
Redis is a remarkably fast, non-relational database solution. Its simple key-value data model enables Redis to deal with large datasets while sustaining impressive read-write speeds and availability.
Redis allows you to use various data types such as Lists, Hashes, Sets, and Sorted Sets to store and manage data.
In this tutorial, learn how Redis Data Types work and master basic commands for each data type.

Redis Data Types
A key-value database structures data by applying a unique key to each data object. Use the key to manage and retrieve values assigned to that specific key. Any binary sequence of up to 512 MB in size can be used as a Redis key and then associated with simple strings or other abstract data structures.
Redis keys are mapped to values by using one of seven different data types:
- Strings
- Lists
- Hashes
- Sets
- Sorted Sets
- HyperLogLogs
- Bitmaps (BitStrings)
Each Redis data type has its own set of commands for routine access patterns, transaction support, and bulk operations if you do not have Redis installed, use our detailed guides to install Redis on Ubuntu or deploy Redis on Docker.
Strings
A string represents the smallest value you can attach to a key. The maximum allowed size of a string value is 512 MB, containing any sequence of characters. In Redis, the key part of the key-value pair is a string as well.
Databases using this type of data structure are often referred to as string-to-string key-value stores.
With all the data in a single object, string operations in Redis are extremely fast. Basic Redis commands like SET, GET, and DEL allow you to perform essential operations on the string value.
SET key value– Sets the value for the specified key.GET key– Retrieves the value for the specified key.DEL key– Deletes the value for the given key.
The following example illustrates how to use these straightforward commands within the redis-cli interactive shell. The SET command adds the value to the key while the GET command fetches and displays the value. If no value is mapped to the key, the GET command’s output is (nil).

If a value exists, the output for the DEL command shows the number of items being deleted. Adding new keys and values does not affect database performance or processing speeds.
Use Case: Strings are primarily used for caching HTML elements, widgets, and even entire web pages. Session and user-specific data are stored in-memory to speed up and enhance the website browsing experience. Redis strings can also facilitate resource distribution as a supplement to messaging or traffic balancing applications.
Lists
Redis allows you to associate an ordered sequence of strings to a key. This linked list of strings lets you perform a set of operations such as:
LPUSH– Pushes the value to the left end of the list.RPUSH– Pushes the value to the tail end of the list.LRANGE– Retrieves a range of items.LPOP/RPOP– Used to display and remove items from both ends.LINDEX– Obtain a value from a specific position within the list.
When adding values to a list with the LPUSH/RPUSH commands, the output provides the current number of items. You can then fetch the entire list using the LRANGE command with 0 as the start and -1 signifying the last index item.
Retrieve a specific value from the linked list using the LINDEX command or remove items with the LPOP/RPOP command.
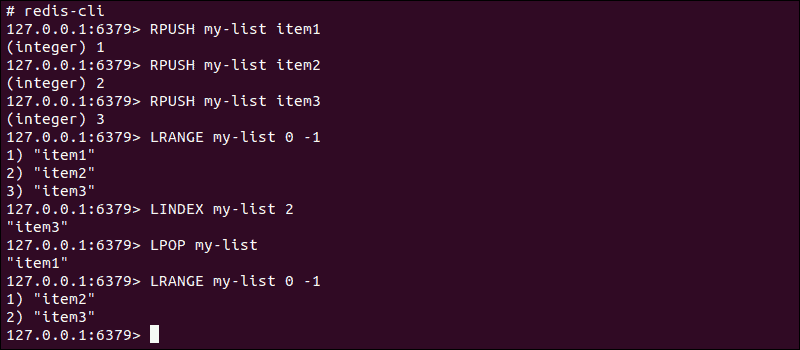
Adding values to a linked list is an efficient operation that does not affect write speeds regardless of its size. However, reading data from a linked list can depend on the number of strings on the key-value pair’s value side.
Use Case: The possibilities offered by linked lists make them an ideal data type for storing real-time data updates, such as social media posts or logs.
Hashes
A Redis hash stores an unordered mapping of key-value pairs. A hash-key is associated with a value. The value is a Redis string that contains other key-value pairs. You cannot use other complex data structures, such as Sets, Lists, or other Hashes as values.
