
Managing vast amounts of unstructured data is a pressing challenge for many organizations. Object storage offers a way to handle this data by storing it as discrete units called objects, each with metadata and a unique identifier. Object storage addresses problems like scalability limitations of traditional file systems and inefficiencies in data retrieval and management.
This article provides an in-depth look at object storage, its architecture, use cases, and benefits. If you're an IT professional, data scientist, or part of a business grappling with data scalability and efficient storage solutions, this guide is for you.

What Is Object Storage?
Object storage is a data storage architecture that manages data as discrete units called objects. Unlike traditional file systems that organize data in hierarchical structures with files and directories, object storage uses a flat address space. This flat structure eliminates the complexities of navigating nested folders, allowing for unlimited scalability and simplified data management.
In object storage systems, data is stored in a single repository that can be distributed across multiple storage nodes and geographic locations. This approach is particularly effective for handling vast amounts of unstructured data, such as multimedia files, backups, archives, and large datasets generated from Internet of Things (IoT) devices or big data applications.
By treating data as objects, organizations can easily scale storage capacities, enhance metadata usage for better data organization, and improve access speeds, making object storage an essential component in modern cloud computing and data-intensive environments.
Object Storage Examples
Understanding object storage becomes clearer when exploring scenarios where it is effectively used:
- Cloud-based photo libraries. When users upload images to a cloud service, each photo is stored as an object along with metadata like date taken, location, and camera settings. This method allows for easy organization, searching, and sharing of images across devices.
- Streaming media platforms. Videos and music files on streaming services are stored as objects. Each media file, accompanied by metadata such as title, genre, and artist, can be efficiently delivered to users worldwide, supporting features like personalized recommendations.
- Enterprise backup systems. Organizations back up critical data, including documents, databases, and system logs, by storing them as objects. The metadata enables quick retrieval and restoration of specific data sets when needed, enhancing disaster recovery.
- Big data analytics. Massive datasets generated from sources like IoT sensors, social media feeds, and transaction records are stored as objects. Object storage's scalability enables companies to manage petabytes of data required for advanced data analytics and machine learning applications.
- Content delivery networks (CDNs). Websites and applications store static assets such as images, stylesheets, and scripts as objects. CDNs cache these objects globally, reducing latency and improving load times for users accessing the content from different geographical locations.
- Email and messaging services. Each email or message is stored as an object, containing the message content and metadata like sender, recipient, and timestamps. This structure facilitates efficient searching, archiving, and compliance monitoring.
- Scientific research data repositories. Researchers store experimental data - such as genomic sequences, astronomical observations, or climate models - as objects. The rich metadata allows for detailed descriptions, making it easier to search, share, and collaborate on data across the scientific community.
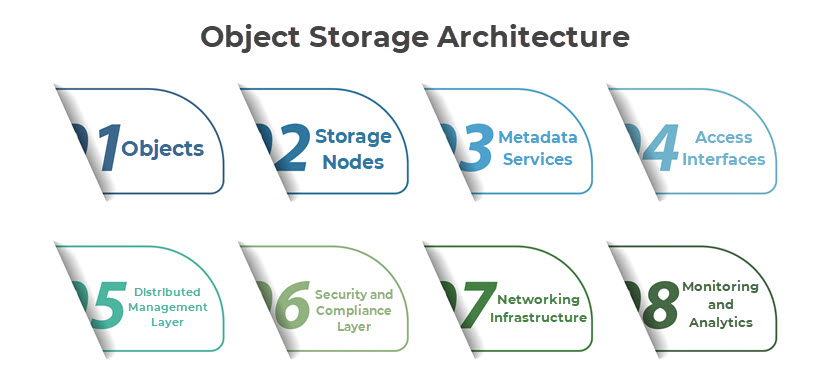
Object Storage Architecture
The architecture of object storage contains several components, each playing a vital role in the storage and retrieval of data.
Objects
At the core of the architecture are the objects themselves. Each object contains:
- Data payload. The actual binary data or content that needs to be stored. This data can range from small text files to large multimedia files like videos and images.
- System metadata. The system generates information, including object size, creation timestamp, and access permissions. This metadata is essential for the system's internal operations and security protocols.
- User-defined metadata. Customizable key-value pairs provided by the user or application. This allows for flexible categorization, indexing, and detailed descriptions of the data, enabling efficient search and retrieval.
- Unique identifier (object ID). A globally unique identifier, often a universally unique identifier (UUID) or a content-addressable hash (like SHA-256), used to locate and access the object within the storage system without concern for its physical location.
