Growing demands for extreme compute power lead to the unavoidable presence of bare metal servers in today’s IT industry. Their goal is to handle the most intensive workloads by providing extreme processing power to a single tenant. No shared resources and immense scalability options position bare metal servers as a smart choice for growing infrastructures.
With GPUs (Graphic Processing Units) added to the mix, modern data centers now offer servers with parallel processing capabilities for Deep Learning and HPC (High-Performance Computing) applications. These applications are so demanding on CPU resources that all-purpose servers prove to be cost-intensive in these circumstances. NVIDIA® Tesla® GPU-accelerated servers became a cornerstone for solving today’s most complex scientific and engineering challenges.
By following this guide, you will learn how to install Nvidia Tesla Drivers on Linux and Windows.

How to Install NVIDIA® Tesla® Drivers on Windows
Installing Windows drivers for a Tesla graphics card is straightforward. You may find the procedure to be similar to installing drivers for other NVIDIA GPUs. The operating system itself may install the drivers, but we highly recommend you download and install the latest version of a driver package dedicated to Tesla GPUs.
Download Tesla Driver Package
In order to make sure you are downloading the latest NVIDIA® Tesla® GPU drivers for your server, you need to use the package available on the manufacturer’s website.



- Navigate to https://www.nvidia.com/ and from the top menu under ‘DRIVERS’ select the “ALL NVIDIA DRIVERS” option.
- Once the page loads, select the options from the drop-down menus to download the drivers for the graphics card you have in your bare metal server:
- Product Type: select Tesla.
- Product Series: for Tesla V100 select V-Series; for Tesla P40 select P-Series.
- Product: for V-Series select Tesla V100; for P-Series, we offer Tesla P40, make sure to select the right model.
- Operating System: select an operating system and version. In this case, we will select Windows Server 2016.
- CUDA Toolkit: select a version of NVIDIA’s CUDA toolkit for your development environment. The most recent version is 9.2. You can always check the latest version and the release notes on the website.
- Language: select one from many available languages for this installation package.
- Click SEARCH after you finish making your selection.
- The next screen shows driver details such as version, release date, size etc. Click DOWNLOAD to proceed to the next screen.
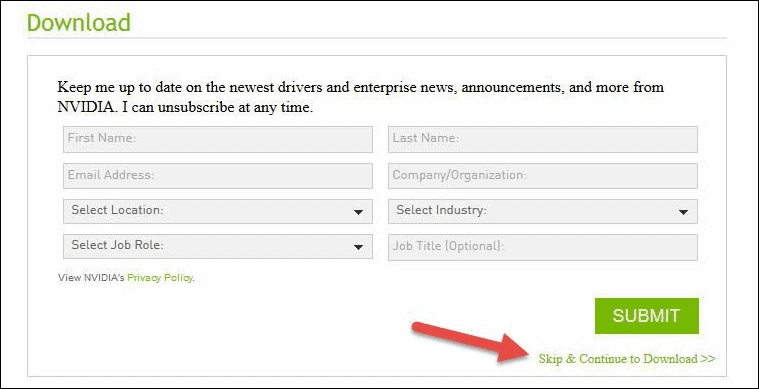
- Depending on your location, this step may differ. If you get the screen to subscribe for a newsletter, you can skip it. To proceed to the download screen simply click “Skip & Continue to Download”. Otherwise, fill in your information and click SUBMIT.Before you actually get to download the installation package, the final screen informs you to make sure you read and agree with the Licence For Customer Use of the Software. Click the button “AGREE & DOWNLOAD” to start the download.
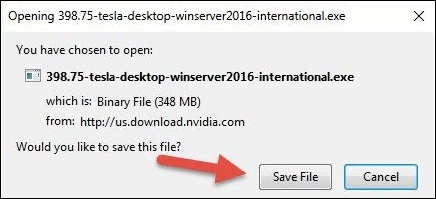
- Save the file to the desired location on your server and wait for the download to complete.
Run NVIDIA Tesla Driver Wizard
Before going through the steps in the NVIDIA® Tesla® driver wizard, you will need to extract the files to the desired location.
