
Site reliability engineering (SRE) and DevOps are two closely related IT practices that help teams create better software. Whether you're a developer or someone higher up the executive pole, understanding the differences between the two practices (as well as where they overlap) will help you create and maintain high-quality software.
This article explains the similarities and differences between SRE and DevOps. We take an in-depth look at both practices. their benefits, usual tasks, and go-to tools to explain their distinct roles in the software development life cycle (SDLC), and help you evaluate which one is worth adding to your team's day-to-day operations.

What Is SRE?
Site reliability engineering (SRE) is a set of practices that enables teams to automate repetitive IT operations tasks through software engineering. SRE automates time-consuming jobs (code deployments, incident response, production management, etc.) while boosting the reliability of DevOps infrastructure.
The main idea behind SRE is that using software to automate the oversight of IT systems is a more scalable, cost-effective, and sustainable strategy than doing everything manually. Other fundamental SRE principles are:
- Develop the least complex system that performs as intended.
- Accept that there is no such thing as zero risk, so avoid pursuing more reliability than necessary.
- Plan for downtime, network latency, and scalability risks from the very start.
- Strive for maximum system observability.
- Enable teams to build and deploy software in a consistent, stable, and repeatable way.
SRE bridges the gap between development and ITOps teams, empowering both departments:
- Developers get to bring new software to production as quickly as possible.
- ITOps get to know that the new deployments align with the company's service level agreements (SLAs).
SLAs are a crucial factor in SRE as these figures set the baselines of acceptable uptime and response times. Other vital SRE metrics are:
- Service level objectives (SLOs): These metrics track a system's service level (such as availability or recovery time) and ensure you're meeting SLA-based expectations.
- Service level indicators (SLIs): SLIs enable a team to evaluate whether the system meets its SLOs. Error rates and system throughput are typical examples of SLIs.
- Error budgets: This metric dictates the maximum time a system can be down or underperform without violating its SLA. Error budgets are similar to RTOs, but SRE teams use the error budget more proactively (typically to decide when to push updates into production).
Learn more about service level agreements and see how companies use SLA-based metrics to attract customers and set a base for service delivery.
What Problems Does SRE Solve?
SRE helps companies solve a range of problems common in IT operations and software development. Here are the most notable ones:
- Inability to meet the IT standards set by the company's SLAs.
- Too much tension between developers who want to release new software into production and ITOps who don't want to cause operational issues.
- Difficulties in identifying and resolving performance issues and bottlenecks.
- Capped or inefficient scalability.
- Frequent service downtime and too many unplanned outages.
- Lack of system or service observability (on-prem or in the cloud).
- Slow MTTRs (Mean Time to Recovery, the average time it takes a team to recover from a system failure) and MTTDs (Mean Time to Detect, the average time between the beginning of an incident and the moment the team identifies the issue).
- Problems with provisioning infrastructure.
- Lack of effective incident response plans or disaster recovery strategies.
- Inefficient or unreliable deployment processes.
- Lack of a structured approach to availability management.
- Too many manual, error-prone processes during software development.
- Difficulty in identifying and proactively mitigating security vulnerabilities.
- Inability to meet compliance needs.
- Problems with utilizing cloud computing services or infrastructure (or simply having too expensive cloud bills).
Learn the ins and outs of cloud computing costs and get a firm understanding of how providers calculate cloud bills.
SRE Responsibilities
Every company tasks its SRE specialists with different responsibilities, but there are a few duties you'll find in every team. Here's a list of the most common SRE tasks:
- Use server automation to streamline repetitive and time-consuming tasks (deploying servers, setting up software, running cybersecurity checks, etc.).
- Define and implement reliability requirements for systems and services.
- Measure reliability goals (SLAs, SLIs, SLOs, and error budgets).
- Help developers build and deploy highly available, scalable, and fault-tolerant software.
- Make data-driven decisions about deploying new features or applications.
- Perform capacity planning to forecast future resource needs and ensure systems handle increasing levels of traffic or data.