Storage Nodes
Storage nodes are the physical or virtual servers responsible for storing the objects. They perform several critical functions:
- Data storage management. Handle read and write operations to the underlying storage media, which may include hard disk drives (HDDs), solid-state drives (SSDs), or hybrid configurations.
- Data redundancy and replication. Implement replication strategies or erasure coding to store multiple copies or parity information of objects across different nodes or data centers. This step ensures data durability and availability even in the event of hardware failures.
- Data integrity verification. Use checksums and cyclic redundancy checks (CRCs) to detect and correct data corruption during storage or transmission.
- Tiered storage management. Support different classes of storage (e.g., hot, warm, cold tiers) to optimize performance and cost based on data access patterns.
Metadata Services
Metadata services manage the metadata associated with each object and are crucial for efficient data retrieval and management:
- Metadata indexing. Create and maintain indexes of metadata attributes to enable fast search and retrieval operations based on metadata queries.
- Distributed metadata management. Ensure that metadata is consistently updated and synchronized across the storage cluster, often using distributed databases or consensus algorithms like Paxos or Raft.
- Policy enforcement. Apply data management policies, including data retention rules, versioning, lifecycle management, and compliance requirements, based on metadata attributes.
Access Interfaces
Access interfaces provide the means for applications and users to interact with the object storage system:
- RESTful APIs. Standard HTTP/HTTPS-based APIs that support operations like PUT (upload), GET (download), DELETE (remove), and HEAD (metadata retrieval). These APIs enable platform-independent access over the internet.
- Native protocols support. Compatibility with protocols like Amazon S3 API, OpenStack Swift API, or proprietary interfaces, allowing seamless integration with existing applications and services.
- SDKs and libraries. Language-specific Software Development Kits (SDKs) for programming languages such as Java, Python, C++, and Go, facilitating the development of custom applications that interact with the storage system.
- Command-line tools and GUIs. Utilities and graphical user interfaces for administrators and users to perform tasks like uploading data, managing metadata, and monitoring system performance.
Distributed Management Layer
The distributed management layer oversees the coordination and operation of the entire object storage system:
- Cluster management. Manages node membership, configuration settings, and health monitoring of storage nodes. It ensures that all nodes are functioning correctly and efficiently.
- Load balancing. Distributes incoming requests and workloads evenly across storage nodes to optimize performance and prevent any single node from becoming a bottleneck.
- Scalability and elasticity. Allows for the seamless addition or removal of storage nodes without service interruption. Techniques like consistent hashing or distributed hash tables (DHTs) are used to redistribute data and workloads efficiently.
- Fault tolerance and recovery. Detects node failures and initiates data rebalancing or recovery procedures to maintain data availability and integrity. This step may involve redirecting traffic, regenerating lost data from redundancy schemes, or reallocating resources.
Security and Compliance Layer
Security is a critical aspect of object storage architecture:
- Authentication and authorization. Implements security protocols such as OAuth 2.0, LDAP, or integration with Active Directory to control access to objects and APIs. Role-based access control (RBAC) is often used to assign permissions.
- Encryption. Provides options for server-side encryption (data at rest) and client-side encryption (data in transit) using industry-standard algorithms like AES-256. The provider or the customer can manage encryption keys.
- Auditing and logging. Records access logs, system events, and administrative actions for compliance auditing, security monitoring, and troubleshooting purposes.
- Compliance support. Ensures the storage system meets regulatory standards such as GDPR, HIPAA, or PCI DSS by enforcing data residency, retention policies, access controls, and providing necessary audit trails.
Networking Infrastructure
The networking component connects all parts of the object storage system:
- High-speed networking. Uses technologies like 10/25/40/100 Gigabit Ethernet or InfiniBand to ensure low-latency and high-throughput data transfer between nodes and to clients.
- Software-defined networking (SDN). Uses network virtualization and programmable networking to optimize data paths, manage network resources efficiently, and improve scalability.
- Data transfer optimization. Implements techniques like TCP/IP tuning, jumbo frames, remote direct memory access (RDMA), or RDMA over converged Ethernet (RoCE) for enhanced performance, especially in high-performance computing environments.
- Network security. Incorporates firewalls, virtual private networks (VPNs), and intrusion detection systems to protect data during transmission.
Monitoring and Analytics
Monitoring tools and analytics are essential for maintaining optimal performance:
- Performance monitoring. Tracks key metrics such as IOPS (input/output operations per second), latency, throughput, and capacity utilization to identify bottlenecks and optimize resources.