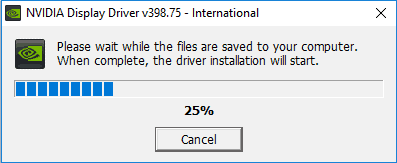
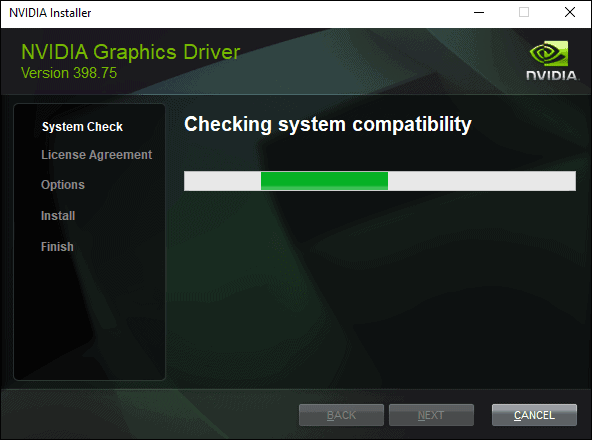
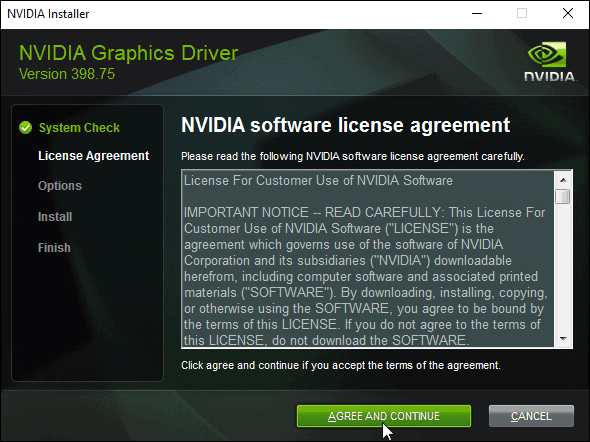
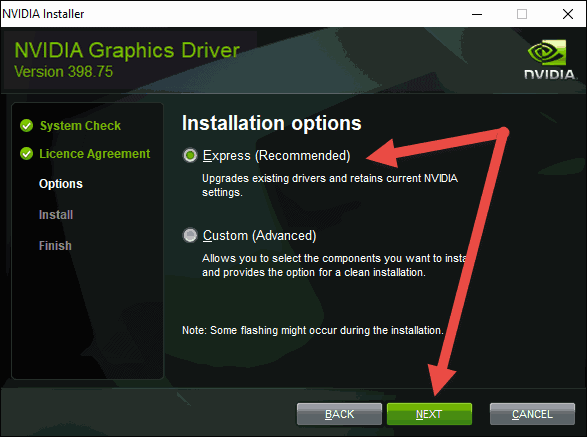

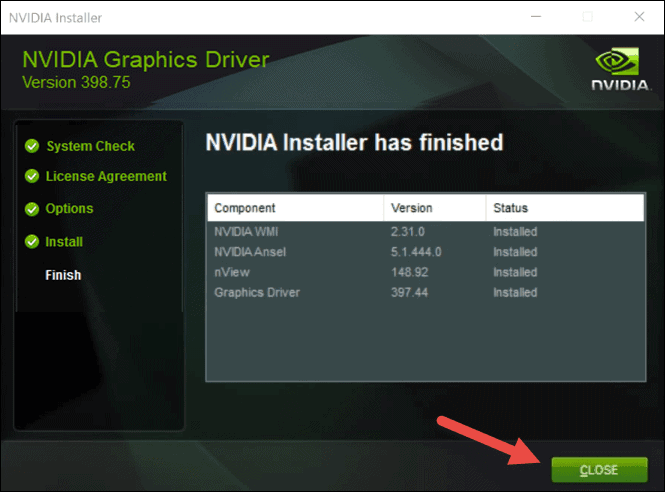
- Run the executable file you downloaded from NVIDIA’s website. Select a location on your hard drive and click OK. The progress bar appears to show the files are being saved to the selected location.
- Once the extraction process finishes, the wizard will start. It performs a system check for hardware compatibility to make sure you downloaded the correct drivers. Let it finish and it should proceed to the License Agreement step if you selected the proper installation package.
- Read NVIDIA software license agreement. Click AGREE AND CONTINUE to proceed to the Options step of the wizard.
- In the Options step, you can choose between two options: an express and a custom installation. To quickly complete the installation, click Next to continue using the ‘Express (Recommended)’ option.At the bottom of the window, you will see the progress bar. Give it a few minutes until it finishes the installation.
- The final screen shows the status of your installation. This includes all the components the wizard installed. If any of them failed to install, you will see a warning here. Simply click the CLOSE button to successfully complete the installation.
Verify Tesla GPU Has Been Installed
Depending on the service you have, you can have up to 8 Tesla V100 GPUs in one server. Beside the NVLink Tesla V100 SXM2 GPU version shown in the Device manager above, we offer two more GPUs:
- Go to Start – > Device Manager.