- Scale systems up to ensure optimal performance or down to lower expenses.
- Track the performance and availability of systems.
- Continuously seek opportunities to enhance and refine IT processes and procedures.
- Improve incident response plans to minimize the impact of failures and quickly restore service in times of crisis.
- Perform post-incident reviews to identify the root cause of failures and prevent similar incidents in the future.
- Develop (or oversee the creation of) system documentation.
SRE is either a responsibility of several specialists or an entire team of 5-10 dedicated staff members. The allocated budget and the overall IT complexity are the two main factors in determining how many people work on SRE-related tasks.

SRE Benefits
Here is an overview of all the advantages that come with adopting SRE:
- Improved uptime and availability of systems and services.
- Better app scalability and performance.
- Faster, more reliable, and safer software delivery.
- Automation of repetitive tasks and processes.
- More fault-tolerant services with fewer (and less impactful) failures.
- Significantly fewer bugs in production.
- Greater visibility into service health.
- Less chance of human errors throughout the SDLC (plus developers have more time to innovate).
- An in-depth knowledge of the product ecosystem (development, test, stage, and production).
- More security across the board (incident prevention, disaster recovery plans, risk mitigation, up-to-date security practices, more redundancy, etc.).
- Shorter MTTRs and MTTDs.
- More context for identifying root causes in the event of an incident.
- Improved customer satisfaction and retention rates.
- Lower operational costs due to less downtime, better scalability, and optimal use of resources.
- Better control and use of technical debt.
Learn about technical debt and see how strategic shortcuts during software development help push projects forward without causing long-term problems.
SRE Tools
SRE teams rely on various tools to automate processes and manage systems. Here's what you're likely to find in any SRE tool stack:
- Performance optimization tools: These platforms help SRE teams identify and resolve performance bottlenecks in software systems. Apache JMeter and LoadRunner are among the most popular options.
- Configuration management tools: SRE experts use these platforms to automate the provisioning and configuration of infrastructure. Terraform, Ansible, Puppet, Pulumi, and Chef are the most common options.
- Monitoring and logging tools: These platforms track the performance and availability of software systems. Go-to SRE monitoring tools are Prometheus and New Relic, while Elasticsearch and Kibana are popular logging solutions.
- Incident management tools: SRE teams use these platforms to minimize the impact of failures (both on end-users and the company's finances). PagerDuty, VictorOps, and OpsGenie are three common choices, while OP5, PagerDuty, and xMatters are go-to incident alert tools.
- Containerization tools: These platforms enable teams to package software into containers, portable packets of code that seamlessly run in any environment. Kubernetes, Rancher, and Portainer are the industry standards, with Docker Swarm also enjoying a sizable following.
- Security tools: These platforms ensure systems are secure and compliant with standards and regulations. A few common SRE security tools are Nessus, OpenVAS, and Wireshark.
- Project planning and management tools: SRE departments use these tools to coordinate duties and create a unified source of information. Most teams rely on a combination of Jira and Confluence.
Almost 50% of companies that rely on DevOps also use SRE, a percentage that'll only grow over time. The main drivers behind SRE adoption are the desire for better system observability, control over dynamic apps, and enhanced IT reliability.
What Is DevOps?
DevOps is a set of practices and principles that enable companies to shorten the SDLC and improve the quality of code. With DevOps, the team that writes the code is also responsible for maintaining it in production, while staff members tasked with post-production duties also participate in development.
DevOps improves both the cultural and organizational aspects of software development. Here are the main goals of this methodology:
- Break down the silos between software development (Dev) and IT operations (Ops) teams.
- Ensure the rapid release of stable, secure software.
- Reduce the time it takes for a team to go from an idea to code deployment.
- Increase the overall quality of software.
In day-to-day practice, DevOps follows either lean or agile methodologies. Here are the main principles of DevOps:
- Ensure that the tasks of the development and ITOps teams overlap.
- Accept failures and fail fast (but never repeat the same mistake twice).