- Health checks. Continuously monitors the health of hardware components, network connections, and software services to address issues preemptively.
- Alerting and notifications. Configures alerts for critical events, such as node failures, capacity thresholds, or security breaches, to enable rapid response.
- Analytics and reporting. Provides insights through dashboards and reports on usage patterns, performance trends, and forecasting for capacity planning.
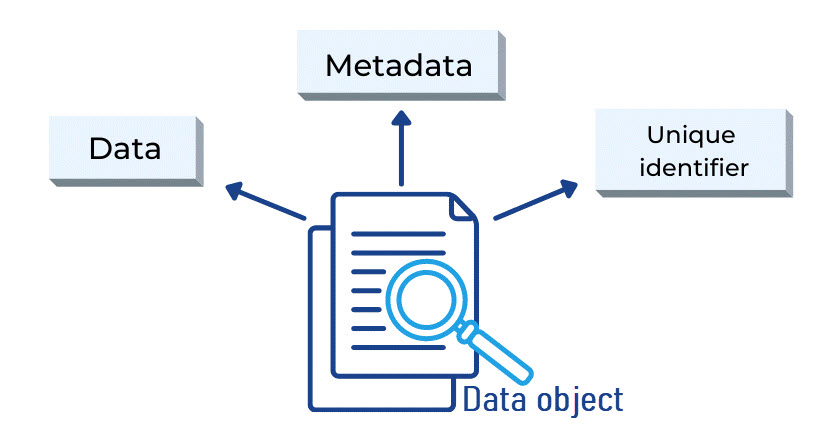
How Does Object Storage Work?
Object storage operates by managing data as independent units within a flat, non-hierarchical system. When data is uploaded, it is encapsulated with its metadata and assigned a unique identifier, enabling the system to retrieve the object without relying on traditional directory structures.
This flat architecture allows for seamless horizontal scaling, as objects can be distributed across numerous storage nodes in different locations. The rich metadata associated with each object enhances data management, allowing for efficient searching and retrieval based on various attributes. Access is typically provided through web-based APIs, making it easy to integrate with cloud services and applications.
By decoupling data from the underlying hardware and eliminating the limitations of hierarchical file systems, object storage provides a flexible and scalable solution for handling vast amounts of unstructured data.
What Is Object Storage Used For?
Object storage is used for applications that require managing large volumes of unstructured data with high scalability and accessibility. It forms the backbone of cloud storage services, enabling providers to offer scalable data storage accessible over the internet to users worldwide.
In big data analytics, object storage accommodates massive datasets necessary for processing and extracting insights, supporting applications in machine learning and IoT data analysis. The media and entertainment industry leverages it to store and deliver large multimedia files efficiently. For backup and archiving solutions, object storage offers durable, cost-effective, long-term data retention, ensuring data integrity and compliance with regulatory requirements.
Additionally, it supports the storage and management of data generated by IoT devices, facilitating real-time analytics and monitoring. Its versatility and scalability make object storage an ideal choice for any scenario that demands efficient management of unstructured data at scale.

Object Storage Benefits
Object storage offers several key advantages that make it an attractive solution for modern data storage needs.
- Scalability. Organizations can expand storage capacity by adding nodes without disrupting services. This horizontal scaling eliminates hierarchical directory structures, removing bottlenecks and enabling efficient handling of vast data volumes. Systems can seamlessly scale as data demands increase, accommodating exponential growth.
- Cost-effectiveness. By utilizing commodity hardware, object storage reduces capital expenditures compared to proprietary systems. As storage needs grow, economies of scale lower the cost per unit of storage. Efficient resource utilization ensures that storage space is used effectively, minimizing waste and optimizing costs.
- Durability and reliability. Object storage systems store multiple copies of data across different nodes or locations, ensuring data integrity and availability even in the event of hardware failures. Self-healing capabilities automatically detect and repair data corruption or node failures, maintaining system robustness without manual intervention.
- Rich metadata capabilities. Customizable metadata allows for detailed descriptions of data, facilitating advanced search queries based on metadata attributes. These factors also support automated data management policies, including lifecycle management and compliance enforcement, making it easier to meet regulatory requirements and streamline data governance.
- Accessibility. Object storage provides global data availability via API access, allowing users to access data across different geographic regions. Its device-independent nature means users can access data from any device capable of making API calls, enhancing flexibility and user convenience.
What Are the Cons of Object Storage?
Despite its advantages, object storage has limitations that organizations should consider.
- Latency. Object storage is not ideal for high-performance applications requiring low-latency data access, such as real-time analytics or transactional databases. The access methods and distributed architecture can introduce delays that negatively affect application performance.