- Press Windows + R keys on your keyboard to open the “Run” box. Type in
devmgmt.mscand hit Enter to load the Device Manager list.
On the device list, expand the Display adapters and you should see all your NVIDIA® Tesla® cards.
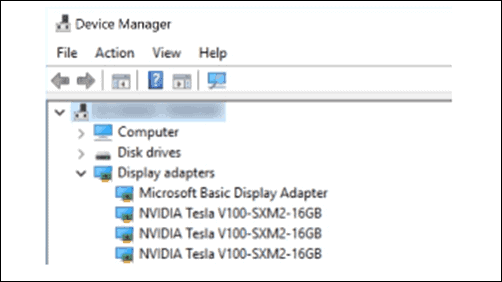
- NVIDIA® Tesla® V100 16GB CoWoS HBM2 PCIe 3.0 – Passive Cooling (GPU-NVTV100-16)
- NVIDIA® Tesla® P40 24GB GDDR5 PCIe3.0 – Passive Cooling (GPU-NVTP40)
Set Maximum GPU Clock Frequency
NVIDIA® Tesla® GPUs support the autoboost feature to increase performance by changing clock values for both memory and GPU core in certain conditions. You can turn off this feature and set your custom clock rates with NVIDIA System Management Interface.
To do this, load Windows PowerShell and navigate to the NVIDIA NVSMI folder:
- As an administrator, run the nvidia-smi –ac <memory clock, GPU clock> command to specify the custom values, for example:
nvidia-smi –ac 2605, 1050 - If you are unsure, you can always check the supported clock rates for your GPU by running this command:
nvidia-smi –q –d SUPPORTED_CLOCKSTo check the current memory and graphics clock frequency, run this command:nvidia-smi –q –d CLOCK - Finally, if you decide to revert the clock frequency changes to their default values, run the following command:
nvidia-smi -rac
How to Install NVIDIA® Tesla® Drivers on Linux
This section will show how to install NVIDIA drivers on an Ubuntu machine. Linux comes with open source drivers, but to achieve maximum performance of your card, you need to download and install the proprietary NVIDIA drivers. The installation procedure is the same from Ubuntu version 16.04 onward.
To download the corresponding drivers, follow the steps indicated in the Downloading the Tesla Driver Package section in this article.
If you cannot locate your Linux distribution on the list, you may need to click on “Show all Operating Systems”.
Once your download finishes, load the terminal (Ctrl+Alt+T) and navigate to the folder where you downloaded the file. Alternatively, you can download the drivers by using the wget command and the full download URL:
wget http://us.download.nvidia.com/tesla/396.37/nvidia-diag-driver-local-repo-ubuntu1710-396.37_1.0-1_amd64.debWith the file available locally, run the following commands:
sudo dpkg -invidia_driver_filename.debE.g., The latest proprietary NVIDIA drivers for Ubuntu 17.10 :
sudo dpkg -i nvidia-diag-driver-local-repo-ubuntu1710-396.37_1.0-1_amd64.debsudo apt-get updateThis updates the list of packages and gets the information on the newest available version.
Next, run the command to install CUDA drivers on your machine.
sudo apt-get install cuda-driversWait until it finishes and then run the final command.
sudo rebootA reboot is necessary after the driver installation takes place.
To confirm the system is using your Tesla GPU and not the integrated one, navigate to System Details to check hardware information.
Note: Looking for a different tutorial? Visit our guides How To Install Nvidia Drivers On Ubuntu, How to Install Nvidia Drivers on Debian or How to Install Nvidia Drivers on Fedora.
.
Why NVIDIA Tesla GPU-Enabled Servers
There are more than 500 HPC GPU-accelerated applications that will exhibit an extreme performance boost with servers utilizing NVIDIA® Tesla® GPUs. Additionally, all available deep learning frameworks are optimized for GPUs and provide massive boosts in performance.
A single server with an NVIDIA® Tesla® V100 GPU can outperform dozens of CPU-only servers when it comes to GPU-intensive applications. This way, cost savings are substantial due to less network overhead and the reduction of overall power consumption with fewer servers running. At the core of Tesla V100 is NVIDIA Volta architecture that makes this GPU provide inference performance of up to 50 individual CPUs. In specific use cases, a single GPU’s performance is comparable to the performance of around 100 CPUs.
The benefits of deploying a server with an NVIDIA® Tesla® GPU are numerous:
- Cut costs and increase performance at the same time.
