
The uniq command in Linux filters out repeated lines in a file or from command line input. It compares consecutive lines and removes duplicates, which makes it useful for analyzing sorted data, cleaning output or log files, or preparing reports.
This tutorial will explain the syntax of the uniq command, list the options, and provide practical usage examples.

Prerequisites
uniq Command Syntax
The uniq command removes repeated lines from sorted inputs. It works with or without arguments and supports input from files or standard input.
The input must be sorted for uniq to work correctly, since it only removes consecutive duplicate lines.
The syntax is:
uniq [options] [input_file] [output_file]The syntax consists of:
[options]. Optional flags that change how lines are compared or displayed.[input_file]. The file to read from. If omitted, the command reads from standard input.[output_file]. The file to write to. If omitted, the command writes to standard output.
uniq Command Options
Options modify how uniq compares lines and controls what lines are shown. The following table presents the most common uniq options:
| Option | Description |
|---|---|
-c | Prefixes each line with the number of occurrences. |
-d | Displays only lines that appear more than once. |
-u | Displays only lines that appear exactly once. |
-i | Ignores case when comparing lines. |
-f N | Skips the first N fields when comparing lines. |
-s N | Skips the first N characters when comparing lines. |
-w N | Limits comparison to the first N characters. |
--help | Displays usage information and exits. |
uniq Command Examples
The uniq command is used in data processing pipelines, especially when combined with sort and other text-processing tools. It helps filter reports, clean output from scripts, and identify frequency patterns in logs or data files.
The following sections present practical examples that show how to use uniq with different options and input formats.
Remove Duplicate Lines from a File
To remove duplicate lines from a file, use uniq without any options. This command compares consecutive lines and outputs only the first occurrence of each.
For example, to test this, use a sample text file. Take the following steps:
1. Create a sample file named names.txt with duplicate lines. Use a text editor like Vim or Nano, or run echo:
echo -e "Charlie\nAlice\nAlice\nCharlie\nBob\nCharlie" > names.txtThe command has no output.
2. View the original file contents with cat:
cat names.txt
3. Sort the file to group duplicate lines together, since uniq works only on adjacent duplicates:
sort names.txt -o names_sorted.txtThe command does not have an output, but creates a new file called names_sorted.txt.
4. View the sorted file contents with:
cat names_sorted.txt
5. Run uniq on the sorted file to remove duplicates:
uniq names_sorted.txt
This process ensures uniq filters duplicates correctly by comparing consecutive lines.
Count Occurrences of Duplicate Lines
The -c option prefixes each output line with the number of times it appears in the input. This is useful to see the frequency of repeated lines.
Since uniq reads from both a file (like in the previous example) and standard input, this example shows how uniq uses standard input via a pipe.
Follow these steps:
1. Create a sample file colors.txt with repeated lines:
echo -e "red\nblue\nred\nyellow\nblue\nblue" > colors.txt2. Verify the contents with:
cat colors.txt
3. Use a pipeline to sort the file and count duplicates with uniq. This approach avoids creating a separate sorted file. Instead of passing a file directly to uniq, the sort command output is streamed into uniq as standard input:
sort colors.txt | uniq -c
The output shows counts before each line. This pipeline method is helpful because it guarantees duplicates are adjacent before counting.
Note: Using uniq -c on an unsorted file may give incorrect results.
Show Only Duplicate Lines
The -d option shows only lines that appear more than once. This is useful when analyzing logs, filtering repeated records, or auditing duplicate entries.
Follow these steps to print only repeated lines:
1. Create a file named logs.txt with both unique and repeated lines:
echo -e "update\nlogin\ndelete\nlogout\nlogin\ndelete" > logs.txt2. View the file contents with:
cat logs.txt
3. Sort the file so duplicate lines are grouped together
sort logs.txt -o logs_sorted.txt4. View the sorted contents:
cat logs_sorted.txt
5. Use uniq with the -d option to display only the repeated lines:
uniq -d logs_sorted.txt
Only the lines that appear more than once are shown. Lines that occur just once are excluded.
Show Only Unique Lines
The -u option displays only the lines that occur only once in the input. It filters out all duplicates and shows entries that are not repeated. This provides the exact opposite output of the -d option, which shows only duplicate lines.
Follow these steps to print only unique lines:
1. Create a file named devices.txt with both repeated and unique lines:
echo -e "printer\nscanner\nprinter\nmonitor\ncamera\ncamera" > devices.txt2. Verify the file contents:
cat devices.txt
3. Sort the file to group duplicate lines together:
sort devices.txt -o devices_sorted.txt4. View the sorted contents
cat devices_sorted.txt
5. Use uniq with the -u option to display only the lines that appear once
uniq -u devices_sorted.txt
This command filters the list to include only non-repeated items, which is useful when extracting unique entries from data files or logs.
