
Data centers are built with different levels of reliability for a good reason. Some businesses and industries, such as healthcare, ecommerce, and finance, require continuous availability with minimal downtime. Others, such as small independent retailers, can withstand operating offline longer without negatively impacting their bottom line.
Regardless of its level, data center reliability affects your revenue, productivity, and customer satisfaction. To prevent financial and reputational damage, companies invest in redundant systems and resilient data center infrastructure.
This article explains the importance of data center reliability and how to achieve it. No matter the type of your business, as uptime challenges continue to grow, your data center is the backbone of your business continuity efforts.

What Is Data Center Reliability?
Data center reliability refers to the data center’s ability to operate without interruptions in case of an unplanned event. These events range from network and cooling system failures to natural disasters, power outages, human errors, and cyber attacks.
Cyber attacks are a frequent cause of data center operational failures. To learn more about cyber attacks and how to recognize them before they happen, read our article on types of cyberattacks.
The reliability of data centers is measured with the 9s method (also referred to as “five nines”). The 9s method shows the data center’s availability through uptime percentage during one year. More nines in the availability percentage show more data center redundancy and higher reliability, indicating less data center downtime.
You can calculate data center availability with the following formula:
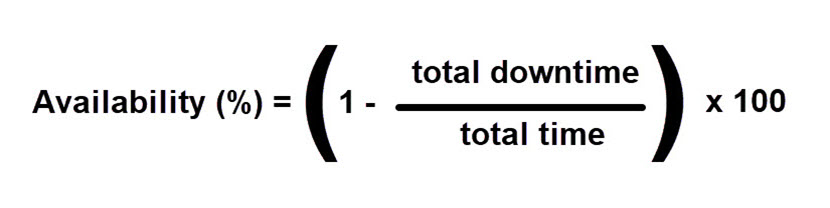
For example, imagine that a certain service of your data center was unavailable for an hour last year. One calendar year has 8760 hours, which means that your data center was available for approximately 99.98856% of the time:
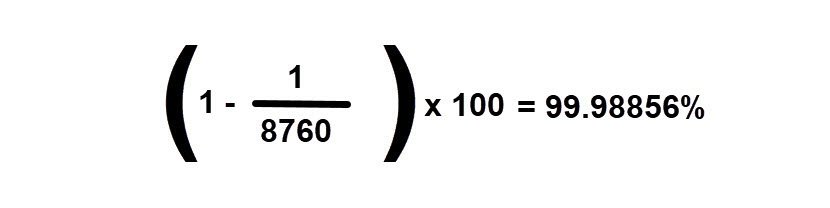
While the 3 nines in this example show a satisfactory level of data center availability, 5 nines represent “the golden standard” that all businesses aspire to for maximum uptime.
Reliability vs. Availability
Data center reliability and availability are two closely related concepts. Reliability shows how long a system can run without interruption. On the other hand, availability indicates how quickly a system can recover from disruptions.
Here is the table overview of their differences:
| Aspect | Reliability | Availability |
| Definition | The ability of a system to perform without failure over a certain time period. | The percentage of time a system is operational and accessible during a given period. |
| Focus | Measures frequency of failure. | Measures duration of uptime vs. downtime. |
| Key metric | Mean Time Between Failures (MTBF) | Uptime percentage or availability (%) |
| Concerned with | How often failures occur. | How long the system is available and performing despite failures. |
| Formula | MTBF = Total Operating Time / Number of Failures | Availability = (Total Time - Downtime) / Total Time × 100 |
| Includes recovery? | No, it assumes operation until failure. | Yes, it includes recovery time (MTTR) in downtime. |
| Improved by | Better component quality and fault prevention. | Redundancy, failover, faster disaster recovery. |
| Example | A server that runs continuously for 2 years before failing. | A server that fails monthly but is restored within 10 minutes each time. |
How Is Reliability Achieved in Data Centers?
Businesses with high data center reliability implement overlapping systems that ensure continuity. That way, if one part of a data center is down, others continue to function. The overlapping infrastructure minimizes the impact of disruptions, while the redundant systems work together to restore operations.