- Stay on top of the AI and HPC game with GPU-accelerated servers.
- Take advantage of hundreds of applications that are optimized for GPU usage.
- Excel and achieve breakthroughs in various research domains such as physics, quantum chemistry, deep learning, molecular dynamics, and many more.
NVIDIA Tesla P40 and Tesla V100 Architecture Overview
PhoenixNAP offers servers with GPU capability that will fit everyone’s budget. Tesla V100 runs on Volta architecture and comes in two versions, PCI Express and SXM2 with NVLink interconnection. Tesla P40 with PCIe interface runs on Pascal architecture and it is usually used in smaller IT environments.
Depending on your computational needs, you can choose PCIe GPU-enabled servers with up to three cards. For large workload-intensive deployments, we can interconnect up to 8 Tesla V100 SXM2 NVlink GPUs to offer unparalleled HPC and Deep Learning power.
Pascal Architecture
NVIDIA released Tesla P40 in 2016 and with it offered the world’s fastest GPU intended for inference workloads. 47 Tera-Operations per Second (TOPS) of INT8 operation per card delivered a game-changing deep learning performance. With SM (streaming multiprocessor) at its core, Tesla P40 can execute commands between many parallel threads. Powered by Pascal architecture, every Tesla P40 GPU-enabled server still offers throughput higher than dozens of CPU-only servers combined.
Tesla P40 GPUs are made using 16nm FinFET manufacturing process. This process improved power efficiency, performance and provided more features needed for modern data centers with computationally demanding workloads. With Pascal Architecture, NVIDIA introduced an inference engine called TensorRT. It is optimized for high efficiency in most deep learning applications, for example, object detection or classification of images.
Volta Architecture succeeded Pascal but has not rendered it obsolete. Still providing extreme performance at a reasonable cost, NVIDIA® Tesla® P40 is an excellent choice in modern small to medium size deployments.
Volta Architecture
PhoenixNAP is proud to offer the best NVIDIA’s GPUs with the latest Volta architecture that brings massive improvements in performance. Tesla V100 GPU represents the fastest and most advanced parallel processor ever produced to this date. As opposed to Pascal’s architecture, Volta uses high-end TSMC 12nm manufacturing process which allows for groundbreaking compute power leaps. Inside a Tesla V100, there are almost two times more transistors than in Tesla P40, i.e. 21.1 billion with a die size of 815 mm².
There has been a redesign of streaming multiprocessor (SM) architecture that lead to a massive FP32 and FP64 performance increase while being 50% more energy efficient. 640 Tensor Cores in the Tesla V100 brake the three-digit TFLOP barrier with 120 TFLOPS of deep learning performance. This brings 12x more TFLOPs of deep learning training performance and 6x more TFLOPs for deep learning inference when compared to Pascal architecture.
One of the new Volta features is MPS: Multi-Processor Service which provides CUDA MPS server components with hardware acceleration. This leads to an improved quality of service when multiple applications are sharing the GPU. The maximum number of MPS clients has been tripled as well, when compared to Pascal architecture.
All these improvements in the Volta architecture made Tesla V100 the absolute king of the hill in the world of high performing Data Center GPUs and we are proud to offer it with our servers. With up to 8 Tesla V100 GPUs interconnected with NVLink, you are able to create an extreme performance deployment with support for every deep learning framework and over 500 HPC applications.
NVIDIA Tesla V100 and Tesla P40 Performance Comparison
| Specifications | Tesla P40 | Tesla V100 PCIe Gen3 | Tesla V100 SXM2 NVLink |
| GPU Architecture | Pascal | Volta | Volta |
| Manufacturing Process | 16 nm | 12 nm | 12 nm |
| GPU Die Size | 471 mm² | 815 mm² | 815 mm² |
| Transistor Count | 12 billion | 21.1 billion | 21.1 billion |
| GPU Memory | 24 GB | 16GB HBM2 | 16GB HBM2 |
| Memory Bandwidth | 346 GB/s | 900 GB/s | 900 GB/s |
| GPU Boost Clock | 1531 MHz | 1380 MHz | 1530 MHz |
| CUDA cores | 3840 | 5120 | 5120 |
| Tensor Cores | N/A | 640 | 640 |
| Single-Precision and Double-Precision Performance | 12 TFLOPS | 14 TFLOPS 7 TFLOPS | 15.7 TFLOPS 7.8 TFLOPS |
| Tensor Performance | N/A | 112 TFLOPS | 120 TFLOPS |
| Maximum Power Consumption | 250 W | 250 W | 300 W |
| ECC | Yes | Yes | Yes |