Basic hash commands allow you to access and change individual or multiple fields independently.
HSET– Map a value to a key within the hash.HGET– Retrieves individual values associated with a key within the hash.HGETALL– Displays the entire hash content.HDEL– Removes an existing key-value pair from a hash.
Each time an item is added to the hash with the HSET command, a return value (integer) n informs you if an entry already exists and the number of instances. This same information is provided when using the HDEL command.
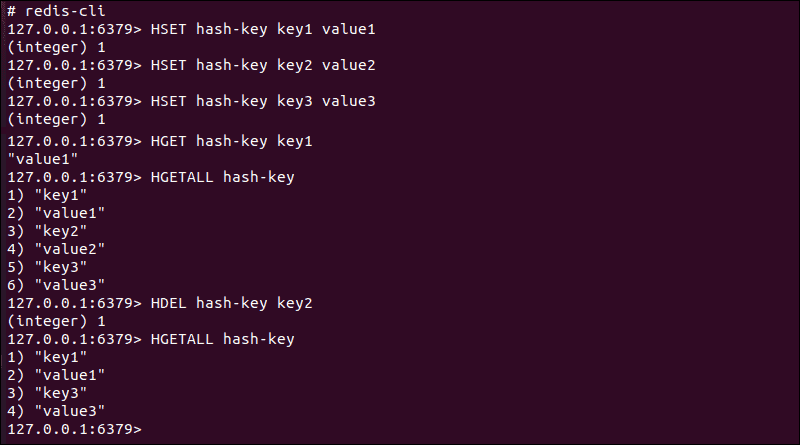
Use Case: A hash can store millions or even billions of objects very efficiently. The number of available fields makes Hashes very useful for maintaining a large collection of individual objects such as user data.
Sets
A Redis set is an unordered collection of unique strings. As sets are not ordered, you cannot remove items from the front or end of the index as with lists. However, the strings are unique, and there is no possibility that multiple instances of the same item appear within a set.
Use the following commands to add, remove, retrieve, and inspect individual items of a set:
SADD– Add one or more items to a set.SISMEMBER– Find out if an item is part of a set.SMEMBERS– Retrieves all items from a set.SREM– Removes an existing item from a set.
Adding the same item multiple times to a set always produces a single copy. As a result, you do not need to use the SMEMBERS or SISMEMBER command to determine if an item is already a member of a set.
Use the SADD command to make sure there are no duplicate entries within a set.
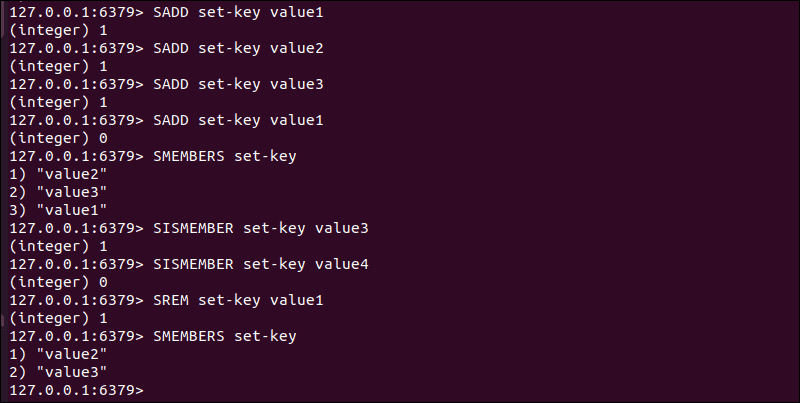
Use Case: Redis sets are well suited for tracking one-of-a-kind events such as unique page views or individual IPs. Sets also support advanced actions like the union, intersection, and difference operations.
Sorted Sets
Sorted sets or ZSETs are one of the most advanced data types in Redis.
The value part of a sorted set key-value pair is composed of a unique string element (key) called a member, and an item (value) is called a score. Sorted sets map every element to a floating-point value (score) and use that value to sort elements in a specific order.
You can access items in sorted sets by member, sorted order, and by the score values. Basic commands allow you to fetch, add, remove individual values, or retrieve items based on member values and score ranges.
