
Choosing the right storage solution is important for setting up your business on the right track. This decision should be primarily based on the workload you expect to deal with. Object storage and block storage are popular solutions with certain benefits and limitations.
Read on to learn more about how they differ and when to use one over the other.

Object Storage vs. Block Storage: Overview of the Difference
Before examining each storage option individually, let’s take a look at some of the main differences between object storage and block storage.
| Point of Comparison | Object storage | Block storage |
|---|---|---|
| Data storage | Unique, identifiable, and distinct units called objects store data in a flat-file system. | Fixed-sized blocks store portions of the data in a hierarchical system and reassemble when needed. |
| Metadata | Unlimited, customizable contextual information. | Limited, basic information. |
| Cost | More cost-effective. | More expensive. |
| Scalability | Unlimited scalability. | Limited scalability. |
| Performance | Suitable for high volumes of unstructured data. Performs best with large files. | Best for transactional data and database storage. Performs best with files small in size. |
| Location | A centralized or geographically dispersed system that stores data on-premise, private, hybrid, or public cloud. | A centralized system that stores data on-premise or in a private cloud. Latency may become an issue if the application and the storage are geographically far apart. |
Data Storage
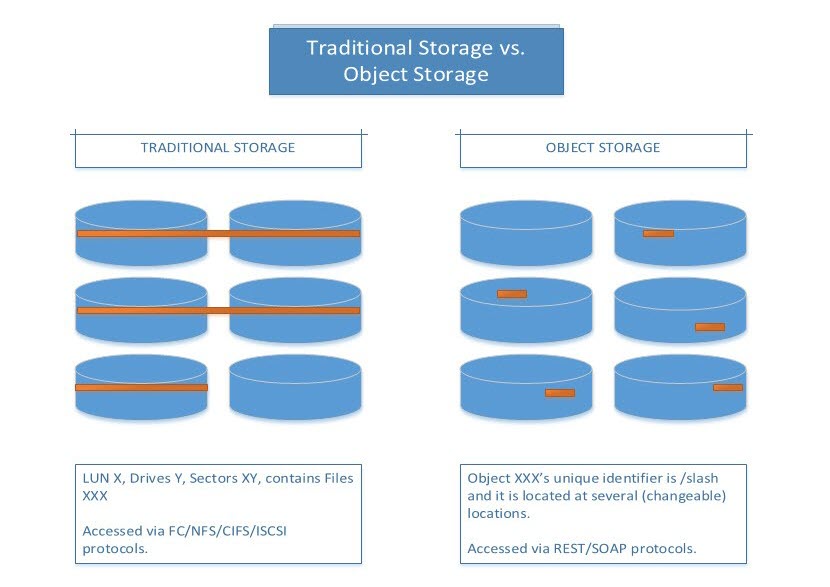
The biggest change from traditional block storage to object storage was modifying the way data is stored. Block storage involves splitting a file into data blocks, each containing portions of the information. The data blocks are stored in a hierarchical system on one or multiple drives and accessed via performance protocols.
In opposition, object storage stores files as modular units in a single repository (bucket) using a flat-file system. Each object represents a self-contained, identifiable, distinct unit that can be located at several (changeable) locations.
Metadata
The crucial difference between object storage and block storage lies in the amount of metadata that data units hold. Apart from basic information such as owner, size, and date of creation, object storage includes additional contextual information. As metadata is customizable and unlimited, the data is easily organized and managed to contribute to effective data analytics.
Cost
When it comes to cost, block storage is the more expensive storage solution. Since blocks are fixed in size, purchasing additional storage to scale out incurs extra expenses. For this reason, many organizations with high volumes of data opt for object storage.
Scalability
As the number of files and users increases, block storage becomes more complex, making it harder to locate a specific file. At some point, this hinders performance as the system reaches its file limit. Planning long-term capacities is more difficult with block storage. An organization might end up overpaying for idle resources or need further capacities sooner than anticipated.
On the other hand, thanks to its flat structure, object storage allows scaling out simply by adding new nodes to the structure.
Performance
Block storage provides better storage performance than its counterpart. This is mainly due to the way it stores units of data. Since data is split into subsequent data blocks, block storage allows modifying (or retrieving) only part of a file instead of the entire unit.
On the other hand, object storage requires rewriting the entire file because the data is not partitioned. Hence, block storage is mainly used for transactional data and databases, while object storage performs best when dealing with high volumes of unstructured data.
Note: Object storage is unsuitable for data sets where files are modified frequently. In such cases, there is no guarantee that a retrieve request returns the most recent version of the data.
Location
Object storage is a single system that spreads across several locations. Every object has its own unique identifier, and there is no need to know the location of the data to access it. Administration of data is conducted over an HTTP/S interface.
Block storage features a centralized system that stores data on-premises or in a private cloud. Knowing where a file is located is necessary to access it.
What is Object Storage?
Object storage is a storage method in which data is organized, managed, and manipulated as unique, identifiable, and distinct units called objects. It is quite different than the traditional approach and emerged due to the growing demand for a practical way to store large amounts of unstructured data.
Instead of a hierarchical file system, object storage has a flat file system for storing data. All objects are kept as self-contained units in a single-level repository called a bucket.
