Database denormalization is a technique used to improve data access performances. When a database is normalized, and methods such as indexing are not enough, denormalization serves as one of the final options to speed up data retrieval.
This article explains what database denormalization is and the different techniques used to speed up a database.

What is Database Denormalization?
Database denormalization is the process of systematically combining data to get information quickly. The process brings relations down to lower normal forms, reducing the overall integrity of the data.
On the other hand, the data retrieval performances increase. Instead of performing multiple costly JOINs on numerous tables, database normalization helps bring together information that is commonly or logically combined.
Database anomalies appear because of lower normal forms. The problem of redundancies finds a solution in adding software-level limitations when inputting data into a database.
Database Normalization vs. Denormalization
Database normalization and denormalization are two different ways to alter the structure of a database. The table describes the main differences between the two methods:
| Normalization | Denormalization | |
|---|---|---|
| Functionality | Removes redundant information and improves data change speeds. | Combines multiple information into one unit and improves data retrieval speeds. |
| Focus | Cleaning up the database to remove redundancies. | Redundancies introduced for faster query execution. |
| Memory | Optimized and improved general performance. | Memory inefficiency due to redundancies. |
| Integrity | Removal of database anomalies improves database integrity. | No maintained data integrity. Database anomalies are present. |
| Use Case | Databases where insert, update and delete changes happen often and joins are not expensive. | Databases that are often queried, such as data warehouses. |
| Processing Type | Online Transaction Processing - OLTP | Online Analytical Processing - OLAP |
Database normalization takes an unnormalized database through normal forms to improve data structure. On the other hand, denormalization starts with a normalized database and combines data for faster execution of commonly used queries.
Note: Visit our article OLTP vs. OLAP: A Comprehensive Comparison to learn more in-depth about these two processing types.
Why and When Should You Denormalize a Database?
Database denormalization is a viable technique when data retrieval speed is an essential factor. However, the method changes the overall database structure. Denormalization is helpful in the following scenarios:
- Query performance enhancement. Putting together information adds redundancies. However, the number of JOINs reduces, which increases query performance.
- Management convenience. A normalized database is hard to manage because of high granularity. Instead of calculating values or connecting them as needed, denormalization helps provide readily available data.
- Accelerated reporting. Analytical data requires a lot of calculations promptly. A denormalized database for generating reports is a perfect solution for providing analytical information quickly.
If a database has low performance, denormalization is not always the right way to go. Since the process changes the database structure, existing functionalities are at risk of breaking down.
Note: Database issues often arise due to a poorly designed database. Consider learning about the different database types available and choosing the right option for your use case.
Having a point of reference is an important concept when changing the database structure. Ultimately, database normalization serves as a last resort instead of a quick solution.
Denormalization Techniques
There are various database denormalization techniques used depending on the use case. Each method has an appropriate place of use, advantages, and disadvantages.
Pre-joining Tables
Pre-joined tables store the frequently used pieces of information together into one table. The process comes in handy when:
- Queries frequently execute on the tables together.
- The join operation is costly.
The method creates massive redundancies, so it is essential to use a minimal number of columns and update the information periodically.
Example of Pre-Joining Tables
A store keeps the information about items and the categories to which the items belong. The foreign key serves as a reference to the item type. Pre-joining the tables adds the category name to the items table.
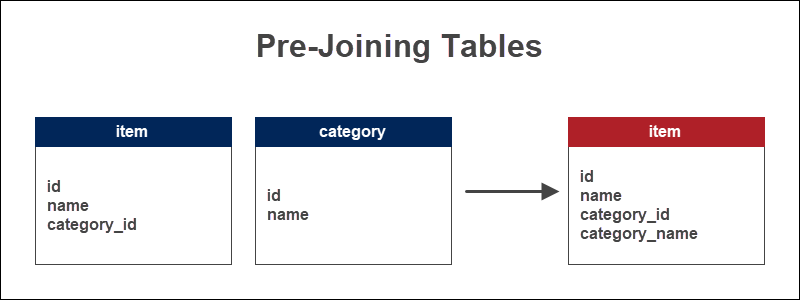
Adding the category name directly to the table of items allows viewing the items by category quickly. For lengthier queries, this method saves time and reduces the number of JOINs.
Mirrored Tables
A mirrored table is a copy of an existing table. The table is either:
- A partial copy.
- A full copy.
The goal is to reproduce the data from the original into a new table. Making duplicates is a good technique for creating a backup to preserve the initial state of the database.
Example of Mirrored Tables
Mirroring tables is a method often used for preparing data in decision support systems. Since the queries usually aggregate over many data points, the task would significantly decrease the system performances.
Decision support systems greatly benefit from the use of mirrored tables. Applying transactions over the original table goes uninterrupted while demanding reports happen on the duplicate table.
Table Splitting
Table splitting implies dividing normalized tables into two or more relations. Dividing tables happens in two dimensions:
- Horizontally. Tables split into row subsets using the
UNIONoperator. - Vertically. Tables split into column subsets using the
INNER JOINoperator.
The method's goal is to split tables into smaller units for faster and more convenient data handling. If the database also contains the original table, this method is considered a particular case of mirrored tables.