ZADD– Adds a member with a score to the sorted set.ZRANGE– Retrieves items based on their position in the sorted order. Thewithscoresoption produces the actual score values.ZRANGEBYSCORE– Fetches items from the sorted set based on the defined score range. Thewithscoresoption produces the actual score values.ZREM– Removes items from a sorted set.
Only the member value of the member-score pair is treated as unique. If you associate two different scores to the same member value, only the latest addition will be present in the sorted set. If two different members have the same score, Redis orders the values alphanumerically.
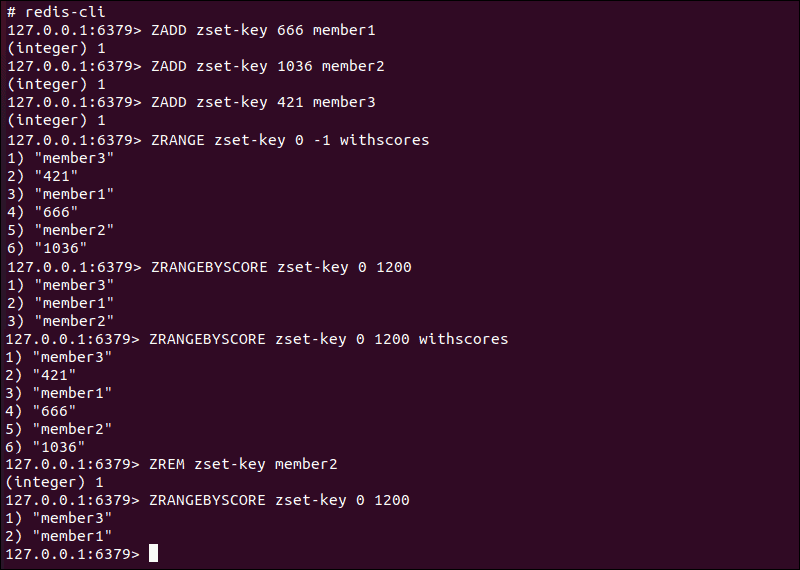
Use Case: A single sorted set can keep track and provide ordered leaderboards of player scores in an online competition using either the ZRANGE or ZREVRANGE Redis command.
HyperLogLogs
HyperLogLogs provide an estimated count of unique items in a collection. As opposed to other solutions, items in a HyperLogLogs are not individually counted, as that would require to keep track of previous items to avoid counting the same element twice. Such an operation requires the amount of memory equal to the memory used to store the data.
The HyperLogLog structure uses a much more efficient probabilistic algorithm that estimates a set’s size instead of counting each item. The error rate of the estimate is under 1%.
HyperLogLog commands allow you to add items, retrieve an estimated count of unique items, and create a union of multiple HyperLogLogs.
PFADD– Add one or several elements to a HyperLogLog.PFCOUNT– Fetch an estimated count of unique items from a single HyperLogLog.PFMERGE– Merge different HyperLogLogs into a single HyperLogLog.
The accuracy of the results can vary based on the size of the collection. However, if you do not need an exact count of items, this probabilistic structure allows you to use only a fraction of the memory you would otherwise need.
Use Case: Use HyperLogLogs to aggregate and count unique user interactions or queries.
Bitmaps
A Redis string is a binary sequence with a maximum size of 512 megabytes. Bitmaps allow you to manipulate strings on the bit level by using the appropriate commands.
SETBIT– The bit is defined or cleared based on a 0 or 1 value.GETBIT– Retrieves the bit value for the string value specified by a key.BITOP– Execute bitwise operations between strings.BITPOS– Locate the first bit set to 1 or 0 in a string.BITCOUNT– Count the number of bits set to 1 in a string.
Being able to manipulate bits of a string provides exceptional space-saving opportunities. It also provides a means to access and work on the data’s fundamental elements directly.
Use Case: Operating on bits simplifies real-time analytics, population counters, and tracking user activity. Bitmaps are frequently used to store data that can be represented as a boolean yes/no separation across consecutive keys.
Conclusion
You now have a thorough understanding of Redis Data Types and the basic commands associated with each data structure. Redis provides flexibility for designing a viable and effective storage solution for your application.
Now that you have familiarized yourself with Redis Data Types, check out our other Redis tutorials such as How to Delete These Key-Values and Clear Redis Cache.