- Introduce change gradually via minor, incremental updates instead of deploying sizable changes to production.
- Strive to have more frequent releases.
- Utilize automation to accelerate DevOps pipelines and reduce the number of error-prone manual tasks.
- Continuously measure success (a few typical DevOps metrics are the lead time for changes, deployment frequency, time to restore service, and change failure rate).
Our article on DevOps principles offers a detailed breakdown of all the rules a high-performing DevOps team should follow.
What Problems Does DevOps Solve?
DevOps solves various problems commonly found in large software development teams and projects. Here are the most common issues that push companies toward DevOps:
- Slow time-to-market for new features and updates.
- Too many misunderstandings, code reworks, and delays during software projects.
- Ineffective communication between developers, IT operations team members, and business leaders.
- Vague software delivery processes.
- Poor code quality and app performance.
- Underperforming development teams.
- Needlessly high IT costs.
- Too many software vulnerabilities.
- Unstable and buggy deployment environments.
- Ineffective software testing procedures.
- Too many time-consuming manual tasks throughout the software delivery process.
- Low employee retention rates in the development and ITOps teams.
- Slow onboarding of new developers and issues arise when they leave the company.
Are security concerns the main problem you're looking to solve with DevOps? Consider adopting DevSecOps, a methodology that ensures the security team plays as big of a role in software delivery as developers and ITOps.
DevOps Responsibilities
The exact responsibilities of a DevOps team vary between organizations, but there are some tasks every team performs. Here's a list of typical duties:
- Create, maintain, and optimize software development pipelines.
- Oversee the entire software development life cycle, from development to production.
- Organize sprints (weekly, bi-weekly, or monthly) to manage workflows and assign tasks.
- Create and configure servers, networks, and other components that support the software delivery process.
- Write scripts and utilize tools to automate tasks like building, testing, and deploying software.
- Monitor for errors and troubleshoot pipeline issues.
- Optimize app and service performance.
- Identify and address development bottlenecks.
- Design, implement, and spearhead disaster recovery strategies.
- Keep track of all the software and hardware components in the system.
- Ensure systems are secure and that all teams follow DevOps security best practices.
- Perform chaos engineering (a strategy of "breaking things" on purpose and monitoring how the system responds to stress).
Our article on DevOps roles and responsibilities offers an in-depth overview of all the duties you should assign to your DevOps team.

DevOps Benefits
Here's a list of the main benefits you should expect from adopting DevOps at your organization:
- Faster time-to-market.
- A better alignment of IT projects with business objectives (the core of any sound IT strategy plan).
- A more productive software development team.
- Improved quality of software with fewer defects in production.
- Increased business agility and the ability to respond to market changes.
- More stable apps and services.
- The ability to effectively deploy and manage apps at scale enables IT to keep up with business growth.
- A well-oiled, planned-out software delivery pipeline (from conception and development to post-production monitoring and upgrades).
- Shorter release cycles.
- Less reliance on manual tasks.
- Improved performance monitoring and analytics.
- Happier customers and end-users due to better-performing apps, fewer bugs, and more frequent updates.
- Increased security and an improved ability to identify and resolve software-related risks.
- IT cost savings result from fewer repetitive tasks and reduced need for manual intervention during the SDLC.
- A team culture of always striving for improvements, optimizations, and innovation.
Intrigued by these benefits? Check out our article on DevOps transitions and see what it takes to adopt this methodology.
DevOps Tools
Here's a list of the types of tools you'll need to form an effective DevOps team:
- Source code management tools: These platforms enable teams to track source code, keep up with issues, and perform code reviews. The most popular tools are Git and Mercurial.
- Containerization platforms: These tools enable engineers to create container-based apps that run seamlessly in different IT settings. The two usual go-to solutions are Kubernetes and Docker.
- CI/CD tools: CI/CD stands for continuous integration and continuous delivery, a method of frequently delivering updates to users through automation. Examples of popular CI/CD tools are Jenkins, Bamboo, and CircleCI.