Examples of Table Splitting
The usage examples depend on the criteria of table splitting. The most common reasons for dividing tables are:
- Administrative. One table for every sector instead of one table for a whole company.
- Spatial. One table for every region instead of one table for the whole country.
- Time-based. One table for every month instead of one table for a whole year.
- Physical. One table for each location instead of one table for all sites.
- Procedural. One table for each step in a task instead of one table for a whole job.
Storing Derivable Values
Storing frequently executed calculations is worthwhile in situations where:
- The use of the derived value is frequent.
- The source values do not change.
Directly storing derivable data ensures calculations are already done when generating a report and eliminates the need to look up the source values for each query.
Example of Storing Derivable Values
If we have a database table that keeps track of information about people, a person's age is a calculated value based on their date of birth. Derive the age by finding the difference between the current date using the MySQL date function CURDATE() and the date of birth.
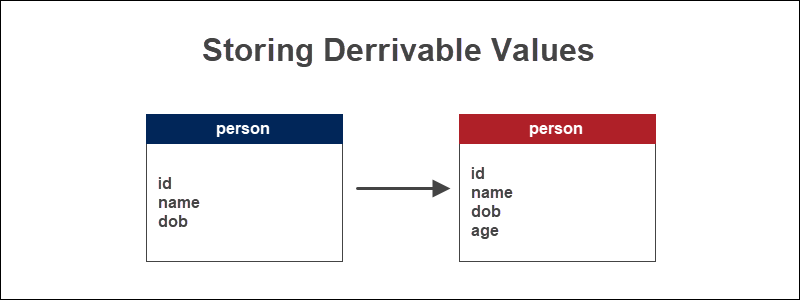
Age is an essential piece of information when analyzing any demographic information. The source value, which is the date of birth, does not change.
Hierarchy Tables
A hierarchy table is a tree-like structure with a one-to-many relation. One parent table has many children. However, the children have only one parent table. Hierarchy tables are used in cases where:
- The structure of the data is hierarchical.
- The parent tables are static and unchanging.
Hard-Coded Values
Hard-coded values remove a reference to a commonly used entity. Use this method in situations where:
- The values are considered static.
- The number of values is small.
Instead of using a small look-up table, the values are hardcoded into the application directly. The process also avoids having to perform joins on the look-up table.
Example of Hard-Coded Values
A table with information about people could use a small look-up table to store information about the gender of individuals. Since the information in the look-up table has a limited number of values, consider hard-coding the data into the table of people directly.
Hard-coded values eliminate the need for a look-up table and the JOIN operation with that table. Any alterations made in the look-up table or recording of new values require the addition of a check constraint.
Storing Details with Master
The master table contains the main table of information, whereas other tables contain specific details. Store the details with the master table when:
- A detailed overview of the master table is essential.
- Analytical reports on the master table are frequent.
Keeping all the details with the master table is convenient when selecting data. The method works best when there are fewer details. Otherwise, the data retrieval process slows down significantly.
Example of Storing Details with Master
A master table with customer information typically stores specific details about the person in a separate table. Information about the particular location, for example, usually resides in a series of smaller tables.
Any report that considers the customers' location benefits from adding the location details to the master table.
Repeating Single Detail with Master
Queries often need just a single detail added to the master table instead of pre-joining multiple values. Use this method when:
- JOINs are costly for a single detail.
- The master table requires the information often.
Adding a single detail to a master table is most common when the database contains historical data. The repeated entity is usually the newest information.
Example of Single Detail with Master
A store database normally has a master table of information about items it sells. Another table with details about the historical price changes also contains the information on the current price.
Since this single detail helps analyze the current item prices, the latest information about the price is handy to repeat in the master table.
Any cost changes need to be addressed and updated into the master table as well for consistency.
Short-Circuit Keys
In a database with three or more tables of related information, the short-circuit keys method skips the middle table(s) and "short-circuits" the grandparent and grandchild tables.
Use the short-circuit technique in situations where:
- A database has over three levels of master-detail.
- The values from the grandparent and grandchild are often needed and the parent information is not as valuable.
If two relations relate through a middle table, omit the JOIN on the intermediate relation and connect the first and last table directly.
Example of Short-Circuit Keys
An information system could keep information about people in one table, their address in another location, and the geographic area of that address in a third table. For any demographic report, the exact address is not a critical piece of information.
However, the location of a person is essential for analysis. Short-circuiting the table of people with the area omits the JOIN on the middle table.
Denormalization Advantages
The advantages of database denormalization are:
- Speed. Since JOIN queries are costly on a normalized database, retrieving data is faster.
- Simplicity. Fetching data is more straightforward because of the smaller number of tables.
- Fewer errors. Working with a smaller number of tables means fewer bugs when retrieving information from a database.
Denormalization Disadvantages
The disadvantages to consider when denormalizing a database are:
- Complexity. Updating and inserting into a database is more complex and costly.
- Inconsistency. Finding the correct value for a piece of information is more challenging because the data is hard to update.
- Storage. More significant storage space is necessary due to introduced redundancies.
Conclusion
This article provides a clear idea of what database normalization is and how to apply it to certain situations. Carefully consider the reasons and methods behind denormalization. Making any changes to a database might be permanent and irreversible.