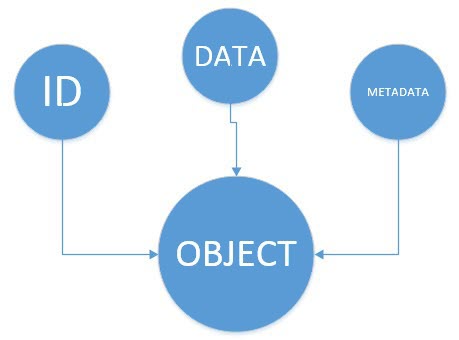
Each object consists of the data it stores, comprehensible metadata, and a unique identifier. The metadata provides contextual information about each object, while the identifier helps locate the object within a distributed system.
The main advantages of object storage are its scalability and the ability to store large collections of unstructured data. Thanks to its flat structure, this storage method provides unlimited scalability by adding new nodes to the cluster. Additionally, it can handle storing and retrieving high volumes of data in record times.
Note: To learn more about this data storage solution, check out What is Object Storage.
Object Storage Use Cases
Object storage is mainly used for:
- Storing big data. Object storage, due to its metadata capabilities, scalability, and robust API, works great for machine learning. Storing and accessing unstructured data is where object storage excels at.
- Creating backup copies and archives. Object storage is a reliable option for data sets that aren’t updated often. Users who are not leveraging a supported backup utility (Veeam, R1Soft) can leverage the S3 interface for their backups.
- Media and entertainment data storage. This storage solution excels at storing high volumes of images, graphics, video, or audio files. Most importantly, it makes them accessible to users anywhere in the world at lightning speed.
- Data storage with ransomware protection. Object storage creates a new version of the same file after each modification, allowing you to restore data in case of a ransomware attack.
- Storing personal medical files. Thanks to its built-in security and resilient replication, object storage is used for protecting personal medical data. Additionally, some object storage solutions are HIPAA-compliant by default, a critical factor when storing personal medical files.
- Hosting a Static Website. Object storage is a suitable environment for hosting a static website that scales automatically to meet traffic demands.
Note: A static website presents the same content to all visitors. There is no content-personalization based on cookies. A static website does not use server-side scripting.
What is Block Storage?
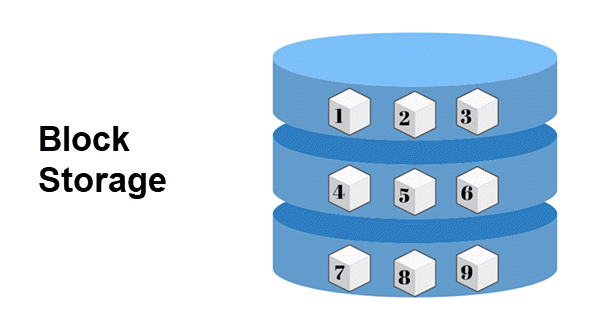
Block storage is a form of data storage that splits data into fixed-sized units called blocks. Each block stores a portion of the data and has a unique identifier used to reassemble it when needed. These unique addresses can also store blocks separately across multiple machines.
Data blocks are allocated and managed using software, separated from the storage device. When retrieving a file, you send a block request through a performance protocol, such as iSCSI or FCoE. Once the required addresses are found, the blocks are organized to form a complete file.
Unlike objects, data blocks have limited metadata. While including basic specifications (the size, owner, and creation date), traditional storage doesn’t store additional information about the data. Therefore, block storage needs more time to locate the required data in metadata-critical operations, which inevitably affects the overall performance.
Still, block storage generally has low latency and is great for apps that require a high number of input/output operations. It has great performance scores and speed compared to other solutions. A factor that can influence performance is where the data is being stored. The system retrieves files at varying speeds, depending on whether the application and data are stored locally or farther apart. Traditional block storage, however, is slow in retrieving unstructured data.
Block Storage Use Cases
Block storage is primarily used for:
- Database storage. Object storage provides consistent I/O performance, low latency, redundancy, and fault tolerance, making it ideal for resource-intensive database applications.
- Storing data for applications that require service-side processing. Applications that require server-side processing (such as Java, PHP, and .NET) require using block storage.
- RAID volumes. RAID arrays are a common use case for block storage, as this storage solution stores data on multiple disks organized by stripping or mirroring. Therefore, you can employ block storage as RAID volumes.
- Container storage. Block storage helps with managing data stored in Docker or Kubernetes containers by separating the data from the lifecycle of the container or pod and providing fixed-sized persistent storage.
- Storing mission-critical applications. Block storage is a common choice for applications that deal with mission-critical data. Its excellent performance and low latency ensure the app functions continuously as required.
Deciding Between Object Storage and Block Storage
Both storage solutions have distinct advantages depending on the use case. Object storage is ideal for large volumes of unstructured data, offering durability, scalability, and advanced metadata management. Block storage delivers low latency and high performance, making it suitable for structured databases, VM volumes, and intensive read/write workloads. phoenixNAP cloud object storage lets you store and process exabytes of data with native S3 support, enabling easy management and scalability across multiple geographic locations.