- Configuration management tools: These platforms enable DevOps engineers to automate infrastructure-related tasks, such as configuration and maintenance. Most teams work with Ansible, Terraform, or Puppet.
- Monitoring tools: These solutions enable DevOps teams to monitor apps and respond promptly to failures and risks. Splunk, Nagios, and Raygun are common choices.
- Collaboration and planning tools: Inter-team collaboration is at the heart of DevOps, so every team has one or more tools for centralizing info and planning projects. Like with SRE, most DevOps work with Jira and Confluence.
Our article on the market's best DevOps tools provides a detailed overview of features for every platform mentioned above.
SRE vs. DevOps: The Crucial Difference
SRE and DevOps share many similarities (same tools, emphasis on automation, bridging the gap between traditionally separate teams, etc.), but they are two distinct practices.
The table below goes through the main differences between SRE and DevOps:
| Point of comparison | SRE | DevOps |
|---|---|---|
| Main goal | Ensure systems and apps are available, scalable, and performant. | Improve and speed up software creation while enforcing continuity. |
| Primary IT focus | Ongoing maintenance and operation of infrastructure and systems in production. | Development and deployment of software via CI/CD pipelines. |
| Main practices | Reliability engineering, automation, incident management, and performance optimization. | Automation, CI, continuous delivery/deployment, and Infrastructure as Code (IaC). |
| Typical team members | Experienced system engineers and operations personnel. | A variety of roles (product owners, developers, QA experts, engineers, sysadmins, release managers, etc.). |
| Areas of expertise | Agile development, cloud computing, scripting, and production automation. | Responsible for resolving any bugs in the end product . |
| Main automation focus | The management and maintenance of production systems. | The software delivery process. |
| Development focus | Implementation of core development (automating tasks while minimizing IT risk). | Core development (writing, testing, and pushing software into production). |
| Rollout priority | Ensure new changes don't increase the failure rate in production. | Implement new features as seamlessly and quickly as possible. |
| Primary metrics | Error budgets, SLOs (service level objectives), SLIs (service level indicators), and SLAs (service level agreements). | Deployment frequency and failure rates. |
| Debugging tasks | Not involved in debugging (unless there is a production outage). | Responsible for resolving any bugs in the end product. |
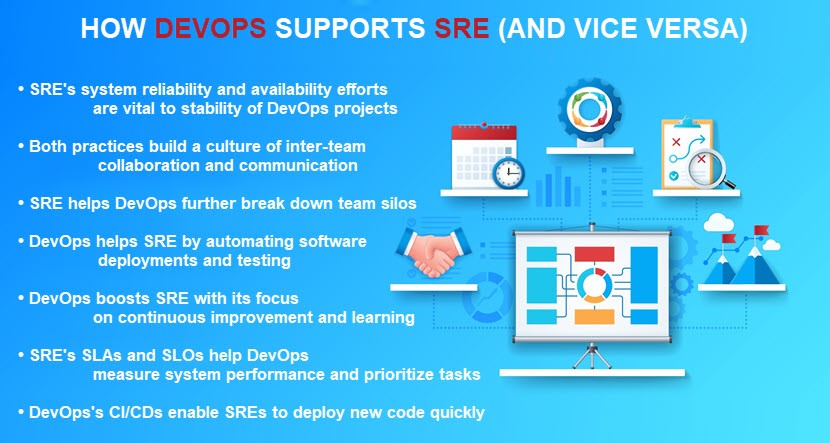
Many experts consider SRE an essential component of DevOps as there's no improving the reliability of software delivery without adding SRE-like elements to a DevOps pipeline.
Take IT to the Next Level with SRE or DevOps (Or Both)
SRE and DevOps are two cornerstone practices of modern software development. While they focus on somewhat different aspects of IT, both strive to improve the reliability and quality of software products. You can't go wrong with choosing either of the two practices. Also, remember that SRE and DevOps are not mutually exclusive. Adopting both practices is always a worthwhile decision if you have enough resources and sufficient in-house talent.