Ignore Case When Comparing Lines
The -i option makes uniq ignore case when comparing lines. This is useful when the input contains the same text in different letter cases, and you want to treat them as duplicates.
Follow these steps:
1. Create a file named fruits.txt with mixed-case repeated lines:
echo -e "Apple\napple\nBanana\nbanana\nAPPLE\nCherry" > fruits.txt2. Check the file contents with:
cat fruits.txt
The output shows text with both uppercase and lowercase letters.
3. Sort the file with case-insensitive sorting to group duplicates regardless of case:
sort -f fruits.txt -o fruits_sorted.txt4. Verify the sorted contents:
cat fruits_sorted.txt
5. Use uniq with the -i option to ignore case when filtering duplicates:
uniq -i fruits_sorted.txt
This outputs only one instance of each fruit, ignoring letter case differences.
Skip Fields or Characters When Comparing Lines
The -f N option skips the first N fields (whitespace-separated words on the line), and the -s N option skips the first N characters when comparing lines. These options are useful when the duplicate lines differ only in specific parts you want to ignore, such as timestamps or IDs.
Follow these steps to skip the first field and find duplicates:
1. Create a file named records.txt with lines where the first field varies but the rest are duplicates:
echo -e "2025-07-01 apple\n2025-07-02 apple\n2025-07-01 banana\n2025-07-02 banana" > records.txt2. Verify the file contents with:
cat records.txt
The file contains two groups of entries:
- First field with different dates.
- Second field with identical item names.
3. Since the goal is to skip the first field (date), sort the file by the second field (item name). That way, the duplicates become adjacent after the field skip:
sort -k2 records.txt -o records_sorted.txt4. Confirm the sorted file contents:
cat records_sorted.txt
We sorted by the second field, and the output is the same as with cat records.txt. The reason is that records.txt was already sorted this way.
5. Use uniq with the -f option to skip the first field (date) and find duplicates based on the second field:
uniq -f 1 records_sorted.txt
Alternatively, if the date is part of a fixed-width prefix, skip characters with -s. For example, to skip the first 11 characters (date plus space), run this command:
uniq -s 11 records_sorted.txt
This filters duplicates, ignoring the specified fields or characters at the start of each line.
Filter Kernel Messages with uniq
The uniq command helps analyze real-time output from system utilities. For example, when reviewing kernel messages with dmesg, repeated lines are common.
Use uniq in a pipeline to filter and count those messages by following these steps:
1. Run dmesg to display kernel messages. Pipe the output to sort and then to uniq -c to group identical lines and count their occurrences:
sudo dmesg | sort | uniq -c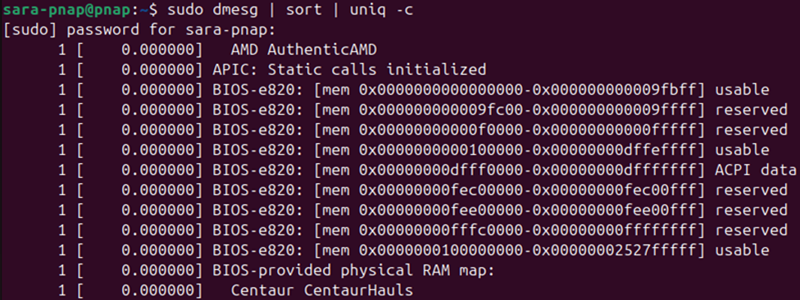
The command consists of:
- sudo. Gives administrative privileges (you can also log in as root).
dmesg. Outputs raw kernel messages.sort. Arranges all the lines in alphabetical order, so identical lines become adjacent.uniq -c. Counts how many times each line appears.
In the output, the numbers at the beginning of each line indicate how many times that exact line appeared.
2. Review the output to identify messages that appear frequently.
In this case, most lines start with 1. That is because most kernel messages are unique. Higher numbers indicate recurring warnings or errors, like when an item is spamming the logs or when the system has repeated hardware warnings.
This approach works without temporary files and is helpful when debugging hardware issues or analyzing boot-time events. It also demonstrates how to use uniq as part of real-time system monitoring pipelines.
Conclusion
This tutorial explained the uniq command, its syntax, and frequently used options. It also elaborated on how the command works through several practical examples.
Next, learn about the Linux awk command for advanced text processing.