Let’s look at the various methods for achieving reliability in each layer of a data center.
1. Fault-Tolerant Architecture Design
Data center architecture plays a critical role in maximizing reliability. A robust design will ensure continuous operations even in the face of hardware failures, network disruptions, or unexpected system loads.
The core of a fault-tolerant architecture is workload distribution through clustering. Configure servers, storage systems, and application environments in clusters, where multiple nodes operate in parallel, to eliminate having a single point of failure (SPOF). When one node or component fails, the remaining nodes automatically take over. This is essential in mission-critical applications, databases, and virtualization platforms, where downtime can result in significant operational or financial losses.
In addition to clustering, implement high availability (HA) and load-balancing mechanisms. Load balancers distribute incoming traffic evenly across multiple servers, preventing performance bottlenecks and minimizing the risk of failures caused by overload. Active-active HA configurations allow all nodes to handle traffic simultaneously, with built-in redundancy to maintain operations if any node goes offline. In contrast, active-passive setups keep standby nodes ready to take over instantly when a failure occurs.
An essential component of data center reliability is geographic distribution through availability zones or secondary disaster recovery sites. This approach helps organizations safeguard their operations from localized disruptions such as natural disasters, power grid failures, regional cyber attacks, or loss of connectivity. Geographic distribution enhances fault tolerance, supports compliance with data sovereignty requirements, and provides flexibility for global services delivery.
With 15+ data centers and Network PoPs located across the globe, phoenixNAP provides you with SLA-backed uptime and superior connectivity, helping you strengthen your business presence in your target markets.
2. Cross-System Redundancy
Redundancy ensures that critical operations continue to function during outages and disruptions. Data center redundancy is achieved through:
- Power. Provide backup power supplies such as extra generators and UPSs (uninterruptible power supplies). Ideally, the data center should have access to multiple power sources (solar, battery storage, etc.).
- Cooling. Redundant HVAC systems and in-row cooling units maintain optimal temperatures in data centers. Additionally, more sophisticated monitoring systems detect changes in humidity and temperature before malfunctions occur.
- Network. Ensure network connectivity through multiple switches, routers, and ISPs in case of path failure. Implement border gateway protocol (BGP) to automatically redirect traffic to alternative paths.
- Storage. Utilize multiple hard drives or SSDs to prevent data loss and service disruptions due to data corruption. If a storage part is compromised, the redundant array of independent disks (RAID) retrieves healthy data.
For even more reliability, distribute redundancy across multiple availability zones. If each zone contains separate systems, one zone prevents failures from spreading to other zones.
Learn about N+1 Redundancy, the standard redundancy strategy employed in IT and data center architecture.
3. Strict Maintenance and Monitoring
Continuous monitoring and maintenance of data centers help administrators detect system failures at the earliest stages. Admins conduct routine inspections of components such as servers, cooling systems, and network devices to detect patterns. These patterns show system availability and signal possibilities for interruptions.
Data center infrastructure management (DCIM) platforms detect anomalies in network performance, equipment cooling, and security in real time. These tools continuously analyze environmental conditions, energy consumption, equipment utilization, and network performance, triggering automated alerts when thresholds are exceeded or anomalies are detected.
Administrators also combine DCIM and incident response plans to ensure that deviations from baseline performance are addressed immediately. Proactive monitoring, combined with predictive analytics and coordinated response protocols, minimizes downtime, extends the lifespan of equipment, and reinforces overall data center reliability.
4. Disaster Recovery Management
Disaster recovery provides solutions for quickly restoring regular operations in case of a data center failure. DR ensures minimal downtime in case of natural disasters or cyber attacks through the following methods:
- Geographic distribution. Having data centers in multiple locations ensures minimal disruptions in case one of the facilities is compromised.
- Data replication. Data backups in different forms (hard drives, SSDs) keep operations running despite data leaks or corruption.
- Automated failover mechanisms. Failover systems automatically switch to a different redundant component when the primary one is offline.
phoenixNAP’s Disaster-Recovery-as-a-Service (DRaaS) safeguards your business-critical workloads, giving you peace of mind and enabling you to resume operations in minutes following a disaster.
