
Large Language Models (LLMs) are powerful but not perfect. They can give wrong, outdated, or made-up answers, which may spread false information. Developers must address these AI risks when deploying LLMs.
Retrieval-augmented generation (RAG) solves these problems by providing better answers. It uses outside sources to enhance responses.
This guide explains retrieval-augmented generation (RAG) in detail.

What Is Retrieval-Augmented Generation (RAG)?
Retrieval Augmented Generation (RAG) is an AI technique that mixes a search system with a language model. Unlike standard LLMs that rely on pre-trained data, RAG models search external sources before providing an answer. These sources, such as documentation, knowledge bases, logs, or the internet, can be general or specific.
As a result, RAG models are more accurate and provide relevant responses. The framework does not require retraining a model. Instead, it finds suitable data before generating a response in real time.
Why Is Retrieval-Augmented Generation Important?
Traditional language models are static and limited. They are trained on a specific dataset and cannot access new information unless retrained.
Fast-changing environments require new and accurate data. LLMs cannot fetch new information or provide sources for their answers, which is an issue in real-time scenarios.
For example, system settings, rules, or features can change daily, and traditional LLMs cannot keep up with this pace. Enterprise AI systems need quick and correct data to make decisions.
RAG solves this by introducing a retrieval step before responding. The model first finds relevant information from external sources and uses it to generate a more accurate response. This additional step makes a model clearer, reliable, and more accurate.
How Does Retrieval-Augmented Generation Work?
RAG follows a two-step architecture:
- Retrieval. When the model receives a user query, it uses the query and a retriever to perform a semantic search. It looks through external data sources, such as documents, papers, and snippets, to find helpful content.
- Generation. The found data and user query are passed to a generator (language model) that creates a relevant response based on the user's input and the context.
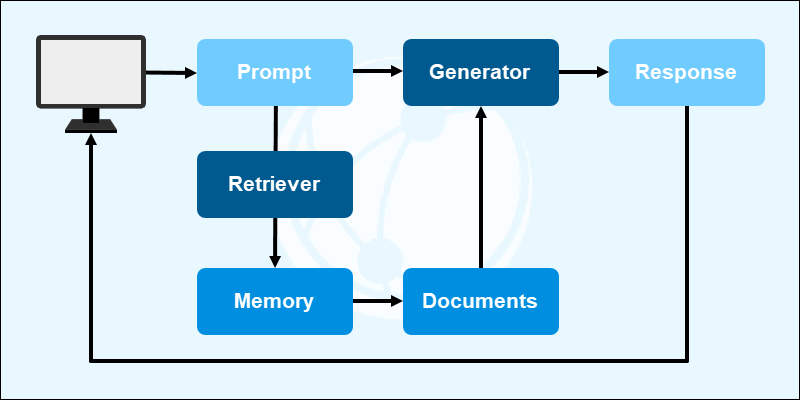
The pipeline can be improved with ranking mechanisms, feedback loops, and domain tuning to refine output quality. These upgrades are essential for secure and scalable deployments.
Benefits of Retrieval-Augmented Generation
There are many benefits of RAG. Some of them are:
- Up-to-date. The model has access to real-time data without having to retrain the model. As a result, the model has access to current data and provides better responses.
- Accuracy. By relying on trusted sources, responses are factual and grounded in vetted sources.
- Customization. The model is easily customized for specialized environments like private AI infrastructures, regulated fields, or cloud setups.
- Fewer hallucinations. Relying on real-world data helps avoid fake answers that sound right.
Retrieval-Augmented Generation Use Cases
Retrieval-augmented generation has many use cases. Some examples include:
- Customer support. RAG powers intelligent support assistants that answer customer queries. Generating document-backed responses reduces the support team's workload and resolves tickets faster.
- Legal and compliance. Regulations evolve, and it's essential to maintain the most current information in regulated industries. RAG can search through legal texts, compliance policies, and industry standards to assist professionals in checking information or drafting documents.
- Healthcare. To assist medical professionals, RAG can retrieve the latest research papers, treatment plans, and drug information. It aligns with the growing role of AI in healthcare.
- Academic research. Researchers can collect information from various sources, repositories, journals, and publications. A RAG system can simplify literature review times and provide better insight.
- Enterprises. Large organizations often have fragmented internal documentation. RAG can act as a centralized source for employees to reference critical information, such as wikis, operation manuals, or policy documents.
- DevOps and Infrastructure. Cloud and infrastructure teams can use RAG systems to fetch relevant API docs, system logs, or runbooks. It can also help in real-time troubleshooting and suggest configuration improvements.
Challenges and Limitations of Retrieval-Augmented Generation
Despite its advantages, retrieval-augmented generation comes with several challenges. They require robust system design, especially for mission-critical and highly regulated environments.
Limitations of RAG include:
- Source data maintenance. The retrieval quality highly depends on the available knowledge base. If the source data is biased, outdated, or incomplete, the generated response reflects that.
- Latency and performance. Adding a retrieval step increases processing time. Real-time applications require applying optimization techniques, like result caching or model distillation.
- Scalability. RAG systems for enterprise workloads have increased infrastructure complexity due to requiring efficient vector databases, indexing, and cost-effective storage.
- Security. Accessing sensitive or proprietary data in real time requires careful compliance and access control planning to minimize exposure.
- Debugging. RAG-generated outputs are difficult to troubleshoot and debug compared to standard language models. Splitting the process into two stages creates complexity when troubleshooting.
Conclusion
This guide explained what retrieval-augmented generation is and how it works. As AI continues to evolve, the RAG framework will aid in creating specialized and more trustworthy systems.
Next, learn more about the AI impact on data centers.



