pod rollout. The same value pushed through a PDB is applied during a node rollout.
minAvailable and PDB
Do not set the minAvailable value in a PDB to 100 percent. In effect, this action prevents voluntary disruption, which makes cluster upgrades difficult.
Involuntary Disruptions and PDB
As already mentioned, the PDB cannot control involuntary pod disruptions caused by hardware and software failure. However, it is important to note that they still count against the PDB.
Unhealthy Pod Eviction Policy
You can set the .spec.unhealthyPodEvictionPolicy field to AlwaysAllow and enable Kubernetes to evict unhealthy nodes when it drains a node. If this policy is not set, Kubernetes waits for pods to be healthy before draining them, potentially causing significant delays.
Conclusion
After reading this overview, you should better understand the mechanism behind the Pod Disruption Budget in Kubernetes. The article explained the concept of the PDB, its benefits, and the procedures for its creation.
It also offered the most important considerations for those who intend to use PDBs in their clusters. Next, learn more about Kubernetes Operators in our guide.