5. High-Quality Hardware and Critical Components
When acquiring hardware components for a data center, ensure that a vendor is reliable by examining their certifications and reputation. Look for organizations with industry-recognized certifications such as ISO 9001 (Quality Management Systems), ISO/IEC 27001 (Information Security Management), and compliance with hardware reliability standards like MIL-STD-810 or Telcordia GR-63 for environmental resilience. A vendor’s track record, product testing methodology, failure rate statistics, and reputation within the industry are key indicators of reliability.
Want access to cutting edge hardware but find the price of enterprise grade technology cost-prohibitive? Explore our Hardware-as-a-Service (HaaS) portfolio and lease the hardware you need without breaking the bank.
Data Center Reliability Assessment
Data center reliability assessment analyzes the data center’s resilience to disruptions. This analysis involves several steps, including:
- Defining the scope. First, determine whether the assessment will focus on one or multiple facilities. Also, decide if you want to analyze a specific subsystem (power, cooling, etc.) or the whole center.
- Deciding on the objectives. Define the purpose of the assessment, such as detecting vulnerabilities, ensuring compliance, or preparing for expansion.
- Conducting the assessment. Evaluate data center redundancy, equipment performance, and bandwidth capacity. Focus on power and cooling distribution and system backup capabilities.
- Analyzing monitoring procedures. Inspect the frequency of maintenance schedules. Also, review if incident response plans are up to date and effective against common threats.
- Performing risk analysis. Identify vulnerabilities and potential failure points before they are affected by outside threats. Focus on bottlenecks that slow down your system and single points of failure.
- Testing reliability. Perform penetration tests to determine how quickly the system recovers from failures and restore operations.
By systematically evaluating infrastructure redundancy, monitoring processes, and potential points of failure, organizations can implement targeted improvements to strengthen overall reliability. Regular assessments not only help maintain compliance with industry standards but also ensure that backup systems, failover mechanisms, and response procedures function as intended under real-world conditions.
Choosing a Reliable Data Center
When choosing a data center, keep in mind your business needs, budget, and expansion potential. Here are the key considerations when searching for a reliable data center:
- Uptime history. Check the data center’s service level agreement (SLA) for its uptime track record. Aim for at least 99.99% uptime with strict penalties in case of downtime.
- Redundancy and fault tolerance. Search for systems rated N (baseline redundancy requirement) for non-critical operations. N+1 refers to moderate downtime, while 2N redundancy indicates a fully redundant system. Highly critical environments, such as finance and healthcare, should aim for 2N+1 redundancy with enhanced fault tolerance.
- Compliance standards. Reliable data centers hold compliance certifications such as GDPR, HIPAA, and PCI DSS. ISO 22301 indicates business continuity, while ISO/IEC 27001 is a certificate of information security.
- Physical security. Data centers protect servers against physical threats and environmental disasters. Check for on-site measures, such as CCTV monitoring, biometric controls, and 24/7 guarding of facilities. As for environmental controls, data centers implement fire extinguishing, temperature control, and water leak prevention.
- Geographic accessibility. Choose a data center provider with multiple data center locations to ensure business continuity. If one facility experiences an outage, the center automatically transfers data and operations to another location.
- Monitoring and support. Reliable data centers offer 24/7 monitoring and round-the-clock technical support. Effective incident detection and response are crucial for high uptime and continuous operations.
phoenixNAP offers highly redundant data center infrastructure for your business needs. Our bare metal servers and colocations are marked 2N for redundancy and compliant with SOC 2. pNAP data centers are flexible and specifically designed to handle highly critical workloads.
Downtime Is No Longer an Option
Data center reliability is the foundation of business continuity. In a landscape where even brief outages can lead to significant financial loss and reputational damage, ensuring continuous operations is no longer optional – it’s a competitive necessity. Modern businesses depend on data centers with built-in redundancy, fault-tolerant architecture, and proactive monitoring to mitigate risks and maintain service availability. By partnering with providers that prioritize high availability, rigorous infrastructure standards, and rapid incident response, organizations can safeguard critical data and maintain operations even in the face of disruptions.