- Compatibility with legacy applications. Older software designed to work with block or file storage systems may not function efficiently with object storage. This incompatibility might demand significant modifications to existing applications or the use of additional middleware, increasing complexity and costs.
- Object immutability. Since objects are typically immutable, modifying data often requires creating a new object rather than updating the existing one. This requirement leads to increased storage consumption and may complicate data management, especially for applications that frequently update data.
- Eventual consistency models. Changes made to data may not be immediately reflected across all nodes, which can cause issues for applications that require immediate consistency. This delay can lead to outdated information that affects data accuracy and reliability.
- Lack of transaction support. Features like atomicity and transactional integrity are not inherently provided, making it less suitable for applications that require complex transaction management and strict consistency guarantees. This limitation impacts the reliability of operations where transactional consistency is critical.

Object Storage vs. Block Storage vs. File Storage
Here is a table comparing the three storage types across key attributes:
| Attribute | Object Storage | Block storage | File storage |
| Architecture | Stores data as objects in a flat address space with unique identifiers. Eliminates hierarchical structures. | Divides data into fixed-size blocks managed by the operating system. Blocks are assembled into files by the file system. | Organizes data in a hierarchical file system with directories and files structured in a tree-like architecture. |
| Access methods | Accessed via APIs over HTTP/HTTPS protocols. Designed for web-based applications and cloud services. | Accessed at the block level by the operating system. Requires a dedicated connection like iSCSI or Fibre Channel. | Accessed via standard file system protocols such as NFS or SMB/CIFS. Mountable as a network drive or local file system. |
| Performance | Higher latency. Suitable for storing large amounts of unstructured data where speed is less critical. | Low latency. Ideal for high-performance applications like databases and transactional systems requiring fast read/write operations. | Moderate latency. Suitable for general-purpose file storage and sharing, but may not meet the high-performance demands of certain applications. |
| Scalability | Highly scalable. Can handle large volumes of data by adding more storage nodes horizontally. | The file system's architecture limits scalability. Performance degrades as the number of files and directories increases. | Scalability is limited by the size and capacity of the storage array or SAN. |
| Metadata support | Extensive and customizable metadata for each object, enhancing data retrieval and management capabilities. | Minimal metadata. Typically only includes block addresses with no additional descriptive information. | Basic metadata support such as file name, size, type, and timestamps. Less flexible than object storage but more than block storage. |
| Use cases | Ideal for unstructured data, large datasets, backups, archives, and cloud storage solutions. | Suitable for applications requiring high-performance storage like databases, virtual machines, and transactional systems. | Best for file sharing, content management systems, home directories, and workloads requiring hierarchical organization. |
Choosing the right storage solution is important for setting up your business on the right track. Read our in depth comparison of object and block storage to learn how they differ and when to use one over the other.
How Can phoenixNAP Help You?
At phoenixNAP, we offer advanced object storage solutions designed to meet the needs of modern businesses. Here's how we can assist you:
- Enterprise-grade object storage. phoenixNAP object storage provides scalable and secure storage engineered for high availability and durability.
- Global data accessibility. With multiple data center locations across the globe—including the United States, Europe, and the Asia-Pacific region—we ensure your data is always accessible where and when you need it. Our global network also reduces latency and improves performance, providing a seamless experience for users worldwide.
- Integration support. Our object storage is fully compatible with popular protocols like the Amazon S3 API, making it easy to integrate with your existing applications and workflows. Our dedicated team offers integration support to ensure a smooth and efficient transition.
- Flexible pricing models. We offer pricing models designed to optimize your storage expenses. Whether you prefer pay-as-you-go plans or customized packages, our solutions are tailored to fit your budget without compromising on performance or security.
- Robust security and compliance. Our object storage solutions come with strong security measures, including encryption at rest and in transit, access control mechanisms, and adherence to industry standards like PCI DSS, HIPAA, and SOC 2.
- 24/7 expert support. Our support team is available around the clock to assist with deployment, management, and troubleshooting. With extensive experience and a customer-first approach, we provide you with the resources and guidance needed to maximize the benefits of our object storage solutions.
Elevate Your Data Strategy with Object Storage
Object storage is a compelling solution for managing the explosion of unstructured data in today's technological ecosystem. Its scalability, cost-effectiveness, and flexibility make it an essential component of modern IT infrastructure. By adopting object storage, organizations unlock new possibilities in data management, analytics, and cloud computing, positioning themselves for future growth and innovation.



